AI智能体最近火得一塌糊涂——从简单的问答机器人到能编排多步骤工作流的复杂应用,确实展现出了惊人的潜力。但用过的人心里都明白:这玩意儿表现极其不稳定,有时候能完美解决问题,有时候又犯一些低级错误,让人哭笑不得。
传统的改进思路是微调模型(Fine-tuning),但这套方案有几个致命的问题:成本高得离谱,需要海量计算资源和标注数据;技术门槛极高,得有机器学习专业背景才能上手;泛化能力差,一个任务训好了换个任务就抓瞎;更新起来更是麻烦得要命,模型权重一变,整个部署和验证流程都得重来一遍。
就在大家一筹莫展的时候,微软开源了一个革命性的项目——SkillOpt,它提出了一种全新的思路:不碰模型权重,只优化智能体的"技能文档"。
一句话说清楚:什么是SkillOpt?
SkillOpt是微软研究院最新开源的一个训练框架,它把训练神经网络的那套成熟方法论,完美地移植到了AI智能体的技能优化上。
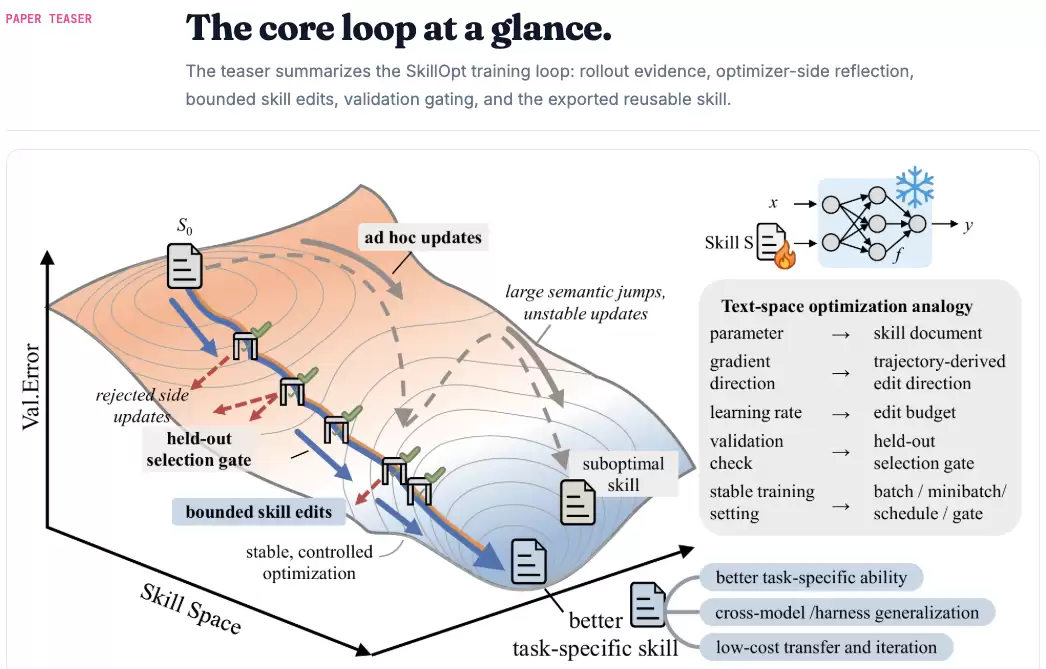
核心就一句话:像训练神经网络一样训练智能体技能,但完全不需要修改模型权重。
什么意思呢?传统的神经网络训练有epoch(轮次)、batch size(批次大小)、learning rate(学习率)、validation(验证)这些概念。SkillOpt把这些概念全部用到了智能体技能训练中:
神经网络训练 | SkillOpt 技能训练 |
|---|---|
调整权重参数 | 优化 Markdown 技能文档 |
Epoch(轮次) | 多轮迭代优化技能 |
Batch size(批次) | 每轮处理的任务数量 |
Learning rate(学习率) | 技能更新的激进程度 |
Validation(验证) | 在验证集上测试技能效果 |
这个项目的论文刚刚发布在arXiv上,编号2605.23904,由微软研究院联合上海交大、同济大学、复旦大学的15位研究者共同完成。GitHub仓库短短几天就收获了3100关注。
核心原理:技能即文档,训练即优化
SkillOpt的核心假设非常大胆:智能体的能力主要取决于它的"技能文档",而不是模型本身。什么是技能文档?就是那些告诉智能体怎么完成任务的Markdown文件。
比如一个搜索问答技能文档可能长这样:
# 搜索问答技能
## 任务描述
根据提供的文档内容回答问题。
## 工作流程
1. 仔细阅读文档,提取关键信息
2. 分析问题,确定需要哪些信息
3. 在文档中定位答案
4. 给出准确、简洁的回答
## 注意事项
- 如果文档中没有相关信息,明确说明
- 不要编造文档中没有的内容
- 保持回答简洁,不要过度展开
SkillOpt的做法是把这个技能文档当成可训练的"参数",然后通过类似神经网络训练的流程来优化它:
- 从一个基础技能文档开始
- 在训练集上测试当前技能的表现
- 分析错误案例,找出技能文档的问题
- 用另一个LLM(优化器)来改进技能文档
- 在验证集上验证改进效果
- 重复这个过程,直到技能收敛
整个过程中,目标模型的权重完全不会被修改,所有的改进都发生在技能文档这个外部文本上。
技术架构:双模型协作
SkillOpt使用两个不同的模型协作完成训练,这个设计非常巧妙。
目标模型(Target Model)
这是实际执行任务的模型,它的权重完全不会被修改。可以是任何支持API调用的LLM,比如GPT-4、Claude,甚至是本地部署的通义千问。
优化器模型(Optimizer Model)
这是负责分析和改进技能文档的模型,通常是一个更强的模型。它的任务是从执行结果中学习,提出对技能文档的改进建议。
完整的训练流程
- Rollout(执行):目标模型用当前技能文档在训练任务上执行,记录完整的执行轨迹和得分
- Reflect(反思):优化器模型分析成功和失败的案例,找出可复用的流程和需要修正的错误
- Edit(编辑):生成结构化的添加、删除、替换操作,在文本学习率预算下合并和排序
- Gate(验证):候选技能只有在验证集上性能严格提升时才会被接受
这个架构的好处太多了:目标模型可以是任何支持API调用的LLM,不需要模型权重访问权限;部署时零额外成本,只需要一个几百到几千token的Markdown文件;技能文档还可以跨模型、跨执行环境迁移。
核心亮点
- 完全不碰模型权重:SkillOpt完美避开了修改权重可能导致的问题,所有的优化都发生在外部文本上。
- 系统化的训练控制:把深度学习训练的整套方法论都搬过来了。
- 支持多种主流模型:支持
Azure OpenAI、OpenAI 直接调用、Anthropic Claude、通义千问(本地 vLLM 部署)等。 - 自带可视化WebUI:附带了一个基于Gradio的Web监控面板,可以直观地查看训练状态、技能快照、每步的改进效果等。
- 内置多种基准测试:项目已经内置了6个不同类型的基准测试,覆盖了问答、具身智能、文档理解、数学推理、代码生成等多个领域,可完成各种不同类型的任务。
惊人的实验结果
SkillOpt的实验结果可以用"碾压"来形容。
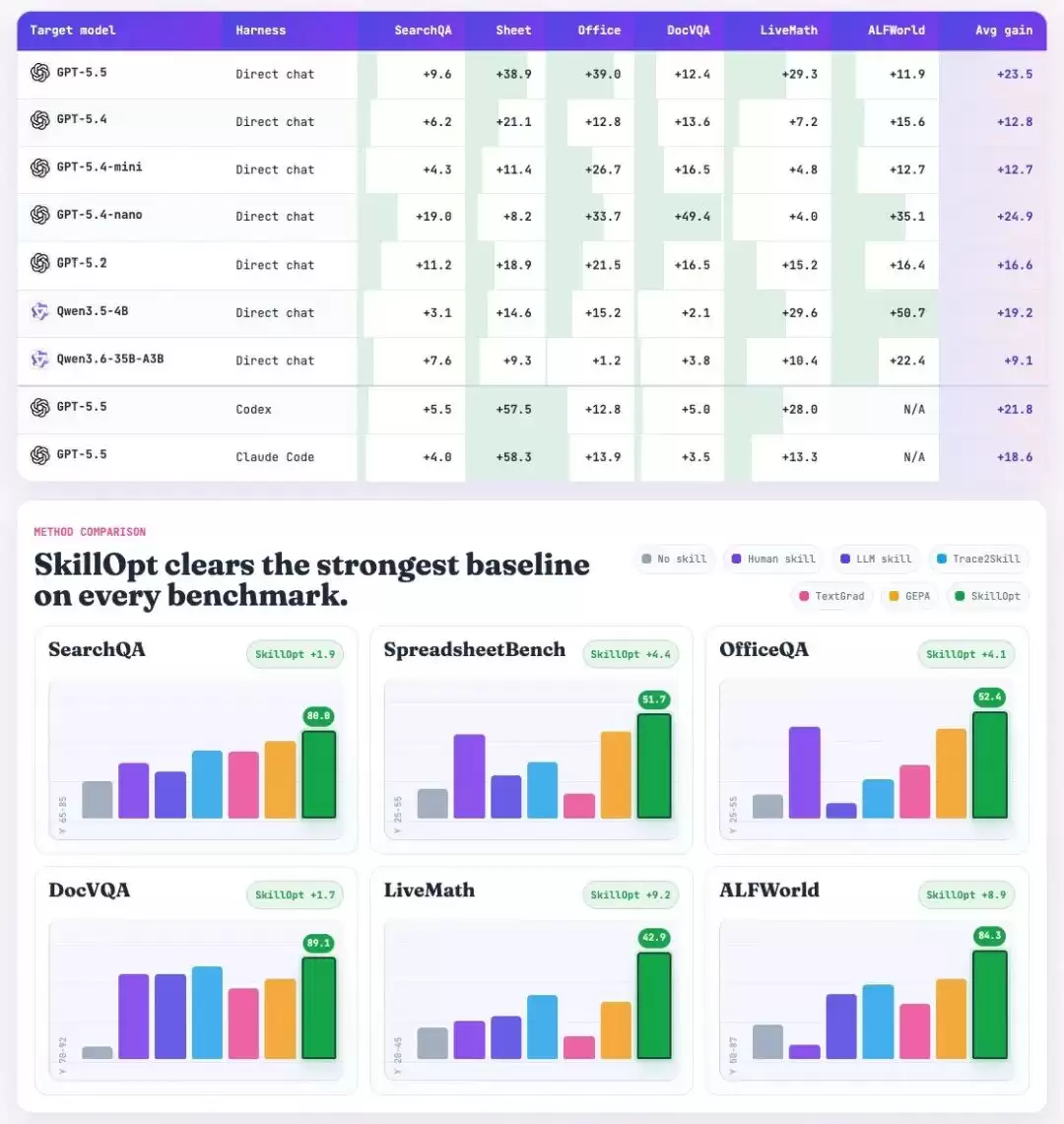
论文中测试了7个目标模型、6个基准测试、3个执行环境,总共52个(模型×基准×环境)组合,SkillOpt在所有52个组合中都取得了最佳或并列最佳的成绩!
一些具体的数据:
- 在GPT-5.5上,直接聊天模式的平均准确率提升了23.5个百分点
- 在Codex智能体循环中,提升了24.8个百分点
- 在Claude Code中,提升了19.1个百分点
- 在ALFWorld任务上,GPT-5.4-mini的准确率从70.9%提升到了85.8%,只用了4步!
而且,优化后的技能文档还具有很强的迁移能力:可以跨模型规模迁移,可以在Codex和Claude Code执行环境之间迁移,还可以迁移到相近的数学基准测试上,无需进一步优化。
快速上手
首先需要Python 3.10+:
git clone https://github.com/microsoft/SkillOpt.git
cd SkillOpt
pip install -e .
# 如果需要 ALFWorld 基准测试
pip install -e ".[alfworld]"
alfworld-download
配置API凭证
支持多种LLM提供商:
Azure OpenAI(推荐):
export AZURE_OPENAI_ENDPOINT="https://your-resource.openai.azure.com/"
export AZURE_OPENAI_API_KEY="your-key"
OpenAI直接调用:
export OPENAI_API_KEY="sk-..."
Anthropic Claude:
export ANTHROPIC_API_KEY="sk-ant-..."
通义千问(本地vLLM):
export QWEN_CHAT_BASE_URL="https://localhost:8000/v1"
export QWEN_CHAT_MODEL="Qwen/Qwen3.5-4B"
数据准备
SkillOpt期望数据按以下结构组织:
data/my_split/
├── train/items.json
├── val/items.json
└── test/items.json
每个JSON文件是一个任务数组,具体格式取决于基准测试。比如SearchQA的格式:
[
{
"id": "unique_item_id",
"question": "Who wrote the novel ...",
"context": "[DOC] relevant passage text ...",
"answers": ["expected answer"]
}
]
开始训练
最小示例,在SearchQA上训练:
python scripts/train.py --config configs/searchqa/default.yaml --split_dir /path/to/your/searchqa_split --azure_openai_endpoint https://your-resource.openai.azure.com/ --optimizer_model gpt-5.5 --target_model gpt-5.5
主要的命令行参数:
参数 | 说明 | 示例 |
|---|---|---|
--config | 基准测试配置YAML | configs/searchqa/default.yaml |
--split_dir | 数据分割目录路径 | /path/to/split |
--azure_openai_endpoint | Azure OpenAI端点URL | https://your-resource.openai.azure.com/ |
--optimizer_model | 优化器模型部署名称 | gpt-5.5 |
--target_model | 目标模型部署名称 | gpt-5.5 |
--num_epochs | 训练轮次数 | 4 |
--batch_size | 每步批次大小 | 40 |
--workers | 并行执行工作进程数 | 8 |
--out_root | 输出目录 | outputs/my_run |
评估已训练的技能
只评估,不训练:
# 只在测试集上评估
python scripts/eval_only.py --config configs/searchqa/default.yaml --skill outputs/my_run/best_skill.md --split valid_unseen --split_dir /path/to/searchqa_split --azure_openai_endpoint https://your-resource.openai.azure.com/
# 在所有分割上评估(训练+验证+测试)
python scripts/eval_only.py --config configs/searchqa/default.yaml --skill outputs/my_run/best_skill.md --split all --split_dir /path/to/searchqa_split --azure_openai_endpoint https://your-resource.openai.azure.com/
输出结构
每次运行会生成结构化的输出目录:
outputs//
├── config.json # 扁平化的运行时配置
├── history.json # 每步的训练历史
├── runtime_state.json # 恢复检查点
├── best_skill.md # 最佳验证技能文档
├── skills/skill_vXXXX.md # 每步的技能快照
├── steps/step_XXXX/ # 每步的产物(补丁、评估)
├── slow_update/epoch_XX/ # 慢更新日志
└── meta_skill/epoch_XX/ # 元技能日志
重新运行相同命令会自动从最后完成的步骤恢复。
启动WebUI
启动监控面板(可选):
pip install -e ".[webui]"
python -m skillopt_webui.app
还可以创建公共分享链接:
python -m skillopt_webui.app --share
最后想说的
SkillOpt是一个真正革命性的项目,它把深度学习训练的成熟方法论,完美地移植到了智能体技能优化上,同时完全避免了修改模型权重带来的各种问题。而且它支持多种主流模型,自带可视化WebUI,内置丰富的基准测试,上手门槛很低。如果你正在研究智能体,或者想要优化你的智能体应用,SkillOpt值得一试!
项目地址:https://github.com/microsoft/SkillOpt




