最近,北京大学发布了一份关于DeepSeek-R1及类强推理模型开发的最新深度解读报告,迅速引发了技术圈的广泛关注与讨论。这份材料系统性地剖析了当前大模型在迈向“强推理”能力过程中所面临的核心问题与创新解决方案。今天,我们将深入梳理这份报告中的精华内容,帮助您快速把握其中揭示的关键趋势与技术细节。


DeepSeek-R1及类强推理模型开发解读
报告开篇即点明核心议题:当前大语言模型的对齐与可扩展监督研究正处在一个关键转折点。其中,DeepSeek-R1、Kimi 1.5这类“强推理模型”的涌现,标志着行业焦点正从单纯追求“规模”与“知识”储备,转向着力提升模型的“思考”与“推理”能力。这一转变不仅是技术的迭代,更可能深刻重塑AI应用的底层范式。
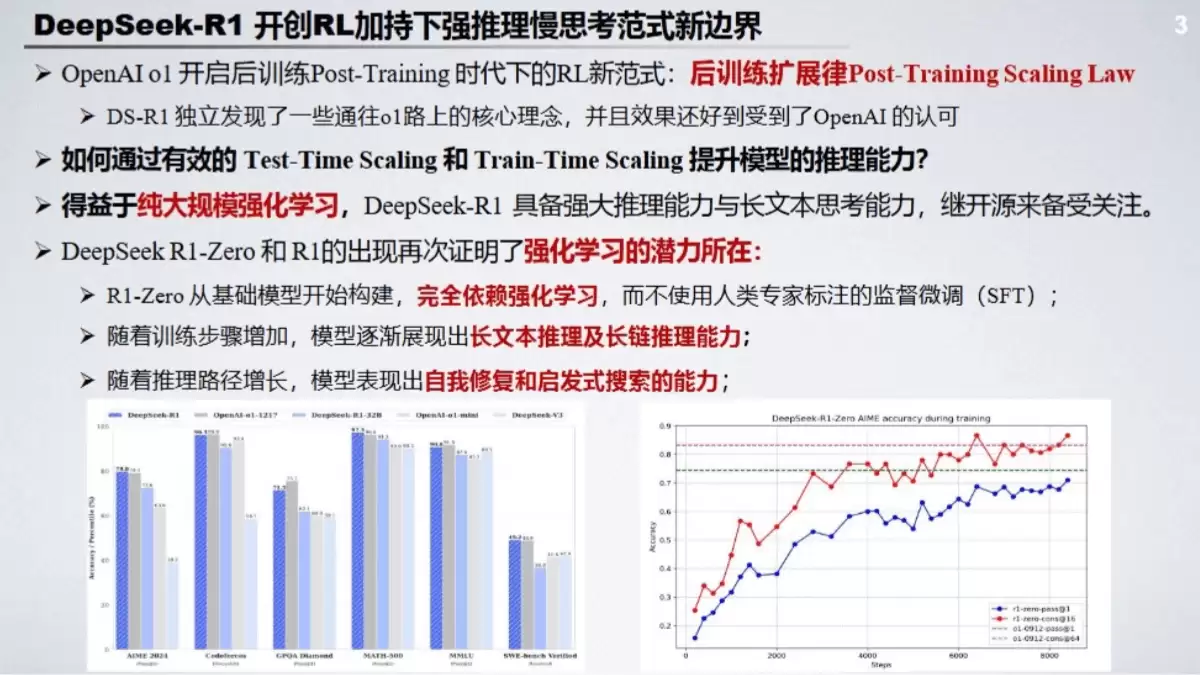
DeepSeek-R1开创RL加持下强推理慢思考范式新边界
那么,DeepSeek-R1究竟取得了哪些突破?报告将其核心创新概括为:在强化学习的强力驱动下,开创了“强推理慢思考”的全新范式。简而言之,它不再追求快速给出答案,而是鼓励模型像人类一样“慢下来思考”,通过多步骤、链式的推理过程逐步逼近最终结论。
这种范式带来的效果十分显著。在数学推理、代码生成、知识密集型问答以及长文本依赖任务中,DeepSeek-R1均展现出超越传统模型的卓越表现。报告还将其与OpenAI的o1系列模型进行对比,揭示了不同技术路线在实现“慢思考”方面的异同。
DeepSeek-R1技术剖析
只看结果远远不够,还需要深入理解其内在技术。报告对DeepSeek-R1的技术架构进行了层层拆解。
DeepSeek-R1 Zero
首先是一个引人注目的概念:DeepSeek-R1 Zero。这是一个无需经过传统监督微调、完全由强化学习驱动的强推理模型。它的出现挑战了固有认知——在没有高质量SFT数据的前提下,能否训练出具备强推理能力的模型?DeepSeek-R1 Zero通过独特的奖励建模和训练模板给出了肯定的回答,这为数据稀缺场景下的模型开发提供了全新的思路。
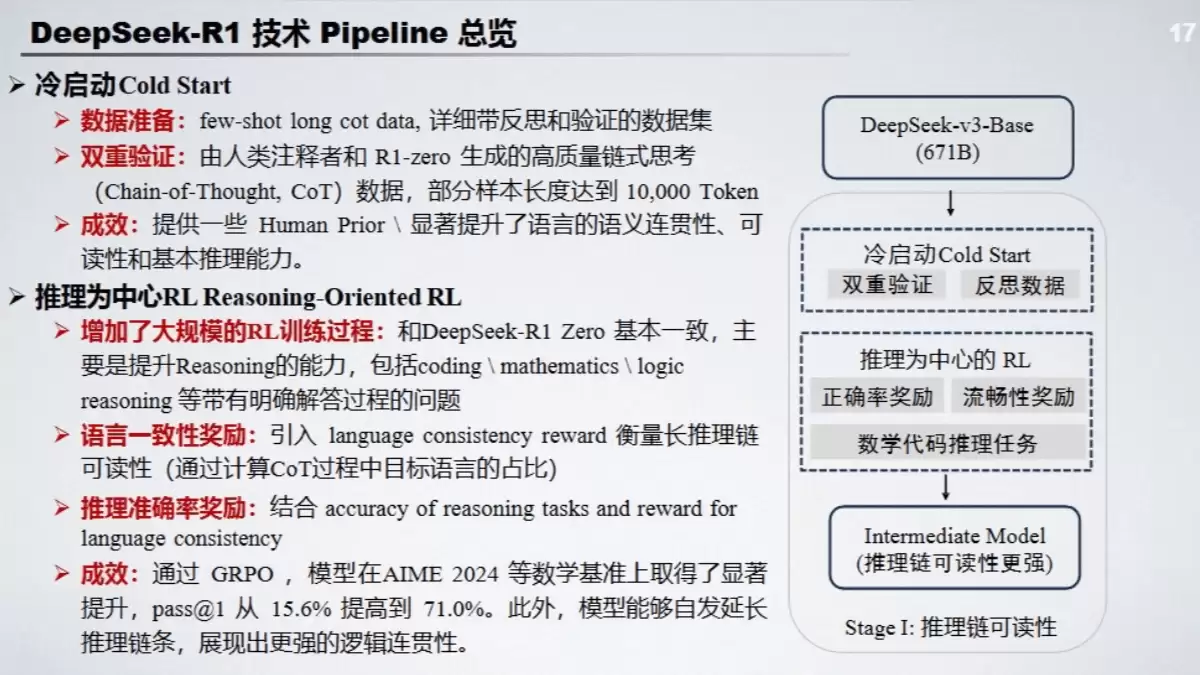
DeepSeek-R1技术Pipeline总览
当然,完整的DeepSeek-R1技术管线更为精密。报告梳理了从DeepSeek-V3 Base模型出发,到最终成型的多阶段训练流程。这一过程并非一蹴而就,而是包含了冷启动、以推理为中心的强化学习、拒绝采样以及全领域SFT等多个关键环节。每个环节如同精密齿轮相互咬合,共同推动模型推理能力的跃升。
DeepSeek-R1背后的Insights & Takeaways
通读整个技术剖析部分,可以提炼出几个极具价值的洞察:纯强化学习路径已被证明是开发深度推理能力的一条可行大道;多阶段、差异化的训练策略比单一训练更为有效;而“以推理为中心”的RL训练目标设计,以及像GRPO这样的算法创新,真正释放了强化学习在大规模模型训练中的潜力。
DeepSeek-R1社会及经济效益
技术的价值最终要落地到实际应用。报告还展望了DeepSeek-R1这类模型可能带来的社会与经济影响。最直接的,是它开辟了一条通往低成本、高质量语言模型的路径,这对降低AI应用门槛意义重大。
在应用层面,强推理能力意味着模型能在垂直领域(如科研、金融、法律)进行更深度的分析,也能在横向(如多轮对话、复杂规划)上实现更自然的拓展。资本市场对此类技术突破向来敏感,它很可能催化新一轮的资源优化与市场激活,为高效创新注入新的动能。

技术对比探讨
任何技术都不是孤立存在的。报告将DeepSeek-R1的RL路径与其他主流技术思路进行了横向对比,这场“华山论剑”十分精彩。
STaR-based Methods vs. RL-based Methods
一边是基于STaR(通过推理自举推理)的方法,另一边则是以DeepSeek-R1为代表的基于强化学习的方法。两者都在追求“强推理”,但哲学不同:STaR更像是一种从数据中自我提炼的“归纳”,而RL则是通过奖励信号进行定向塑造的“驯化”。报告客观分析了二者在路径稳定性、效果上限等方面的优缺点。
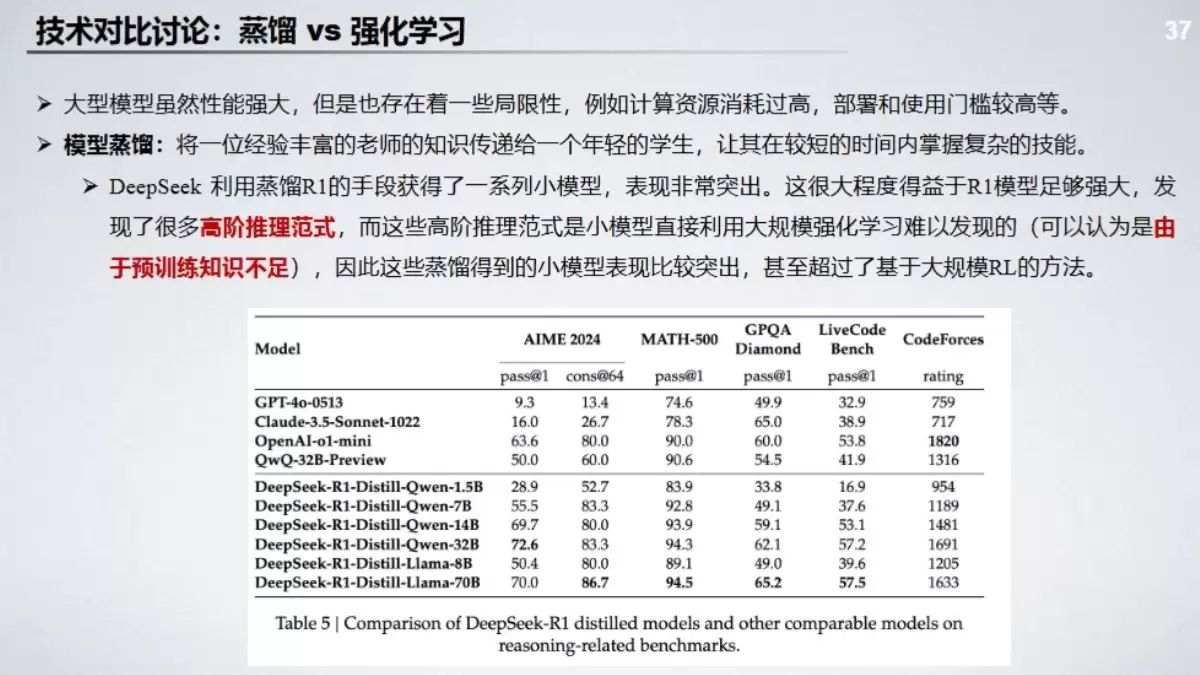
蒸馏vs.强化学习驱动
另一个经典对决是“蒸馏”与“强化学习”。用大模型教导小模型(蒸馏),与用奖励机制引导模型(RL),哪种方式更能提升强推理能力?答案可能因场景而异。蒸馏效率高,但可能触及天花板;RL潜力大,但训练复杂。报告探讨了这两种策略的协同与平衡之道。
PRM & MCTS的作用
报告还深入探讨了PRM(偏好奖励模型)和MCTS(蒙特卡洛树搜索)这两项在强化学习,尤其是游戏AI中成熟的技术,在强推理模型中的应用。它们能帮助模型进行更精细的奖励判断和更前瞻的推理搜索,但如何将其无缝融入语言模型的训练流程,仍面临不小的工程与算法挑战。
从文本模态到多模态
未来的强推理一定不会局限于文本。报告设想了模型从文本模态向视觉、语音等多模态扩展的前景。真正的挑战在于“模态穿透”——模型能否进行跨模态的联合推理?例如,根据图表和文字描述共同推导出一个结论。这将是推理边界的一次重大扩展。

其他讨论:Over-Thinking等
甚至,报告还讨论了一些有趣且实际的问题,例如“过度思考”。模型像人类一样“想太多”怎么办?这不仅可能导致效率低下,还可能陷入逻辑循环。因此,如何合理分配“测试时计算量”,在推理深度与效率之间取得平衡,成为一个需要精心设计的课题。
未来方向分析探讨
基于当前的突破,报告也为我们勾勒了未来的技术演进方向。
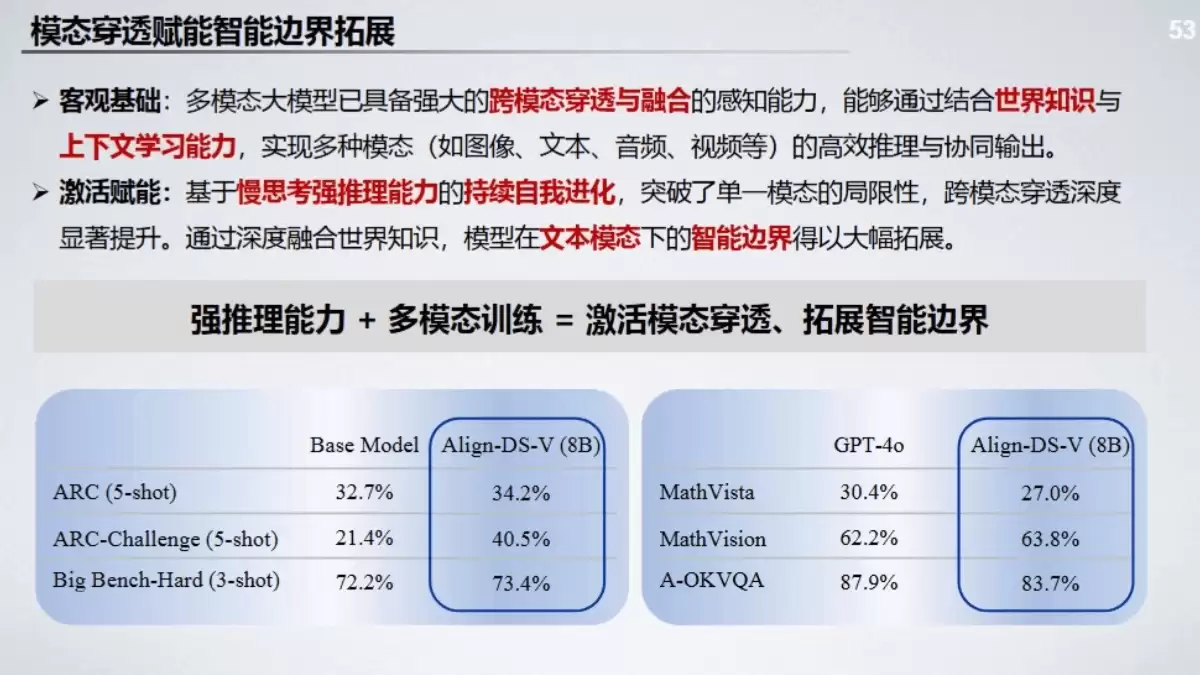
模态穿透赋能推理边界拓展:Align-DS-V
如前所述,多模态是必然趋势。像Align-DS-V这类旨在实现深度语义对齐的技术,将成为打通模态隔阂、赋能跨模态强推理的关键。
合成数据及Test-Time Scaling
数据始终是AI的燃料,但高质量标注数据终将枯竭。如何利用模型自身生成高质量合成数据,并利用“测试时缩放”技术动态调整推理资源,是突破数据再生产陷阱、持续提升模型性能的潜在钥匙。
强推理下的安全:形式化验证与审计对齐
能力越强,责任越大。当模型具备深度推理能力时,其决策过程更复杂,潜在风险也更隐蔽。因此,通过形式化验证等数学方法确保推理过程的可控,以及通过审计对齐技术确保模型的价值观与人类一致,将成为未来强推理模型安全落地的重中之重。

总而言之,这份解读报告为我们提供了一幅清晰的路线图。它不仅是在分析DeepSeek-R1这一个模型,更是透过它,揭示了整个大模型领域向“强推理”时代迈进的技术脉络、核心挑战与未来想象。对于关注AI前沿发展的从业者和研究者而言,其中的诸多细节与思考,无疑具有重要的参考价值。
```



