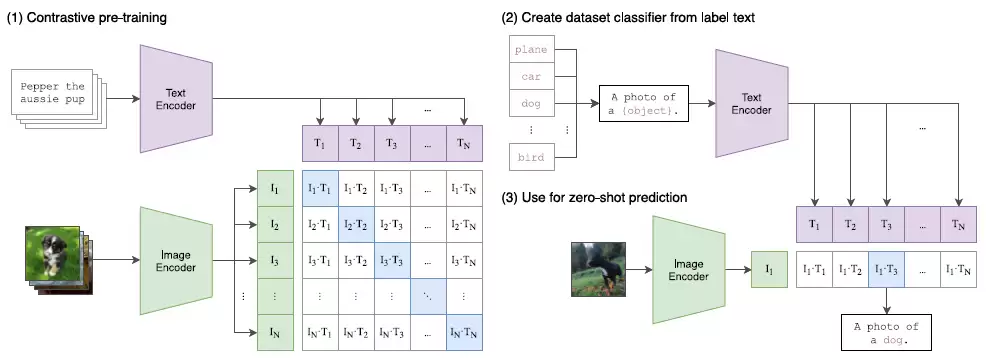
1. 概述
Vision Transformer 的核心思路其实很直接:把文本、图像、音频这些不同类型的数据,先处理成 Embedding(嵌入向量),然后丢给 Transformer 模型去训练。这样一来,模型就能学会同时理解和融合多种信息。CLIP 正是站在这个肩膀上,专门用来预测图像和文本之间的匹配程度。具体怎么做的?就是通过海量的图像-文本对进行学习,然后计算图像特征向量和文本特征向量之间的余弦相似度,用这个相似度来判定它们是不是一对儿。
2. 文本分词器
英文分词在这里是按字符来的,用的词表就是 ASCII 码,所以词表大小只有 256。
def tokenizer(text, encode=True, max_seq_length=32):
if encode:
out = chr(2) + text + chr(3) # 添加 SOT token 和 EOT token
out = out + chr(0)*(max_seq_length - len(out)) # 添加 Padding 字符
out = torch.tensor([ord(c) for c in out]) # 对文本进行编码
mask = (out>0).to(torch.int)
# mask 为什么需要形成方阵?
mask = mask.expand(max_seq_length, max_seq_length)
else:
# 将input_ids解码为text文本
out = "".join([chr(x) for x in text[1:text.index(0)-1]])
mask = None
return out, mask
2.1 为什么需要 padding 填充?
为了提升计算效率,训练数据一般都会分批并行处理。要让并行计算跑得起来,同一批数据必须形状一致,所以短的文本就需要填充到相同长度。
2.2 为什么需要 mask?
保证被填充的那些位置不会参与到实际计算中,避免它们干扰结果。
2.3 mask 的形状为什么是方阵?
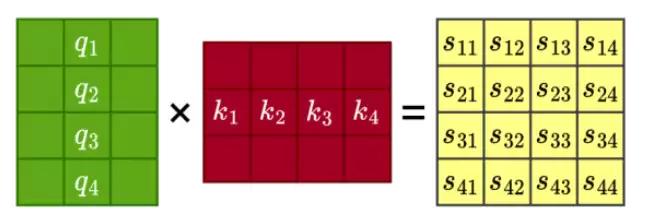
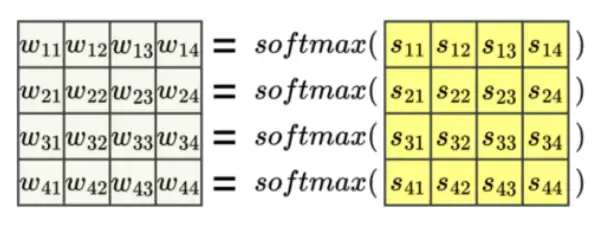
注意力机制在计算权重的时候,那些被 padding 的向量不应该贡献权重。举个例子,假如 q4 和 k4 都是 padding 出来的,那它们对应的位置就应该标记成负无穷,这样经过 softmax 之后权重几乎为零。参与 softmax 计算的输入是一个向量长度×向量长度的方阵,所以 mask 也必须跟着做成方阵。
3. 整理数据
这里用的是手写数字识别数据集,不过需要把它整理成图文对的形式。具体做法是把每个图像对应的标签转换成一段文本,比如手写数字 0 的标签,就变成文本 “An image of 0”。
class HandWritingMNIST(Dataset):
def __init__(self, train=True, captions_map=None):
self.dataset = MNIST(root="./datasets", train=train, download=True, transform=T.ToTensor())
self.captions = captions_map
def __len__(self):
return len(self.dataset)
def __getitem__(self, i):
img, target = self.dataset[i]
cap, mask = tokenizer(self.captions[target])
return img, target, cap, mask
4. 位置编码
位置编码的经典实现,就是让每个位置的嵌入带上它在序列中的位置信息。
class PositionalEncoding(nn.Module):
def __init__(self, d_model, max_seq_length):
super().__init__()
pe = torch.zeros(size=(max_seq_length, d_model))
pos = torch.arange(0, max_seq_length).unsqueeze(1)
_2i = torch.arange(0, d_model, 2)
div_term = torch.pow(10000, (_2i / d_model))
pe[:, 0::2] = torch.sin(pos / div_term)
if d_model % 2 == 1:
_2i1 = torch.arange(0, d_model-1, 2)
div_term = torch.pow(10000, (_2i1 / d_model))
pe[:, 1::2] = torch.cos(pos / div_term)
self.register_buffer("pe", pe)
def forward(self, x):
x = x + self.pe
return x
5. Encoder 模型
先实现单头注意力,再拼成多头,最后加上 MLP、层归一化和残差连接,就是一个标准的 Transformer Encoder 模块。
# 注意力头
class AttentionHead(nn.Module):
def __init__(self, d_model, head_size):
super().__init__()
self.head_size = head_size
self.query = nn.Linear(d_model, head_size)
self.key = nn.Linear(d_model, head_size)
self.value = nn.Linear(d_model, head_size)
def forward(self, x, mask):
Q = self.query(x)
K = self.key(x)
V = self.value(x)
attention = Q @ K.transpose(-2, -1)
attention = attention / (self.head_size ** 0.5)
if mask is not None:
attention = attention.masked_fill(mask == 0, float("-inf"))
attention = torch.softmax(attention, dim=-1)
attention = attention @ V
return attention
# 多注意头
class MultiHeadAttention(nn.Module):
def __init__(self, d_model, n_heads):
super().__init__()
self.head_size = d_model // n_heads
self.W_o = nn.Linear(d_model, d_model)
self.heads = nn.ModuleList([AttentionHead(d_model, self.head_size) for _ in range(n_heads)])
def forward(self, x):
out = torch.cat([head(x) for head in self.heads], dim=-1)
out = self.W_o(out)
return out
# 多注意头 + 全连接层 + 层归一化和残差链接
class TransformerEncoder(nn.Module):
def __init__(self, d_model, n_heads, r_mlp=4):
super().__init__()
self.d_model = d_model
self.n_heads = n_heads
self.ln1 = nn.LayerNorm(d_model)
self.mha = MultiHeadAttention(d_model, n_heads)
self.ln2 = nn.LayerNorm(d_model)
self.mlp = nn.Sequential(
nn.Linear(d_model, d_model * r_mlp),
nn.GELU(),
nn.Linear(d_model * r_mlp, d_model))
def forward(self, x):
out = x + self.mha(self.ln1(x))
out = out + self.mlp(self.ln2(out))
return out
6. 构建文本编码器
文本编码器就是一个常规的 Transformer Encoder,但输出时会把文本特征映射到图像和文本的联合向量空间中,方便后续用点积比较相似度。为了点积计算方便,这里还把嵌入向量做了归一化,让模长等于 1。
class TextEncoder(nn.Module):
def __init__(self, vocab_size, width, max_seq_length, n_heads, n_layers, emb_dim):
super().__init__()
self.max_seq_length = max_seq_length
self.encoder_embedding = nn.Embedding(vocab_size, width)
self.positional_embedding = PositionalEncoding(width, max_seq_length)
self.encoder = nn.ModuleList([TransformerEncoder(width, n_heads) for _ in range(n_layers)])
self.projection = nn.Linear(width, emb_dim, bias=False)
def forward(self, text, mask):
x = self.encoder_embedding(text)
x = self.positional_embedding(x)
for encoder_layer in self.encoder:
x = encoder_layer(x, mask=mask)
x = x[
torch.arange(text.shape[0]),
torch.sub(torch.sum(mask[:, 0], dim=1), 1)
]
if self.projection is not None:
x = self.projection(x)
x = x / torch.norm(x, dim=-1, keepdim=True)
return x
7. 构建图像编码器
图像编码器采用 ViT 的结构:先把图像切成 patches,通过卷积映射成嵌入序列,加上一个 class token,然后经过多个 Transformer Encoder 层,最后取出 class token 对应的向量,同样投影到联合空间并归一化。
class ImageEncoder(nn.Module):
def __init__(self, width, img_size, patch_size, n_channels, n_layers, n_heads, emb_dim):
super().__init__()
assert img_size[0] % patch_size[0] == 0 and img_size[1] % patch_size[1] == 0, "img_size必须能被patch_size整除"
assert width % n_heads == 0, "width必须能被n_heads整除"
self.n_patches = (img_size[0] * img_size[1]) // (patch_size[0] * patch_size[1])
self.max_seq_length = self.n_patches + 1
self.linear_project = nn.Conv2d(n_channels, width, kernel_size=patch_size, stride=patch_size)
self.cls_token = nn.Parameter(torch.randn(1, 1, width))
self.positional_embedding = PositionalEncoding(width, self.max_seq_length)
self.encoder = nn.ModuleList([TransformerEncoder(width, n_heads) for _ in range(n_layers)])
self.projection = nn.Linear(width, emb_dim, bias=False)
def forward(self, x):
x = self.linear_project(x)
x = x.flatten(2).transpose(1, 2)
x = torch.cat((self.cls_token.expand(x.size()[0], -1, -1), x), dim=1)
x = self.positional_embedding(x)
for encoder_layer in self.encoder:
x = encoder_layer(x)
x = x[:, 0, :]
if self.projection is not None:
x = self.projection(x)
x = x / torch.norm(x, dim=-1, keepdim=True)
return x
8. CLIP 模型
把图像编码器和文本编码器拼在一起,再加上一个可学习的温度参数,就构成了完整的 CLIP 模型。损失函数是对称的:从图像到文本和从文本到图像两个方向都计算交叉熵,然后取平均。
class CLIP(nn.Module):
def __init__(self, emb_dim, vit_width, img_size, patch_size, n_channels, vit_layers,
vit_heads, vocab_size, text_width, max_seq_length, text_heads, text_layers):
super().__init__()
self.image_encoder = ImageEncoder(vit_width, img_size, patch_size, n_channels, vit_layers, vit_heads, emb_dim)
self.text_encoder = TextEncoder(vocab_size, text_width, max_seq_length, text_heads, text_layers, emb_dim)
self.temperature = nn.Parameter(torch.ones([]) * np.log(1 / 0.07))
def forward(self, image, text, mask):
I_e = self.image_encoder(image) # [B, emb_dim]
T_e = self.text_encoder(text, mask=mask) # [B, emb_dim]
logits = (I_e @ T_e.transpose(-2, -1)) * torch.exp(self.temperature) # [B, B]
labels = torch.arange(logits.shape[0]).to(device)
loss_i = nn.functional.cross_entropy(logits.transpose(-2, -1), labels)
loss_t = nn.functional.cross_entropy(logits, labels)
loss = (loss_i + loss_t) / 2
return loss
9. 模型训练
这里用 MNIST 手写数字数据,把 label 映射成“An image of 数字”这样的文本。超参数设置后,训练 10 个 epoch,保存效果最好的模型。
# 基础配置
ROOT_DIR = Path(__file__).parent.parent
device = 'cuda' if torch.cuda.is_a vailable() else 'cpu'
log_dir = ROOT_DIR / 'logs'
# 超参数配置
emb_dim = 32
vit_width = 9
img_size = (28, 28)
patch_size = (14, 14)
n_channels = 1
vit_layers = 3
vit_heads = 3
vocab_size = 256
text_width = 32
max_seq_length = 32
text_heads = 8
text_layers = 4
lr = 1e-3
epochs = 10
batch_size = 128
# 图片 label 和文本对应关系
captions_dict = {
0: "An image of 0",
1: "An image of 1",
2: "An image of 2",
3: "An image of 3",
4: "An image of 4",
5: "An image of 5",
6: "An image of 6",
7: "An image of 7",
8: "An image of 8",
9: "An image of 9"
}
# 加载数据
train_set = HandWritingMNIST(train=True, captions_map=captions_dict)
test_set = HandWritingMNIST(train=False, captions_map=captions_dict)
train_loader = DataLoader(train_set, shuffle=True, batch_size=batch_size)
test_loader = DataLoader(test_set, shuffle=False, batch_size=batch_size)
# 模型初始化
model = CLIP(emb_dim, vit_width, img_size, patch_size, n_channels, vit_layers, vit_heads,
vocab_size, text_width, max_seq_length, text_heads, text_layers).to(device)
optimizer = optim.Adam(model.parameters(), lr=lr)
best_loss = np.inf
with SummaryWriter(log_dir=str(log_dir / time.strftime('%Y-%m-%d_%H-%M-%S'))) as writer:
for epoch in range(epochs):
for img, _, cap, mask in train_loader:
img, cap, mask = img.to(device), cap.to(device), mask.to(device)
loss = model(img, cap, mask)
optimizer.zero_grad()
loss.backward()
optimizer.step()
print(f"Epoch [{epoch + 1}/{epochs}], Batch Loss: {loss.item():.3f}")
if loss.item() <= best_loss:
best_loss = loss.item()
torch.sa ve(model.state_dict(), "./clip.pt")
print("模型已经保存...")
writer.add_scalar('loss', loss.item(), epoch + 1)
10. 模型验证
加载训练好的模型,在测试集上计算准确率。具体做法:先把测试集所有图像通过图像编码器得到特征,再把所有文本描述通过文本编码器得到特征,然后计算它们之间的相似度矩阵,取每一行最大值对应的类别作为预测结果。
# 加载最好的模型
model = CLIP(emb_dim, vit_width, img_size, patch_size, n_channels, vit_layers, vit_heads,
vocab_size, text_width, max_seq_length, text_heads, text_layers).to(device)
model.load_state_dict(torch.load("./clip.pt", map_location=device))
correct, total = 0, 0
caps = captions_dict.values()
caps_list = []
mask_list = []
for cap in caps:
cap_en, mask = tokenizer(cap, max_seq_length=32)
caps_list.append(cap_en.unsqueeze(0))
mask_list.append(mask.unsqueeze(0))
caps_tensor = torch.cat(caps_list, dim=0).to(device=device)
mask_tensor = torch.cat(mask_list, dim=0).to(device=device)
with torch.no_grad():
for img, target, _, _ in test_loader:
img, target = img.to(device), target.to(device)
image_features = model.image_encoder(img)
text_features = model.text_encoder(caps_tensor, mask=mask_tensor)
image_features /= image_features.norm(dim=-1, keepdim=True)
text_features /= text_features.norm(dim=-1, keepdim=True)
similarity = (100.0 * image_features @ text_features.T).softmax(dim=-1)
_, indices = torch.max(similarity, 1)
correct += (target == indices).sum()
total += target.size()[0]
print(f'\n预测准确率: {100 * correct // total} %')
11. 总结
通过这个简化版的 CLIP 模型,已经可以实现“文搜图”的功能。流程其实并不复杂:
① 用 CLIP 的图像编码器对数据库里所有图片抽取特征;
② 把这些特征存到向量数据库里;
③ 用户输入搜索文本后,用 CLIP 的文本编码器抽取文本特征;
④ 通过余弦相似度从向量数据库里找出最匹配的几张图片。
整个过程的核心就是两个编码器共同学习一个对齐的语义空间,剩下的就是工程上的检索优化了。




