简介
说到Eureka,它本质上就是Netflix基于REST设计的一款服务定位工具,专门用来在AWS云上实现中间层服务器的负载均衡和故障转移。这个核心组件,我们一般称为Eureka Server。当然,配套的还有一个Ja va客户端库,叫Eureka Client,能让开发者更方便地和Server打交道。有意思的是,客户端本身还内置了一个简单的轮询负载均衡器。而在Netflix那里,一个更复杂的负载均衡器会在Eureka的基础上,综合考虑流量、资源利用率、错误条件等多个维度来做加权负载均衡——这才是高弹性的关键。
我们先来看一张来自Netflix Eureka官方GitHub的架构图:
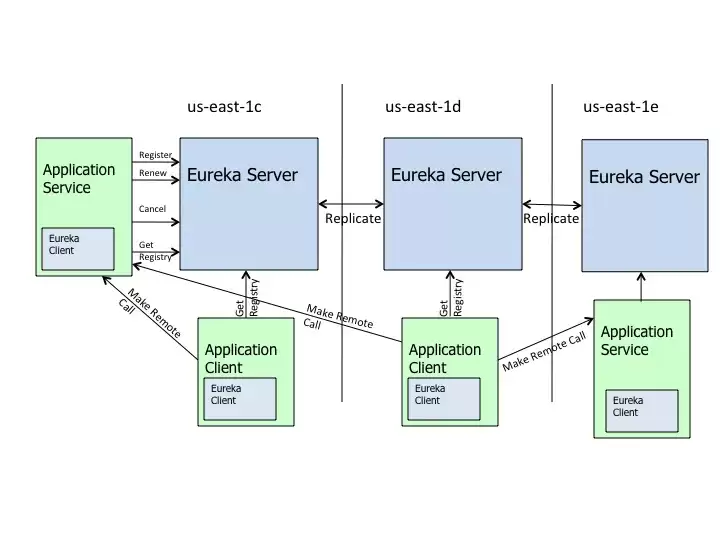
从这张图可以看得很清楚,体系里主要由两个角色构成:Eureka Server和Eureka Client。而Eureka Client又可以细分为Application Service(服务提供者)和Application Client(服务消费者)。每个区域都对应着一个Eureka集群,而且每个区域至少会部署一台Eureka Server来应对区域故障——万一某台服务器挂了,不至于全军覆没。
工作流程是这样的:Eureka Client启动后会在Server端完成注册,之后每隔30秒向Server发送一次心跳(也就是续约)。如果连续几次续约失败,Server大约会在90秒后把这个客户端从注册表中清理掉。注册信息和续约操作会在集群内部所有Eureka Server节点之间同步复制。任意区域的客户端都可以定时(也是每30秒一次)拉取注册表信息,然后服务消费者就可以根据这些信息,远程调用服务提供者来消费服务。
源码分析
在使用Spring Cloud时,Eureka Client的启用方式很简单:在启动类上加上@EnableDiscoveryClient注解就行了,背后就是Netflix提供的Eureka Client。我们就从这个注解入手,一步步往下看它的源码。
@EnableDiscoveryClient其实只是一个标记注解,核心实现是通过@Import(EnableDiscoveryClientImportSelector.class)来引入后续配置。定义上是一个接口DiscoveryClient,它规定了三个方法:
description():返回实现类的描述。getInstances(String serviceId):返回指定serviceId下的所有服务实例。getServices():返回全部已知的服务ID。
这个接口的实现结构图如下:

具体实现类有四个:EurekaDiscoveryClient(Eureka的真正实现)、CompositeDiscoveryClient(用于按顺序组合多个客户端)、NoopDiscoveryClient(已废弃,什么都不做)和SimpleDiscoveryClient(从配置中获取服务实例的简单实现)。
EurekaDiscoveryClient的代码很清晰,它内部持有一个EurekaClient实例,实际的发现逻辑都委托给它处理。而EurekaClient的真正实现类是DiscoveryClient。我们来看看它的构造方法:
@Inject DiscoveryClient(...) {
// 创建定时任务线程池,默认大小为2,分别用于心跳和缓存刷新
scheduler = Executors.newScheduledThreadPool(2, ...);
heartbeatExecutor = new ThreadPoolExecutor(...);
cacheRefreshExecutor = new ThreadPoolExecutor(...);
// 然后调用 initScheduledTasks() 启动这三个线程池
// 接着创建 instanceInfoReplicator 并调用 start() 方法
}
这个构造方法干了几件关键事:
- 创建了三个线程池:
scheduler(核心定时任务)、heartbeatExecutor(心跳检查,服务续约)、cacheRefreshExecutor(注册表刷新,服务获取)。 - 调用
initScheduledTasks(),把相应的任务提交到各个线程池中。 - 创建了一个
InstanceInfoReplicator(也是一个Runnable任务),并启动它,这个任务会被提交到scheduler线程池,既负责服务注册也负责后续的定期更新。
服务注册
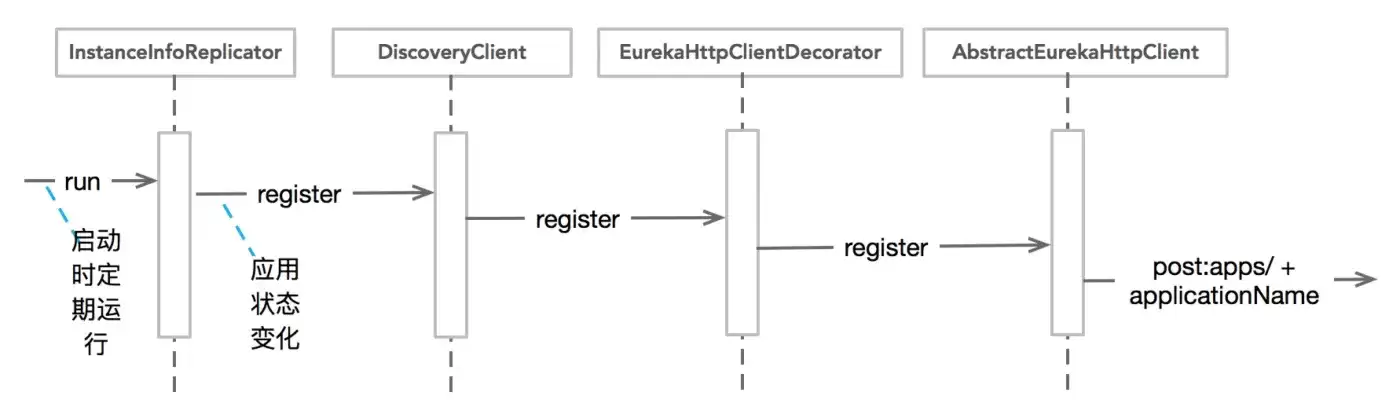
前面的initScheduledTasks()中启动了InstanceInfoReplicator,它的run()方法才是整个注册流程的起点:
public void run() {
discoveryClient.refreshInstanceInfo();
Long dirtyTimestamp = instanceInfo.isDirtyWithTime();
if (dirtyTimestamp != null) {
discoveryClient.register(); // 这里触发真正的注册请求
instanceInfo.unsetIsDirty(dirtyTimestamp);
}
// 定时重新调度自己
scheduler.schedule(this, replicationIntervalSeconds, TimeUnit.SECONDS);
}
调用链一直往下走,最终会落到AbstractJerseyEurekaHttpClient.register()方法,通过HTTP REST请求,把自身的InstanceInfo实例发送给Eureka Server:
public EurekaHttpResponse
整理一下整个服务注册流程,可以用一张流程图概括:
服务续约
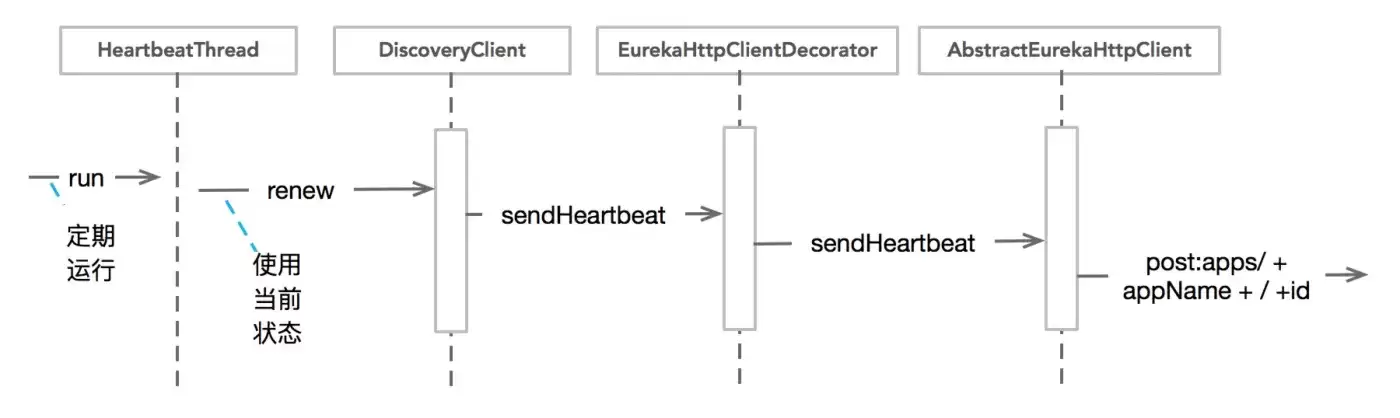
服务续约的逻辑跟注册非常像,核心是HeartbeatThread这个内部类:
private class HeartbeatThread implements Runnable {
public void run() {
if (renew()) {
lastSuccessfulHeartbeatTimestamp = System.currentTimeMillis();
}
}
}
boolean renew() {
// 通过 REST 发送心跳请求
// 如果返回 404,说明服务在 Server 端已经丢失,需要重新走一遍注册流程
if (httpResponse.getStatusCode() == 404) {
// 重新注册
boolean success = register();
return success;
}
return httpResponse.getStatusCode() == 200;
}
简单总结:Client每隔30秒向Server发送心跳,如果Server返回404(意味着服务不存在),就触发重新注册。服务续约流程如下图所示:
服务下线
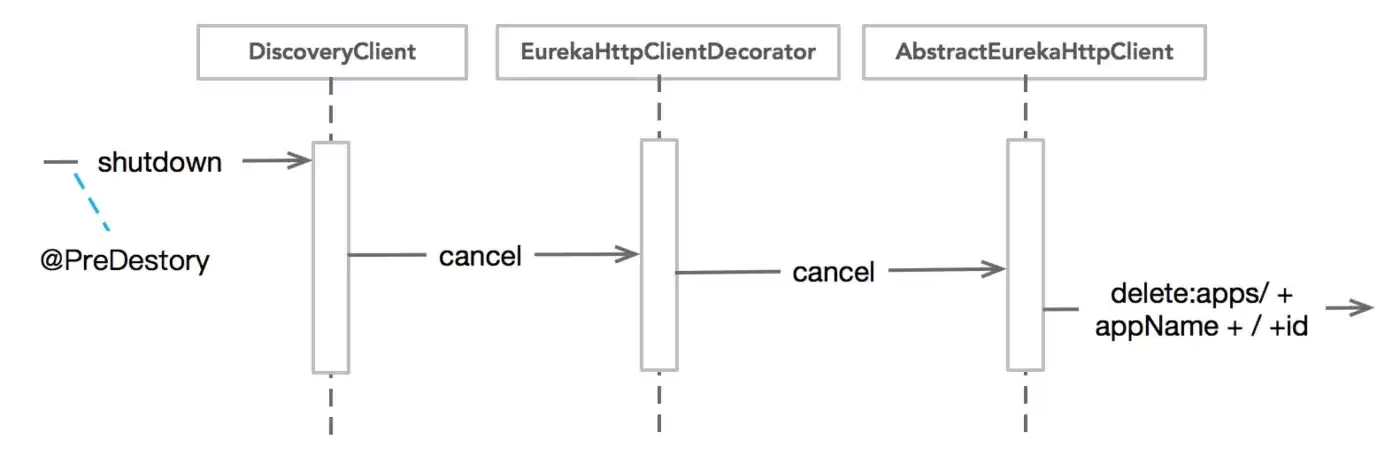
当服务需要正常关闭时,必须主动通知Server把自己踢掉,否则下游客户端可能会请求到已经挂掉的服务。shutdown()方法处理了这个逻辑:
- 先停止所有定时任务:
instanceInfoReplicator、heartbeatExecutor、cacheRefreshExecutor、scheduler。 - 将实例状态设置为
DOWN,告诉Server不再接收流量。 - 通过
eurekaTransport.registrationClient.cancel()发送服务下线请求。
流程如下图所示:
参考
https://github.com/Netflix/eureka/wiki
https://yeming.me/2016/12/01/eureka1/
https://blog.didispace.com/springcloud-sourcecode-eureka/
https://www.jianshu.com/p/71a8bdbf03f4




