在人形机器人领域,近期最受瞩目的消息莫过于智元自研的世界模型GE 2.0在WorldArena Track1赛道成功登顶,一举拿下第一名。先做个简单的科普:所谓“世界模型”,你可以把它理解为一个能够精准洞察物理世界运行规律的先进AI系统。只要机器人搭载了这一模型,就能提前预测杯子掉到地上会碎裂、水会自动流向低处、积木堆得太高容易倒塌——这些日常生活中的基本常识,它都能掌握。
智元团队此次参与评测的策略也颇具巧思——他们没有针对赛题做任何特殊优化,仅仅是输入榜单数据进行了基础微调。这就好比一位顶级棋手,没有研究对手的布局套路,仅凭扎实的基本功就赢得了比赛。最终结果:GE 2.0以绝对优势斩获榜首。
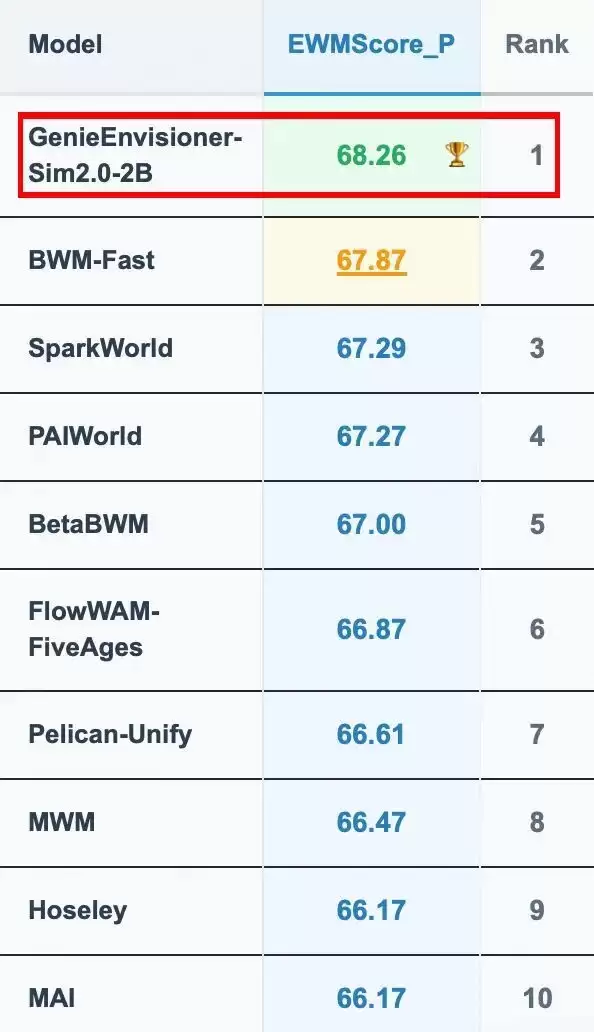
在功能层面,GE 2.0这次真正实现了“世界模拟器”技术能力的完整闭环——首次全面覆盖了长时序生成、多视角生成、本体状态生成、近实时推理以及奖励判别等核心环节。从技术深度来看,这绝非简单的修补或升级,而是一整套核心能力的系统性落地。

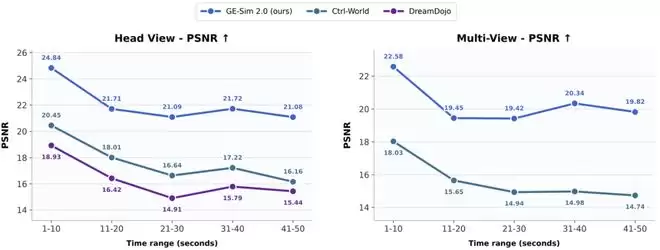
尤其值得关注的是长时序推理任务的表现。在这方面,GE 2.0的成果相当惊艳:即便是让它连续推演40到50秒的视频片段,产出的画面质量竟然比竞争对手模型在前10秒内的表现还要优异。画面质量随着推理时间推移而衰减的程度,远远低于行业内的基线方案——这一差距并非微乎其微。
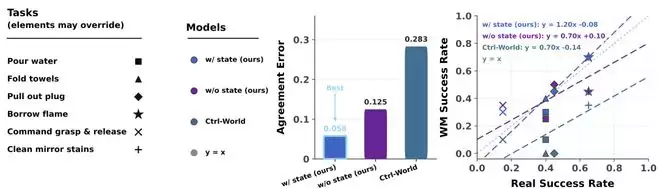
团队还完成了大量的闭环评测验证,结果明确显示GE 2.0在多项任务中与真实世界保持着高度相关性。这种相关性绝非“总体来看大致相当”的笼统统计结论——他们逐个进行了rollout结果的对比分析,并绘制了混淆矩阵以提供量化的佐证。这相当于对每一个案例都进行了对照验证,充分证明GE 2.0作为策略评测器,其可靠性是经得起推敲的。
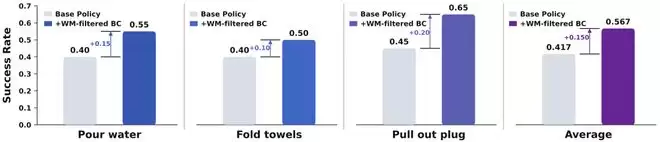
还有一个值得单独强调的亮点:在奖励模型的加持下,GE 2.0能够自动筛选闭环评测中的rollout流程,将那些真正高质量的产出数据回流给策略模型。实验结果表明,这一机制在多项任务中都显著提升了策略模型的性能——这才是世界模型实现真正落地应用的核心价值所在。
最后补充一个背景信息:此次同台竞技的对手每一位都实力强劲——英伟达的新模型DreamDojo、清华与斯坦福联合推出的Ctrl-World团队,都是行业顶级选手。然而GE 2.0仅凭一个20亿参数的轻量化模型,就成功超越了英伟达、微软等公司那些参数规模动辄数百亿的旗舰模型。这恰恰印证了行业内的一个共识:在人形机器人应用场景中,轻量化模型的适配能力丝毫不逊色于那些依赖庞大参数堆砌的大模型。




