2025年,AI智能体的发展进入快车道,但一个棘手的问题也随之浮现:当智能体需要接入的工具越来越多,模型上下文窗口里的那点空间,到底还够不够用?这背后隐藏着一个被称为“MCP工具税”的现象——工具本身的定义说明,正在悄悄吃掉宝贵的上下文资源,导致智能体处理能力大幅受限。
先看一组数据。Anthropic在2025年11月发布的一份报告揭示,在一个包含5台MCP服务器、共34个工具的Hermes部署场景中,平均每回合的提示符消耗达到45000个tokens。令人吃惊的是,其中大约22000个tokens——也就是将近50%——仅仅是为了描述工具本身。换句话说,智能体有一半的“脑力”是在理解自己有哪些工具可用,而不是真正用来处理用户问题,这种上下文浪费直接拉低了智能体的实际效率。
这种成本在典型的多服务器部署环境下更为显著。根据Anthropic今年4月发表的论文,工具定义部分最高时可消耗134000个tokens,而每回合的实际消耗也在15000到60000个tokens之间游走,进一步加剧了AI智能体在复杂场景下的性能瓶颈。
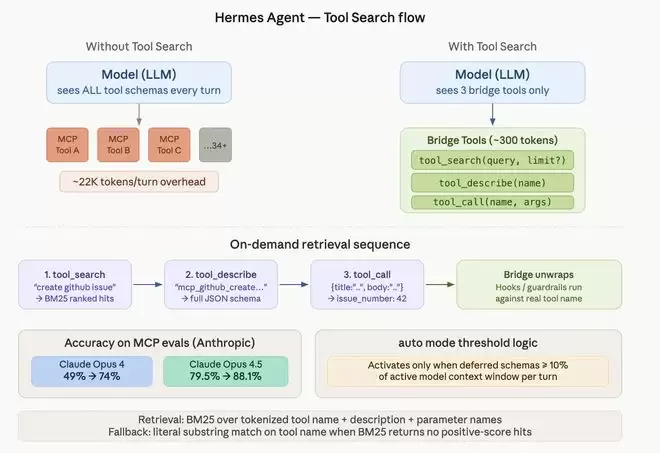
这带来的后果相当直接:成本飙升和准确率下降。会话启动时,由于缓存未命中,每次生成可能要花费0.07至0.10美元。更糟糕的是,当模型面对数百个与当前任务无关的工具选项时,反而会陷入“决策瘫痪”——本来要用工具解决问题,结果先在选择工具上绕了一大圈,严重拖慢智能体响应速度。
现在,Nous Research的开源项目Hermes Agent给出了一个巧妙的解法:Tool Search(工具搜索)。这个功能的思路很简单——不要再把所有工具的定义一股脑塞进上下文,而是让模型按需查找、按需加载,从而彻底消除MCP工具税带来的冗余开销。
实现上,Tool Search是一个可选的渐进式披露层。一旦开启,模型看到的工具数组里,原本的MCP工具和插件工具被替换成了三个核心“桥接工具”:
tool_search(query, limit?)——搜索延迟加载的工具目录tool_describe(name)——加载某个工具的完整模式定义tool_call(name, arguments)——调用延迟加载的工具
整个工作流程就像是一个三段式:模型先通过搜索找到可能合适的工具,然后查看这个工具的详细参数说明,最后再发起真正的调用。典型的交互过程如下:
Model: tool_search("create a github issue")
→ {matches: [{name: "mcp_github_create_issue", ...}]}
Model: tool_describe("mcp_github_create_issue")
→ {parameters: {type: "object", properties: {...}}}
Model: tool_call("mcp_github_create_issue", {title: "...", body: "..."})
→ {ok: true, issue_number: 42}
这就像先查目录、再读说明、最后动手操作,每一步的上下文开销都精确可控,让模型把有限的计算资源聚焦在核心任务上。
效果如何?Anthropic的内部MCP评测给出了非常有说服力的数字:Claude Opus 4在启用Tool Search后,准确率从49%直接跃升至74%;Claude Opus 4.5也从79.5%提升到了88.1%。无关工具的减少,明显降低了误选概率,同时大幅提升了AI智能体的实际推理表现。
搜索层本身的设计也值得关注。系统采用了经典的BM25文本检索算法,匹配工具名称、描述和参数名。如果BM25没有返回正分结果,系统会回退到工具名的字面子串匹配,避免所有工具名都含有相同词时出现零分问题。这套兜底机制,保证了搜索的鲁棒性,即使在工具命名不规范的情况下也能稳定工作。
配置参考
如果要在实际项目中启用Tool Search,只需在hermes.yaml文件中添加以下配置:
tools:
tool_search:
enabled: auto # auto(默认)、on 或 off
threshold_pct: 10 # 自动模式启用的上下文百分比阈值
search_default_limit: 5
max_search_limit: 20
从目前的发展趋势来看,如何高效管理工具集的上下文消耗,正在成为AI智能体落地的关键瓶颈。Tool Search这种“按需加载”的思路,也许就是下一个阶段的标配方案。毕竟,让模型把宝贵的注意力花在解决问题上,而不是纠结于用哪个工具——这才是正确的方向,也是下一代智能体架构的核心竞争力。




