当大语言模型的参数规模不断冲向百亿甚至千亿量级时,人们的关注点已经悄悄发生了变化。现在,大家最关心的已经不只是“怎么更快收敛”这类常规问题,而是两个更本质的挑战:训练过程中如何保持稳定,以及,从小模型到大模型的超参数迁移到底怎么做到。
具体来说,第一个挑战表现为训练中各种数值和动力学层面的不稳定现象——注意力logits持续增大、激活输出范数慢慢漂移、深层网络频繁出现损失尖峰,严重时直接数值溢出、训练崩溃。第二个挑战则高度依赖μP(Maximal Update Parameterization)这类尺度化理论,它希望在不同宽度下,通过对参数矩阵和更新尺度施加系统性的约束,使得超参数可以在不同规模的模型间顺利迁移。
面对这些问题,目前主流的工程应对手段主要集中在两个方向上。一类通过梯度裁剪、激活截断、学习率衰减等方式,直接压制训练中的数值爆炸;另一类则借助归一化或谱约束等机制,对参数或更新的尺度做显式控制,减缓漂移。这些方法确实能在一定程度上抑制不稳定现象,但说到底,它们更多是在现象层面打补丁,而不是从优化动力学的根源去解决问题。
加法更新:一个“天然”的隐患
归根结底,无论是μP尺度的失效,还是训练中频频出现的失稳问题,传统优化器的加法更新范式都要负主要责任。
过去几年,AdamW和Muon这些优化器的设计重点,无一例外都放在了“如何更快地降低训练损失”和“提升训练效率”上。但它们本质上都采用加法更新: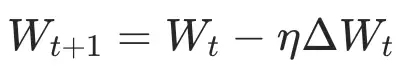 。换句话说,它们的关注点天然就是“怎么沿着梯度快速下降”,而不会主动去约束权重矩阵的几何结构。
。换句话说,它们的关注点天然就是“怎么沿着梯度快速下降”,而不会主动去约束权重矩阵的几何结构。
随着训练不断推进,这种无约束的加法累积同时改变了参数的长度和方向,慢慢破坏了参数矩阵的谱几何。具体表现就是:奇异值谱范数被持续放大,不同特征方向的尺度越来越失衡,整体矩阵范数不断漂移。
这些底层的几何变化进一步放大了网络中的激活值,摧毁了μP所依赖的前向尺度前提。换句话说,许多训练失稳与参数化崩溃现象,并不仅仅来自梯度太大,而是因为参数矩阵本身的结构在长期更新过程中逐渐失控了。
从谱保持重新理解稳定训练
近期的工作POET [1] 提出了一条新思路:通过控制参数矩阵本身的谱结构来实现稳定训练。POET的核心做法,是利用正交矩阵对权重进行双侧变换: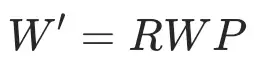 ,其中(R,P)为正交矩阵。由于正交变换本质上只是旋转特征空间,不会改变奇异值,因此这样的更新天然具有保谱性质。这意味着:
,其中(R,P)为正交矩阵。由于正交变换本质上只是旋转特征空间,不会改变奇异值,因此这样的更新天然具有保谱性质。这意味着:
- spectral norm不会被无约束放大;
- 参数矩阵整体范数更加稳定;
- 特征空间可以持续演化,但矩阵尺度不会失控。
不过,POET仍然依赖重参数化训练框架,需要额外维护两个可训练的正交矩阵,并且固定原始权重矩阵。这不仅给训练系统的兼容性和跨架构适配带来了额外复杂度,也要求更复杂的一阶动量设计。
Pion:不做重参数化,直接把“保谱”写进优化器
基于这些观察,我们进一步提出了Pion(POET-induced Optimizer with No Reparameterization)。与POET不同,Pion不再依赖显式的重参数化,而是直接将“谱保持更新”写进了优化器本身。
Pion从一个非常简单但关键的观察出发。对于任意权重矩阵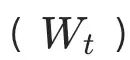 ,都可以写成:
,都可以写成:
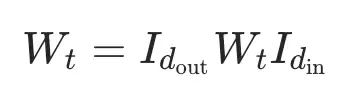
这里的两个单位矩阵,本质上可以被视为“零旋转”的正交变换。
Pion的做法,并不是显式学习新的(R,P),而是直接在正交群上更新这两个“单位因子”,从而对权重矩阵施加左右两侧的正交变换。将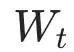 的梯度记为
的梯度记为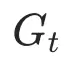 ,Pion的更新规则可以写成:
,Pion的更新规则可以写成:
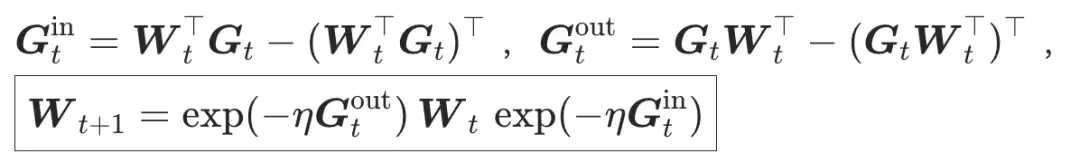
其中,两侧更新都由Lie algebra中的斜对称矩阵生成,并通过矩阵指数映射回正交群。
这种更新方式带来了一个非常重要的性质:Pion不再直接去“拉伸”权重矩阵,而是在特征空间中对其进行旋转。
由于左右两侧始终是正交变换,Pion会严格保持权重矩阵的奇异值不变。这意味着,在训练过程中:
- spectral norm不会被无约束放大;
- Frobenius norm保持稳定;
- 权重的行空间与列空间持续演化,但整体尺度不会失控。
从几何视角来看,传统优化器的更新往往同时混合了参数长度的变化和参数方向的变化。而Pion则将更新完全转化为“旋转运动”。因此,Pion的更新范数不再对应参数缩放,而直接刻画了特征空间中的旋转强度。这说明:模型不是在无约束地放大参数,而是在稳定地旋转特征空间。
基于上述规则,进一步对加速更新技术的探索,由于篇幅有限,这里不再展开,详情可见论文。我们将最终的Pion算法总结为伪代码(图1):

图1:Pion优化器算法流程。
Pion与μP:谱保持优化器实现尺度迁移
μP(Maximal Update Parametrization)具体来说要求权重矩阵的spectral norm满足固定尺度规律,并且参数更新量的spectral norm也满足对应尺度规律。
过去已有的μP-compatible优化器,大多建立在Muon路线之上。原因在于:Muon的更新天然容易满足“更新谱条件”,因此之前的工作主要关注如何进一步修正它的权重尺度。而Pion刚好相反。由于Pion的更新始终保持权重谱结构稳定,它天然满足μP对权重矩阵spectral norm的尺度规律。于是问题变成了:如何让Pion的更新幅度也满足μP的scaling law。
为此,我们进一步设计了μP-compatible的Pion版本,对更新中的Lie algebra因子进行谱归一化控制。分别在LLaMA架构和Qwen架构上,对不同模型宽度验证了learning rate transferability。如图2所示,Pion的最优学习率几乎可以跨模型尺度直接迁移。
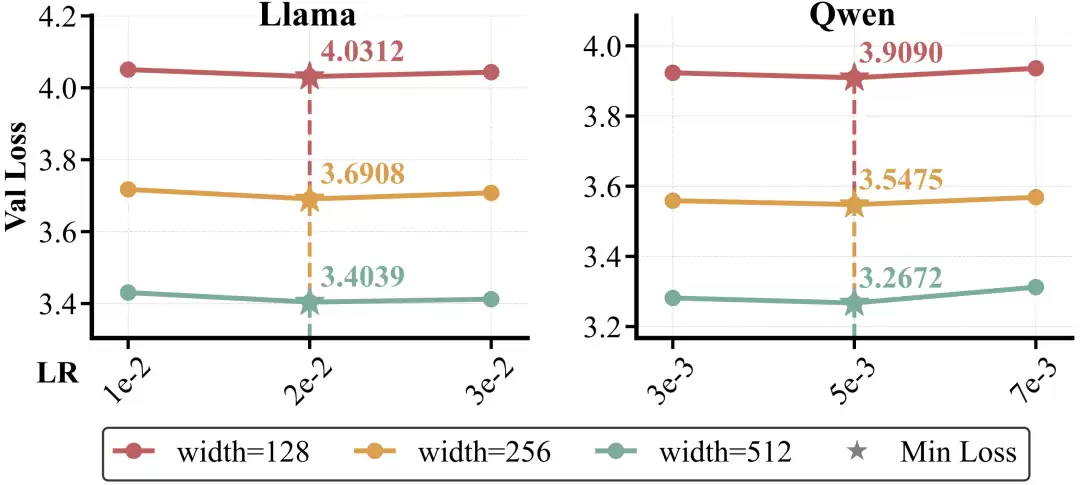
图2:Pion与μP。
Pion谱保持优化器:实现稳定高效训练
我们从预训练和后训练两个方面来观察Pion的训练稳定性。预训练方面,除了常规结构的训练,还额外增加了压力测试:完全去除归一化层以及超深层网络,来检验Pion在极端情况下的稳定性。后训练方面,则采用了SFT和RLVR两个常规pipeline进行测试。
稳定预训练

图3: 稳定性指标
在LLaMA-like 1.3B模型上进行预训练时,除了验证损失,我们进一步监控了多项训练稳定性指标(如图3所示)。其中,SwiGLU激活范数以及最大attention logit,已经被广泛认为是大规模预训练中的关键稳定性指标。可以看到:AdamW的attention logit持续增长,同时激活范数迅速放大;Muon虽然显著抑制了attention logit的增长,但其激活值与down-projection相关范数仍在整个训练过程中持续上升;相比之下,Pion对所有监控指标都保持了近乎平坦且稳定的演化轨迹。这种截然不同的训练动态,来自于Pion有效的谱保持特性,如图4所示。
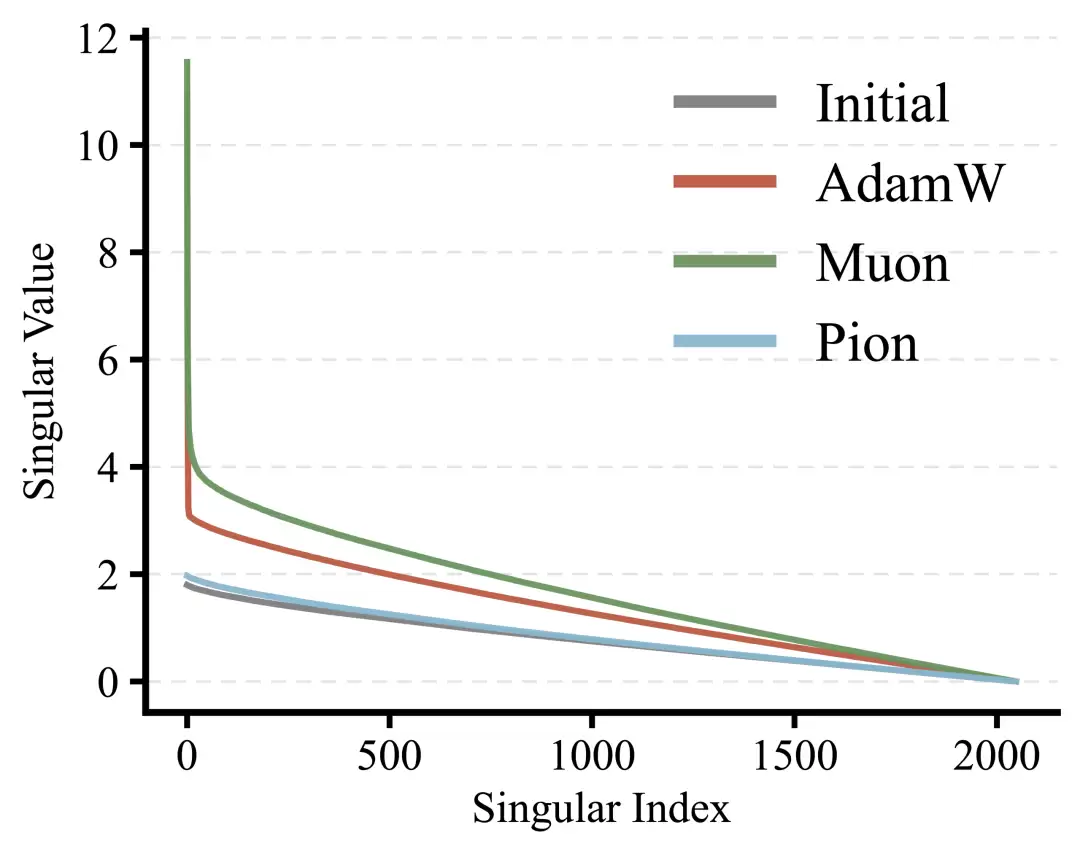
图4:谱的保持。
得益于稳定训练以及更均匀的谱,Pion在zero-shot测试任务上取得了更好的泛化性(图5):

图5: Benchmark性能。
Normalization-free训练
为了进一步对Pion的训练稳定性进行压力测试,我们移除了一个60M LLaMA-like模型中的所有normalization层。之所以采用这一设置,是因为normalization长期以来都被认为是控制激活尺度、稳定梯度反向传播的关键机制。因此,在缺少normalization的情况下,训练会变得极其不稳定,也能够更直接地检验:优化器本身是否具备足够的尺度控制能力。
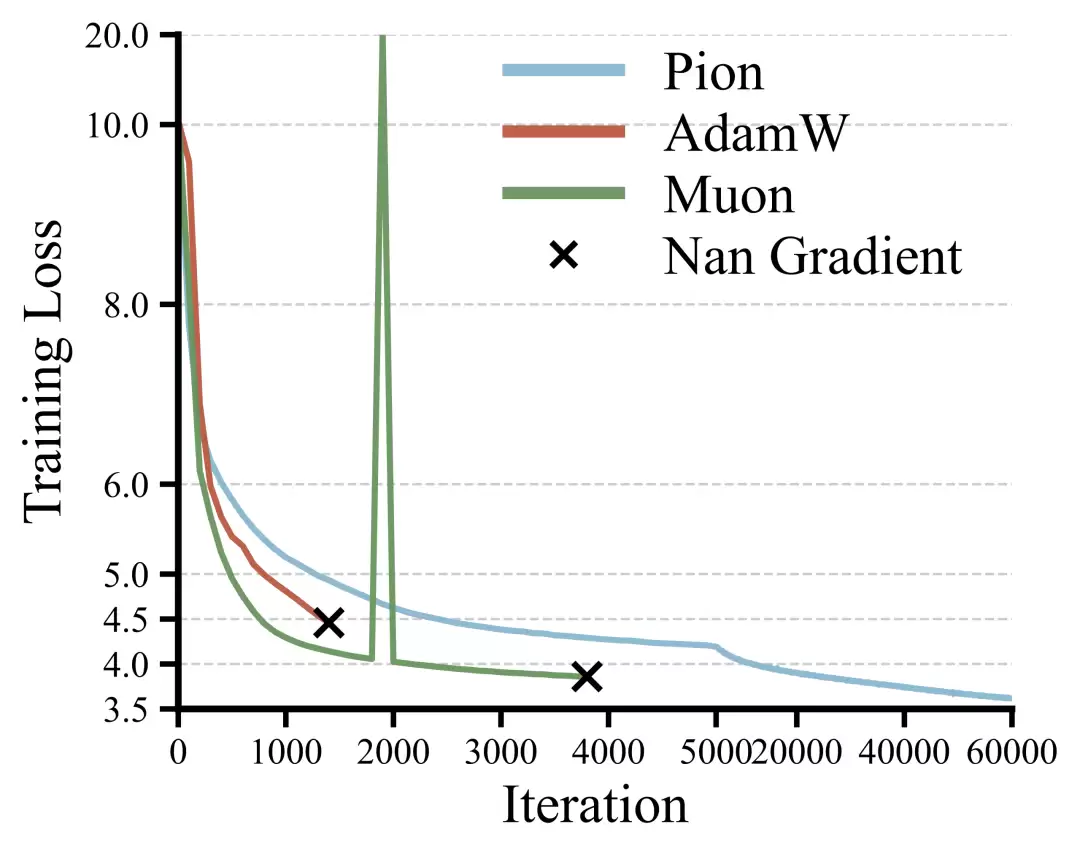
图6: Normalization-free训练曲线
实验结果非常明显,如图6所示。在这一设置下,AdamW与Muon虽然能够在训练初期取得一定进展,但很快便由于梯度溢出而训练崩溃,并最终产生NaN。相比之下,Pion在完整的9.6B token训练过程中始终保持稳定,并最终成功收敛。这一结果表明:谱保持优化在一定程度上能够替代架构层面的尺度控制机制,为模型训练提供一种来自优化器本身的稳定性来源。
超深层网络结构
为了进一步对Pion的稳定性进行压力测试,我们在极端深度的LLM结构上开展了实验。深层网络通常被认为是优化稳定性的“放大镜”,容易引发严重的训练问题,例如梯度消失以及表示坍塌等现象。在该实验中,我们将一个60M规模的LLaMA基线模型从8层逐步扩展至200层,并在50B tokens的C4子集上进行训练。如图7所示,为了更清晰地展示训练动态,我们通过局部loss轨迹的标准差均值来衡量训练稳定性,其对应的阴影面积可视化了波动程度。
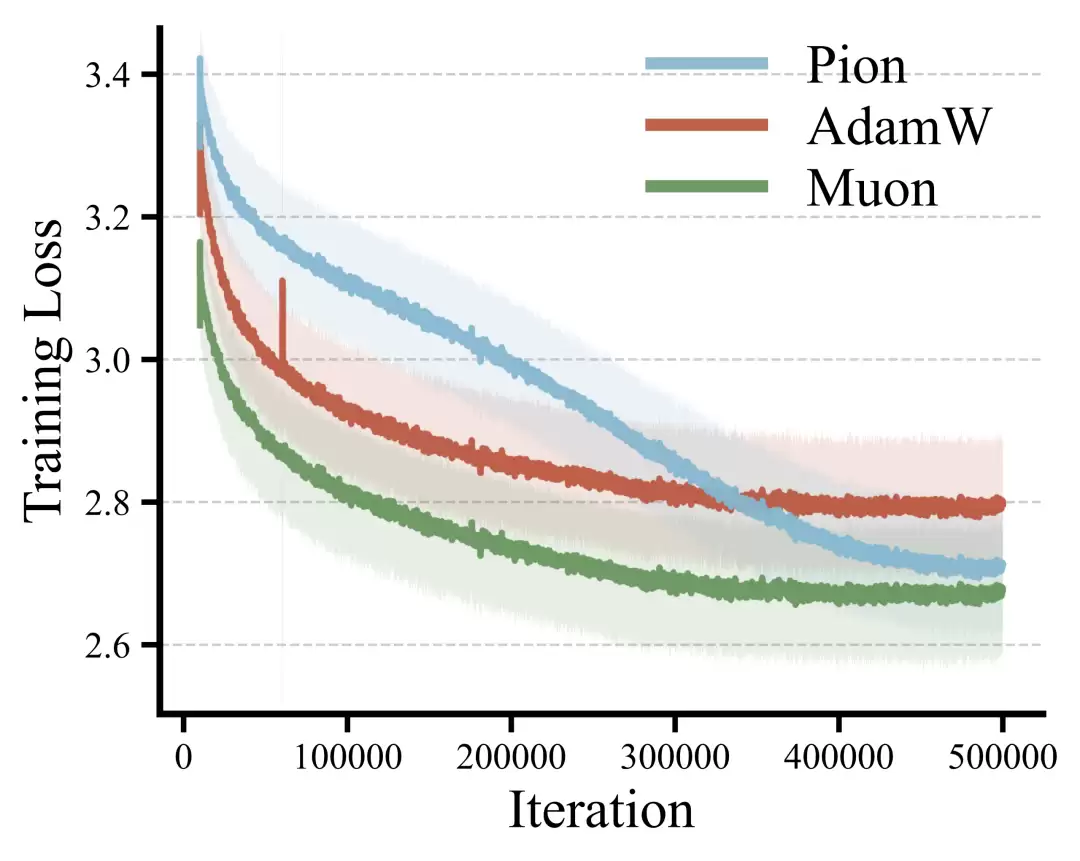
图7: 深层网络训练
实验结果显示:AdamW出现最明显的loss spike,整体稳定性最差;Muon在训练过程中仍然存在持续的波动累积;Pion则在整体训练过程中保持最平滑的loss轨迹。对应的标准差统计结果分别为:AdamW:0.0931;Muon:0.0927;Pion:0.0892。这表明在极端深度设置下,Pion表现出最优的训练稳定性,同时仍然能够在中期阶段实现更快的loss下降。
监督微调
在监督微调(SFT)阶段,一个长期存在的问题是:模型在学习新任务时,很容易遗忘原有能力。这本质上是一个stability-plasticity tradeoff:plasticity太强,学得快但容易灾难性遗忘;stability太强,保留旧能力但新任务适应困难。
我们在Qwen2.5-1.5B和Llama3.2-3B两个基础模型上进行了全参数微调实验,覆盖了数学推理和代码生成两类典型任务。如图8所示,Pion在多个维度展现出了更好的平衡能力。尤其是在代码生成任务中,Pion同时取得了最高的ID(in-domain)与OOD(out-of-domain)表现;数学微调任务中,Pion也在保持接近最优ID性能的同时,更有效地维持了OOD泛化。
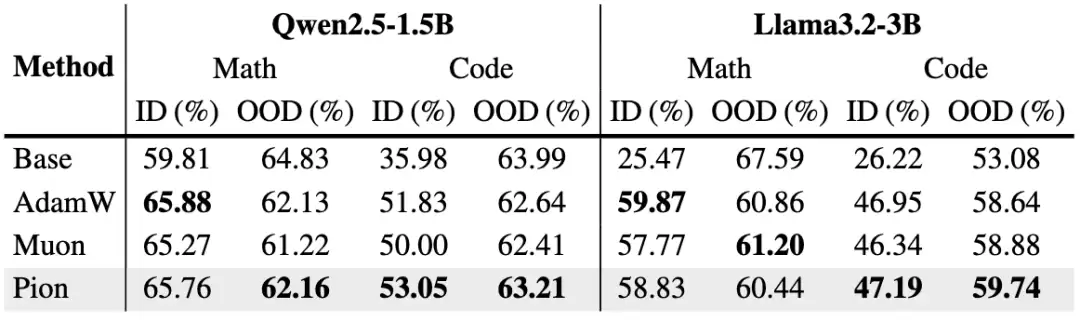
图8: Pion应用于监督微调。
这表明:Pion不仅能更好地学习目标任务,同时还能更稳定地保留原始模型能力。换句话说,Pion的谱保持更新,不仅稳定了训练过程,也稳定了模型知识本身。相比于传统优化器频繁改变参数尺度,Pion更倾向于在已有表示空间中进行“结构化旋转”,因此不容易破坏预训练阶段已经形成的特征结构。
Reinforcement Learning with Verifiable Reward

图9: Pion应用于RLVR。
进一步测试了Pion在RLVR(Reinforcement Learning with Verifiable Reward)中的表现。RL往往是大模型训练中最不稳定的阶段之一,具体来说,reward variance大,optimization noise强,容易出现模式崩塌与训练震荡。最近的一些研究发现了一个非常有意思的现象:RL阶段的参数更新其实往往天然倾向于保留预训练权重的谱结构。这意味着,强化学习可能本身就更偏向“结构保持型更新”。而这与Pion的更新几何几乎天然一致。因此,我们在Qwen3-1.7B、DeepSeek-R1-Distill-Qwen-1.5B上进行了RLVR实验,并采用GRPO训练框架进行数学推理强化学习。如图9所示,Pion在所有RL设置下都取得了最佳平均表现。与此同时,验证集accuracy曲线(图10)也显示:Pion收敛更快,训练更稳定,后期性能波动更小。
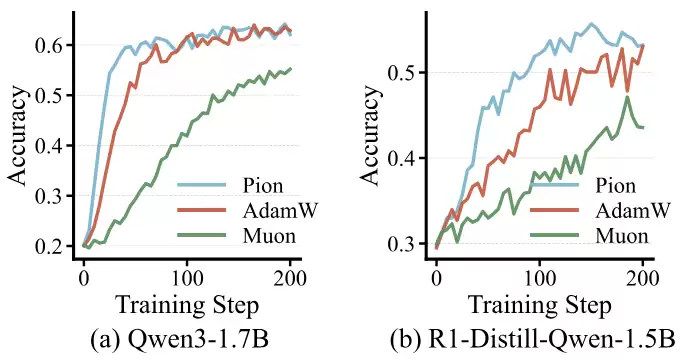
图10: Pion在RLVR任务上的训练曲线。
这些结果表明:谱保持不仅适用于预训练,也可能是一种更适合RL的优化归纳偏置(inductive bias)。
结论:从“收敛优化器”到“稳定优化器”
在很长一段时间里,人们默认优化器的职责只有一个:尽快降低loss。但随着大模型训练规模不断扩大,“稳定性”本身,正在变成优化器最核心的能力之一。而Pion提供了一个不同于传统路线的方向:它不依赖大量训练补丁,而是通过参数更新本身的几何约束,从源头抑制谱结构失控。因此,Pion的意义可能不仅仅是“一个更稳定的优化器”,它更预示着:大模型优化器的下一阶段,也许不只是更快下降,而是更可控、更结构化、更长期稳定。
