想象一下,你拥有一位堪称“全能学长”的教师模型——它几乎无所不知,知识储备极其丰富。然而问题在于,它实在太占空间了!它的“书包”(模型体积)和“学习资料”(计算资源)几乎塞满整个房间,让那些想要学习的小伙伴(移动设备与物联网设备)感到压力巨大。
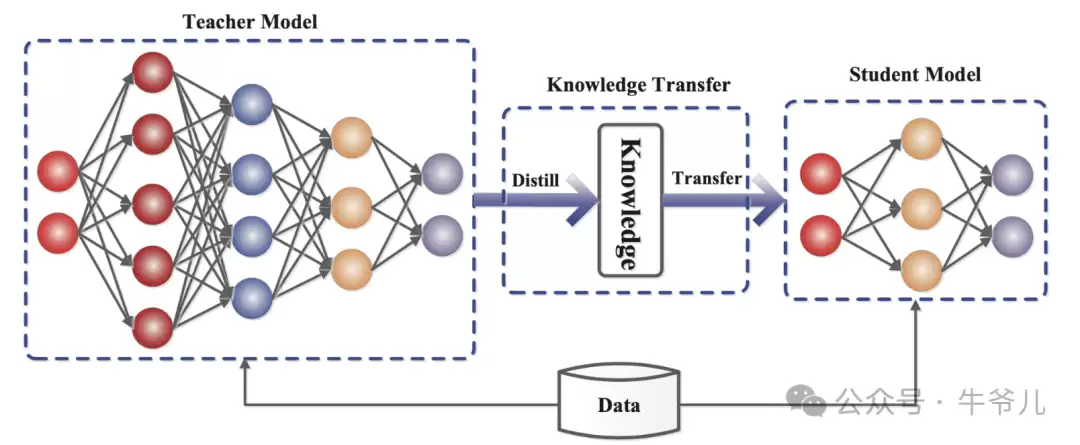
这时,就需要“瘦身大师”——知识蒸馏(Knowledge Distillation)登场了。它就像一位神奇的教练,能够将学长的知识与智慧(模型能力)高效地传授给身材小巧的学生模型。经过一番特训之后,学生模型也能像学长一样精准回答问题,而且身轻如燕、便于携带,瞬间成为大家眼中的小明星。
简单来说,知识蒸馏是一种让智慧不占空间、随时随处可被调用的技术。它实现了大模型智慧的有效传承,同时显著提升小模型的能力,堪称大模型界的“瘦身神药”。
知识蒸馏的提出背景及应用场景
知识蒸馏的出现,核心目标正是解决大型深度学习模型在实际部署中面临的困境。随着模型规模不断膨胀,它们在处理复杂任务时表现耀眼,但随之而来的是计算资源消耗巨大、存储要求高、难以落地等问题。为了让这些强大的模型能在资源受限的环境(如移动端或嵌入式设备)中发挥作用,知识蒸馏应运而生,成为模型压缩与轻量化部署的关键技术之一。
常见的应用场景包括移动设备上的语音识别。例如,在手机上实现实时语音识别,模型必须兼具高效率与低延迟,但大型语音识别模型的计算需求在移动端往往无法满足。通过知识蒸馏,这些大型模型的丰富知识能够传递给小型模型,使后者在保持较高识别准确率的同时,在移动设备上流畅、稳定地运行,真正实现边缘智能。
大语言模型环境的当下,知识蒸馏是如何工作的?
对于大型语言模型(比如GPT系列),知识蒸馏同样适用且极具价值。以下是进行知识蒸馏的一般步骤:
1. 准备教师模型和学生模型
首先,需要一个预训练好的大型语言模型来扮演教师角色——它参数众多、结构复杂,正是智慧的源泉。接着,设计一个结构更简单、参数更少的学生模型。学生模型的设计必须充分考虑实际部署环境的资源限制(如内存、算力、功耗),从而在性能与效率之间取得最佳平衡。
2. 定义蒸馏目标和损失函数
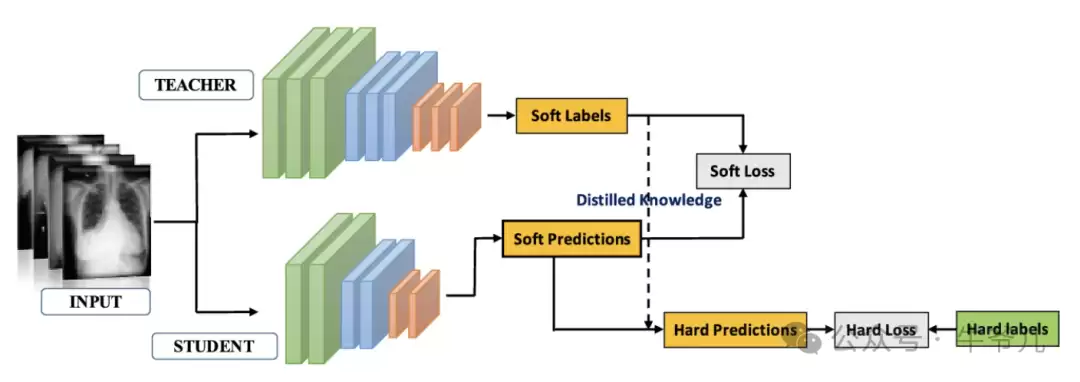
知识蒸馏的核心目标,是让学生模型尽可能模仿教师模型的行为。这一过程通常通过一个损失函数来衡量两者输出之间的差异。特别值得注意的是,教师模型的“软目标”——即其输出的概率分布——蕴含着比硬标签更丰富、更细腻的知识,能够为学生模型提供额外的学习素材,帮助学生模型更好地理解数据中的潜在规律。
3. 训练学生模型
训练阶段,学生模型通过不断调整参数来最小化损失函数。标准做法是使用反向传播算法进行迭代优化。在这个过程中,学生模型不仅学会了如何将输入映射到输出,还从教师模型的概率分布中“汲取”了隐藏知识,从而掌握教师模型的精髓——包括分类边界、模糊区域以及类别间的关系等。
4. 评估和优化
训练完成后,当然要拉出来遛遛——通过标准测试集对学生模型进行全面评估,检验其瘦身后的真实水平。如果性能不达标,可以通过调整学生模型结构、增加蒸馏温度参数、或结合额外训练数据等方式进行优化,反复迭代直至满意。
5. 部署学生模型
一旦学生模型通过了评估,就可以正式上岗了。由于它规模小、复杂度低,在资源受限的环境中运行起来毫不费力——无论是手机、智能音箱、可穿戴设备还是工业传感器,都能轻松承载,真正实现大模型智慧的轻量化落地。
what's next?
接下来的文章,我们将具体聊聊知识蒸馏的原理细节(如温度缩放、注意力迁移等)以及更多实际应用案例,敬请期待。