借助Dify与Firecrawl轻松实现网页信息自动化抓取,快速构建高效爬虫工作流,让数据采集更智能。
今天我们来探讨一个非常实用的场景:如何利用AI工具让爬虫变得简单——不再需要编写数百行代码,而是通过Dify工作流就能快速实现。从实际开发经验来看,当前AI提升效率最显著的领域之一,就是使用网络爬虫工具自动获取目标站点信息,并进行检索与自动化处理。话不多说,我们先从一个最简单的Dify工作流开始,后续完全可以按需求逐步迭代、扩展功能。
一、Dify工作流的设计目标
设计目标一句话就能讲清楚:使用AI应用开发工具Dify调用网络爬虫工具Firecrawl,根据用户提供的目标网址,自动抓取信息并返回结构化的结果。
二、应用工作流的详细步骤拆解
1、总流程框图
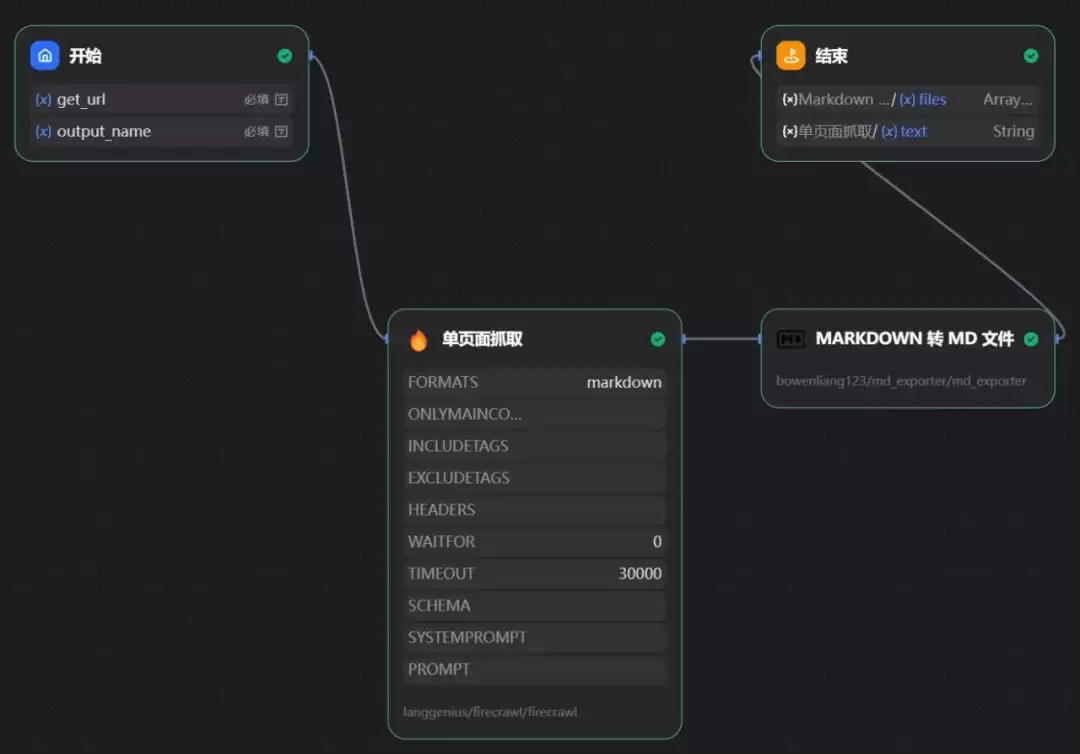
整个应用设计突出“简单”二字。功能实现围绕“自动化爬取指定网页信息”来构建,因此只选取了Dify工作流中最基础的四个节点:开始 → 单页面抓取 → Markdown转MD文件 → 结束。全程没有调用AI大模型,纯粹依靠工具本身完成抓取与转换。
2、开始【节点】
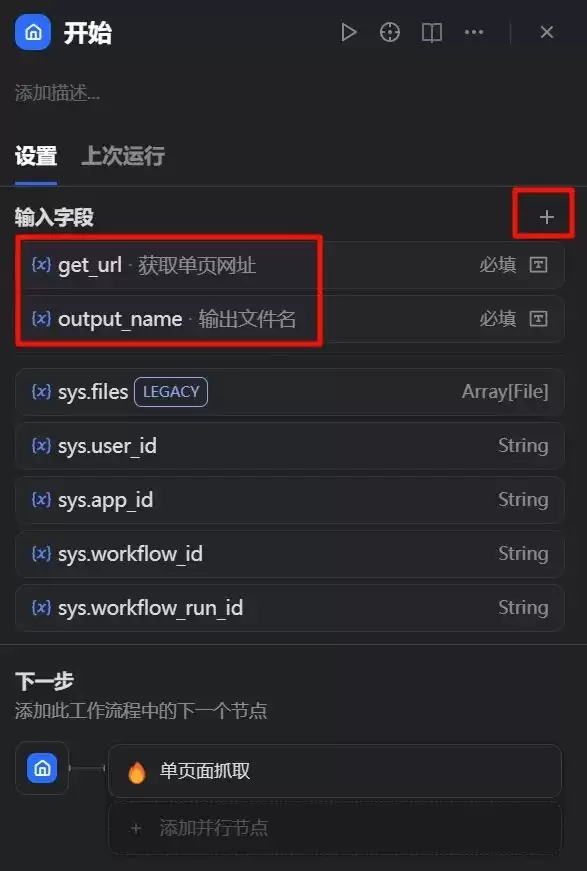
开始节点的作用很明确:为整个工作流提供启动所需的输入信息。这里我们需要为Firecrawl提供要抓取的网页URL(变量名:get_url;文本格式,长度256)。另外,考虑到流程最后要将抓取到的网页信息转换为AI更擅长处理、人类也容易阅读的Markdown格式文件,所以还要在开始节点提前指定输出文件的名称(变量名:output_name;文本格式,最大长度48)。
3、单页面抓取【节点】
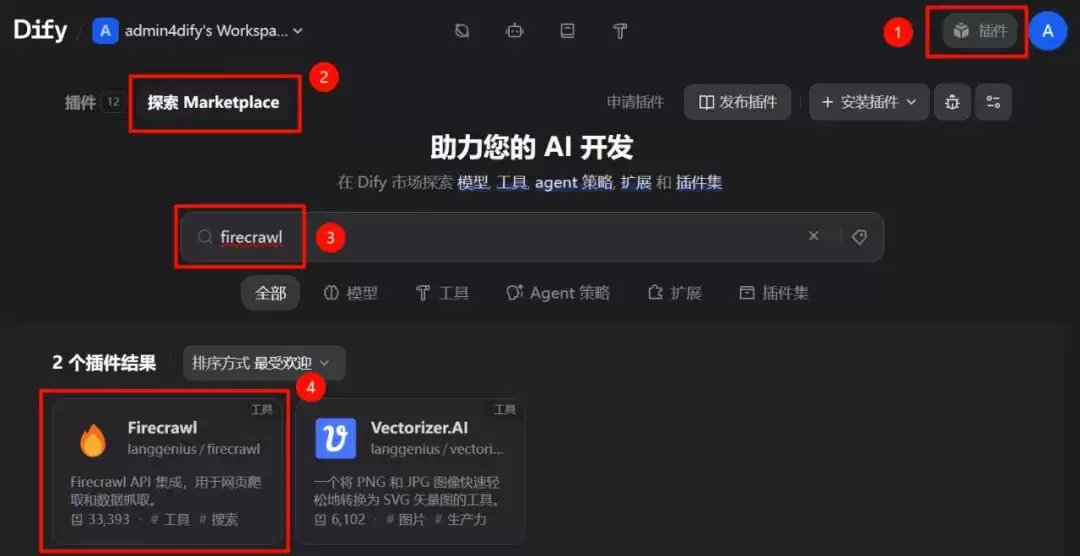
在配置单页面抓取节点之前,有两步准备工作需要完成。首先,在Dify的“插件” → “探索Marketplace”中搜索“firecrawl”。
然后,前往Firecrawl官网(https://www.firecrawl.dev/)注册账号,生成自己的API Key。
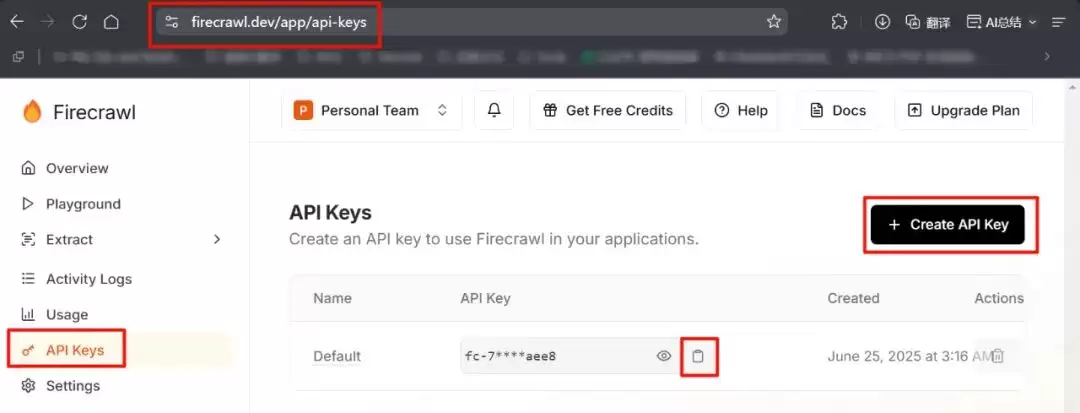
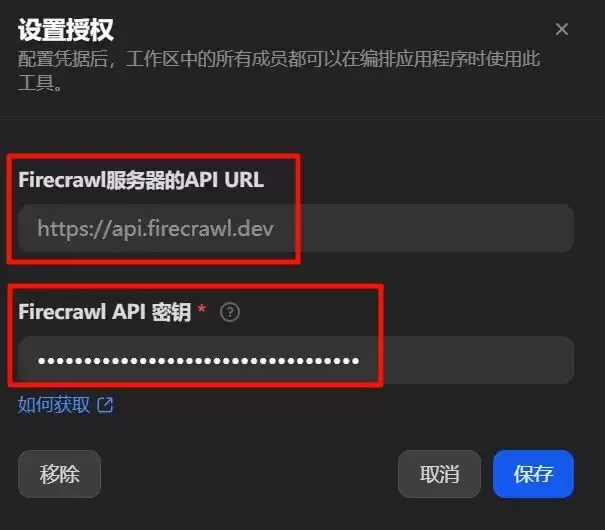
回到Dify的“插件”页面,找到Firecrawl,填入刚才生成的API Key,完成授权。
单页面抓取节点的设置是整个工作流最核心的部分。从开始节点往下走,需要选择“工具”中的“firecrawl”。
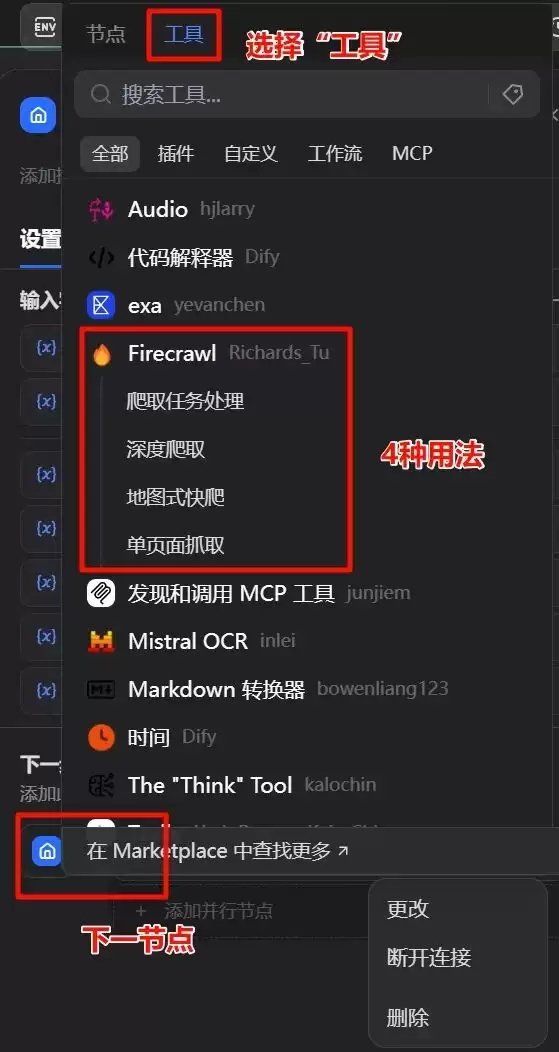
Firecrawl工具提供了4种用法:
爬取任务处理;
深度爬取;
地图式快爬;
单页面抓取。
这里我们选择最简单、最基础的操作——单页面抓取。
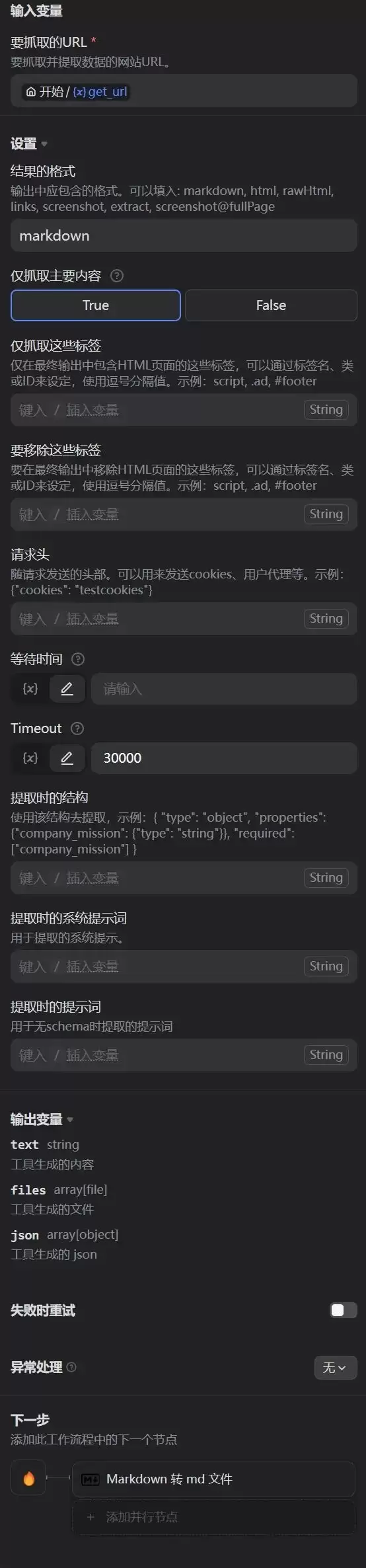
具体配置如下:
“结果的格式”:填写“markdown”。这是最终想要的输出格式,当然也可以选择HTML、截图、压缩包等。
“仅抓取主要内容”:选择“True”。这样只会抓取页面上最有价值的文本信息,过滤掉边角料。
“仅抓取这些标签”:留空。这块我们不太确定,所以先保留空白;不过可以补充说明一下,“script”一般代表代码等描述格式,“.ad”代表广告信息,“footer”代表页脚信息,等等。
“要移除这些标签”:留空。不需要的页面元素都可以在这里剔除。
“请求头”:留空。其实这是一个关键设置——许多网站的反爬校验都需要通过设置“请求头”来突破。
“等待时间”:留空。单页面抓取一般无需设置,只有多页爬取时才需要留一个等待时间,避免被判定为机器行为。
“Timeout”:30000秒。
“提取时的结构”:留空。
“提取时的系统提示词”:留空。
“提取时的提示词”:留空。用于没有定义schema时提取内容的提示。
输出变量有3种:“text”(文本信息)、“files”(文件)、“json”。写到此处忍不住留个疑问:结束节点是否可以直接输出单页面抓取节点的“files”输出呢?如果可以,就能省掉Markdown转换节点了。不过原有流程已经跑通,这个疑问留到下次测试再验证。
4、Markdown转md文件【节点】
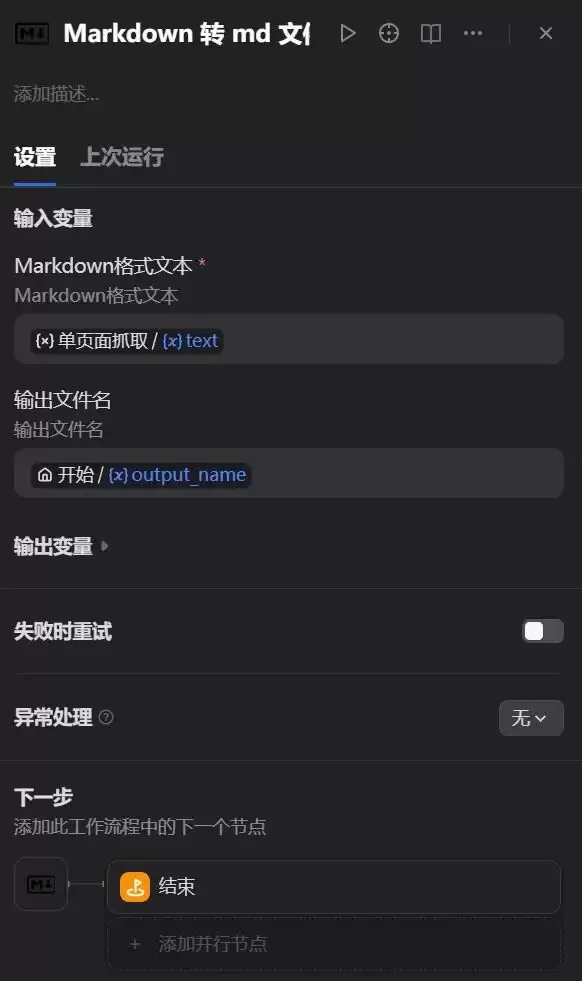
输入变量:{x}单页面抓取/{x}text
输出文件名:开始 / {x}output_name
5、结束【节点】
在结束节点设置2个输出:一个是抓取回来的信息按Markdown格式文件输出(可下载到本地),另一个是抓取回来的信息在当前Dify对话框界面中直接显示。
三、测试用例
在日常IT信息系统规划过程中,经常需要查询各类国家标准规定。“国家标准化管理委员会”官网(https://www.sac.gov.cn/)是必查的。举个例子,2025年充电宝爆炸、罗马仕公司高管跑路之后,传闻国家要重新制定充电宝行业标准。委员会下属的“国家标准全文公开系统”(https://openstd.samr.gov.cn/bzgk/gb/index)就能查询到所有国家标准化文档。
在网站上搜索关键字“数据中心”,得到与该关键词相关的国家标准列表,页面只显示最新的10条结果。
运行Dify应用“firecrawl单页爬取”,得到Markdown格式的文件《20250716国家标准化网站“数据中心”类标准列表.md》。用Windows的“记事本”程序(或者Obsidian开源软件)打开,效果如下:
虽然格式看起来有点凌乱,但页面中最重要的那张10行表格,所有信息和格式都准确对应了下来。后续,完全可以依据页面上的“下一页”等链接,自动化爬取更多网页页面。下载到本地的md文件,也可以导入Dify知识库,方便进一步查询。
四、最后
Firecrawl工具在Dify的加持下,已经能自动化帮我们抓取所需的网页信息。不过有一点需要提醒:Firecrawl的API Key并不是完全免费的。官网的收费策略如下:
免费的API Key支持500张页面的抓取操作。如果希望大批量使用,可能需要考虑将Firecrawl进行本地私有化部署。
```