第三章 问题排查的六阶段模型
当面对线上故障或开发环境中的程序缺陷时,最忌讳的就是一上来就急于修改代码。请先保持冷静,按照系统化的步骤逐步推进。
阶段0:镇定与复现 —— 稳定重现是排查的前提
镇定: 切勿看到错误就立刻动手改代码。仓促的修改往往会引入更多新问题,让自己陷入更深的困境。
首先,深呼吸,像侦探一样收集证据:错误日志、屏幕截图、用户的具体操作步骤,以及完整的运行环境信息(操作系统、版本号、依赖库的版本)。然后串联所有线索,根据用户提供的步骤尝试复现这个程序缺陷。如果无论如何都无法复现,就需要反向追问用户更多细节——你使用的是哪个浏览器?网络环境如何?输入的数据长什么样?一旦能够稳定复现,下一步就是尽量精简复现步骤,得到一个最小复现用例。这一步做得扎实,后续的定位工作就能事半功倍。
复现技巧:
- 二分法精简输入: 假设一个超长的 JSON 数据会触发故障,不要逐行检查。每次删除一半字段后测试,反复几次,就能精准定位到导致问题的那个最小字段。此法屡试不爽。
- 自动化脚本提效: 对于偶尔发生、尤其是并发类问题,编写自动化脚本反复执行操作,可以显著提高复现概率。
# 自动压力测试脚本示例
import threading
import requests
def worker():
for _ in range(100):
requests.post('https://localhost:8080/api', json={'key': 'value'})
threads = [threading.Thread(target=worker) for _ in range(10)]
for t in threads: t.start()
for t in threads: t.join()
阶段1:定位 —— 缩小错误发生的范围
当故障可以稳定复现后,进入“缩小包围圈”阶段。核心思路是:持续缩小代码的嫌疑范围。
常用方法:
- 打印探针: 在怀疑是问题根源的关键路径上插入简单的打印语句,例如
print("1")、print("2")。观察输出,看程序执行到哪个数字后不再打印,那个位置就接近问题点了。 - 异常捕获: 在顶层代码添加
try-except,将完整的调用堆栈打印出来。这是快速确定错误发生行号的最直接方式。 - 注释法(代码二分法): 这是一个非常暴力的方法,但效率极高。暂时注释掉一半的代码,看故障是否仍然出现。如果消失,说明错误在注释掉的一半里;反之则在另一半中。然后对包含错误的那一半继续二分。如此反复,即使是一个2000行的模块,用不了5次二分就能锁定到具体函数。
阶段2:隔离 —— 排除外部干扰因素
很多时候,程序缺陷并非代码逻辑本身的问题,而是与环境中某些外部因素发生了“化学反应”。这时需要将问题从复杂系统环境中剥离出来进行“纯净测试”。
隔离手段:
- 关闭所有非必需的插件或中间件。
- 使用测试替身(mock、stub)替代真实的数据库或外部 API 调用。
- 换一台机器或环境(比如从 Windows 切换到 Linux)运行相同的代码。
from unittest.mock import Mock
# 代替真实的外部 API 调用
mock_api = Mock()
mock_api.get.return_value = {'status': 'ok'}
def process_data(api_client):
data = api_client.get('/data')
return data['status']
assert process_data(mock_api) == 'ok'
阶段3:提出假设 —— 基于证据的合理猜测
收集足够信息后,就要开始推测。但这不是瞎猜,而是基于证据、可验证的假设。一个糟糕的假设是:“可能是内存问题”。一个好的假设是:“第88行分配的那个10MB缓冲区没有释放,重复100次后内存就溢出了。”
假设的来源:
- 过往的经验和教训(常见的错误模式)。
- 仔细阅读相关文档,了解所用函数是否有不为人知的副作用。
- 进行一次认真的代码审查,寻找明显的逻辑缺陷。
阶段4:实验验证 —— 用最小成本检验假设
有了假设就要验证。实验设计必须遵循一条铁律:一次只改变一个变量。同时,尽量不修改原始代码,优先使用断点、日志或外部监控手段。每次实验都要记录结果——是通过、失败还是部分通过?
验证手段:
- 加上断言,然后运行单元测试。
- 在开发环境里临时修改代码重新部署。
- 用调试器单步观察关键变量的值。
阶段5:修复与回归测试
找到问题的根本原因后,修复代码只是基本功。更重要的是确保这个故障从此“斩草除根”。修复时一定要深入理解根因,避免只治标不治本,例如在 finally 块里添加 close 语句。
修复完成后还有两个关键动作:第一,专门针对这个故障编写一个单元测试,确保它不会再次悄悄出现。第二,运行所有既有测试用例,确认修复没有引入新的回归问题。
阶段6:复盘与预防
最后一步,也是让工程师从“解决问题”迈向“预防问题”的关键一步。将整个事件记录下来:现象是什么?根因是什么?如何修复的?以后如何避免?
然后思考更深层次的问题:我们的设计或流程能否优化,从根本上杜绝这类错误?例如,是否该增加类型注解?改进 API 设计?还是引入更严格的静态检查?最后,将这次经验分享给团队,让所有人都能避开这个坑。这才是排查问题的最大价值。
第四章 错误分类与针对性排查手册
现实中的错误五花八门,但我们完全可以将其分门别类,针对不同类型的错误采用不同的策略。
4.1 语法错误 —— 编译器/解释器直接指路
这类错误最“友好”,因为编译器或解释器几乎会直接告诉你问题所在。常见的有:少写了括号、引号、运算符;Python 里缩进不对;Java 或 C 中变量未声明;或者不小心使用了保留字作为变量名。
排查步骤: 仔细阅读错误信息里给出的文件名和行号。首先检查报错的那一行,然后检查它的上一行(很多错误其实是上一行没写完整)。利用 IDE 的语法高亮以及 ESLint、Pylint 等 Lint 工具,能将大部分语法错误扼杀在摇篮里。
进阶提示: 有时报错行号会指向一个根本不存在的行(例如宏展开的代码),这时需要查看预处理后的输出或生成的代码才能找到根因。
4.2 编译/链接错误 —— 类型不匹配、符号未定义
这类错误比语法错误稍复杂。例如 Java 中 String s = 123; 会报类型不匹配,或者调用了一个不存在的方法。排查时,先检查 import 语句是否正确,再检查类路径(classpath)是否包含所有依赖,还要留意泛型类型擦除可能带来的古怪问题。C/C++ 的链接错误通常意味着函数声明了但未实现,或者对应库没链接上。
String s = 123; // 类型不匹配
obj.undefinedMethod(); // 符号未定义
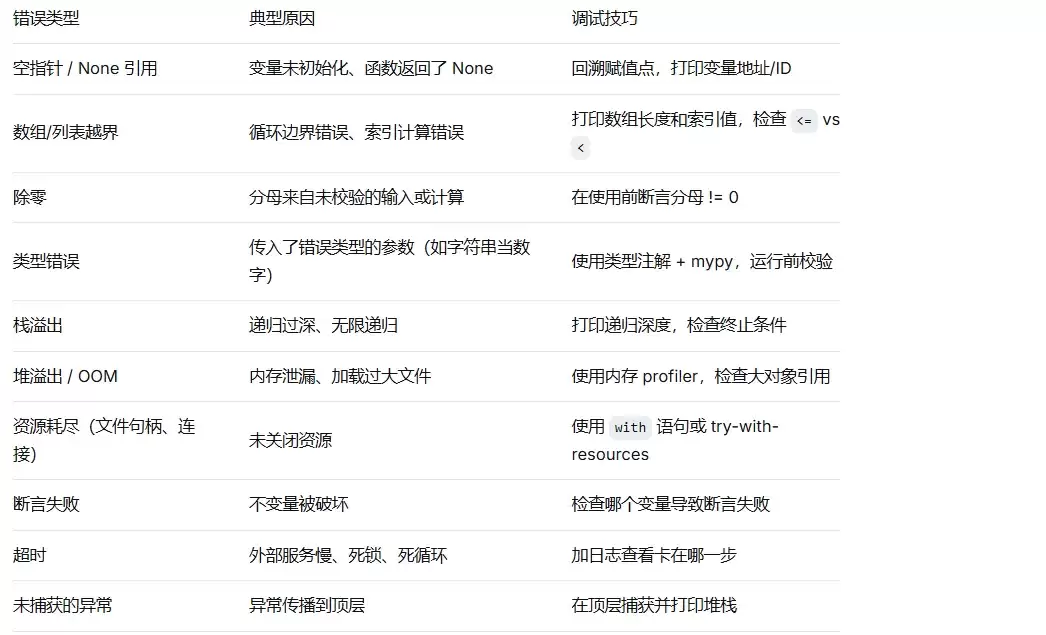
4.3 运行时错误 —— 细分10种及对策
4.4 逻辑错误 —— 最难缠的敌人
如果说编译错误是明枪,那逻辑错误就是暗箭。程序能正常跑完,但结果就是不对,而且没有任何异常信息。排查这种错误,只能靠检查代码的中间状态。常见的逻辑错误包括:
- 数值错误: 公式写错、取整方式不对、浮点精度问题。
- 条件错误: 大于号写成小于号、逻辑与和逻辑或用混。
- 流程错误: 循环多跑一次或少跑一次、某分支条件一直未被覆盖。
- 状态错误: 忘记重置全局变量、共享变量未做同步。
- 数据处理错误: 字符串编码不对、JSON 解析错误却被代码悄悄吞掉。
系统化排查方法:
- 二分检查点法: 与前面的定位思路类似,在关键逻辑的中间点输出结果,对比预期值。
- 单元测试 + 数据驱动: 编写大量测试用例,提供不同输入和期望输出,观察哪个用例失败。
- 可视化执行: 对于算法逻辑错误,在纸上或 Excel 里画出每一步的状态变化。
- 变量跟踪表: 手动模拟代码一步步执行,记录所有变量的变化。
举例:二分查找的常见错误。
def binary_search(arr, target):
left, right = 0, len(arr) - 1
while left < right: # 错误:这里应该是 <=
mid = (left + right) // 2
if arr[mid] == target:
return mid
elif arr[mid] < target:
left = mid + 1
else:
right = mid - 1
return -1
# 测试:binary_search([1,2,3], 3) 返回 -1
通过单步执行会发现,当 left=1, right=2, mid=1 时,arr[1]=2 < 3,所以 left 变为 2。此时 while 条件 2 < 2 为假,循环直接退出,因此漏掉了检查索引 2。把条件改成 while left <= right 就解决了。
4.5 并发错误 —— 多线程/多进程的噩梦
并发错误之所以令人头疼,是因为它高度依赖线程调度的时序,基本无法稳定复现。经典的并发问题包括:竞态条件(对共享变量的非原子操作)、死锁、活锁、饥饿以及内存可见性问题。
排查工具: Java 世界有 jstack、JConsole、VisualVM;Python 可以用 enumerate() 和 sys._current_frames();C++ 则可以用 ThreadSanitizer 或 Valgrind 的 helgrind。
实战案例: 两个线程同时给一个账户存款。
public class BankAccount {
private int balance = 0;
public void deposit(int amount) {
int newBalance = balance + amount; // 读-改-写
balance = newBalance;
}
}
如果线程 A 读到 balance 为 0,然后线程 B 也读到 0,接着 A 把新值 1 写回去,B 也把 1 写回去。明明存了两次钱,账户上却只有 1 元。修复方法很简单:加上 synchronized 或者使用 AtomicInteger。
检测技巧: 在关键代码前后加一个计数器,然后用另一个线程持续检查某些不变量是否被破坏。例如,用一个后台线程持续验证当前的 balance 是否等于所有存款之和。
4.6 性能问题 —— 慢比崩溃更折磨人
当系统不崩溃但就是慢得让人抓狂时,需要进行性能排查。常见的性能瓶颈包括:不合理的算法复杂度(比如用 O(n²) 的算法处理海量数据)、频繁的磁盘 I/O 或网络 I/O、锁竞争导致大量线程阻塞、内存分配和 GC 压力过大,或者连接池、线程池配置得太小。
排查流程: 先设定一个基线,然后在理想情况下逐步增加负载(用 JMeter、wrk 等工具进行压力测试),找到系统性能的拐点。接着用 Profiler 工具(如 Java 的 Async Profiler、Python 的 cProfile)找出最耗时的函数或分配内存最多的地方。最后,将数据生成火焰图,直观地看到调用栈和耗时占比。
python -m cProfile -o output.prof my_script.py
snakeviz output.prof # 可视化
优化策略: 引入缓存(Redis 或本地缓存)、使用消息队列进行异步处理、优化数据库索引和查询、用批处理代替单条操作、减少锁的粒度或使用读写锁。
4.7 内存错误 —— 泄漏、越界、野指针
C/C++ 的典型内存问题:忘记释放内存导致泄漏、释放后继续使用(use-after-free)、越界写入导致缓冲区溢出、多次释放(double free)。排查这类问题,Valgrind 和 AddressSanitizer 是两大神器。Python 虽然不用手动管理内存,但也会有内存泄漏,通常来自全局容器不断增长或循环引用。使用 tracemalloc 可以精准定位。
import tracemalloc
tracemalloc.start()
# ... 运行代码 ...
snapshot = tracemalloc.take_snapshot()
top_stats = snapshot.statistics('lineno')
for stat in top_stats[:10]:
print(stat)
4.8 环境与配置错误 —— “在我的机器上能跑”
这句经典台词背后,往往是环境配置的差异。包括:依赖版本不匹配、环境变量缺失、文件权限不足、端口冲突、时区设置不同,甚至不同操作系统间的换行符差异。
排查策略: 使用 Docker 容器化技术来统一开发、测试和生产环境。仔细对比开发和线上环境的配置。在代码启动时主动做环境检查(比如强制要求 Python 版本大于 3.8)。或者用 strace(Linux)或 procmon(Windows)来追踪系统调用,查看具体是在哪个步骤失败了。




