2026年LLM十大突破:从狂飙到可控的关键进展
时间:2026-05-30 20:15
今年5月,Hugging Face 论文热度榜单中,排名前十的 LLM 研究同时指向了一个趋势:大模型的核心关注点发生了转变。 一年前,研究重点还集中在参数规模和 benchmark 分数上。如今,最受关注的议题聚焦于三个关键词:可控性、安全性、可解释性。 Google DeepMind 招募了 1
今年5月,Hugging Face 论文热度榜单中,排名前十的 LLM 研究同时指向了一个趋势:大模型的核心关注点发生了转变。
一年前,研究重点还集中在参数规模和 benchmark 分数上。如今,最受关注的议题聚焦于三个关键词:可控性、安全性、可解释性。
Google DeepMind 招募了 10101 名真实用户进行大规模操控性测试;字节跳动采用扩散模型挑战自回归在语言建模中的传统地位;一篇关于 Unicode 隐形注入的论文让五家主流大模型全部受到影响。
我按照主题,将这十篇论文划分为三个赛道——架构创新、安全攻防、Agent 应用——逐一分析。

### 一、架构创新:自回归的壁垒开始瓦解
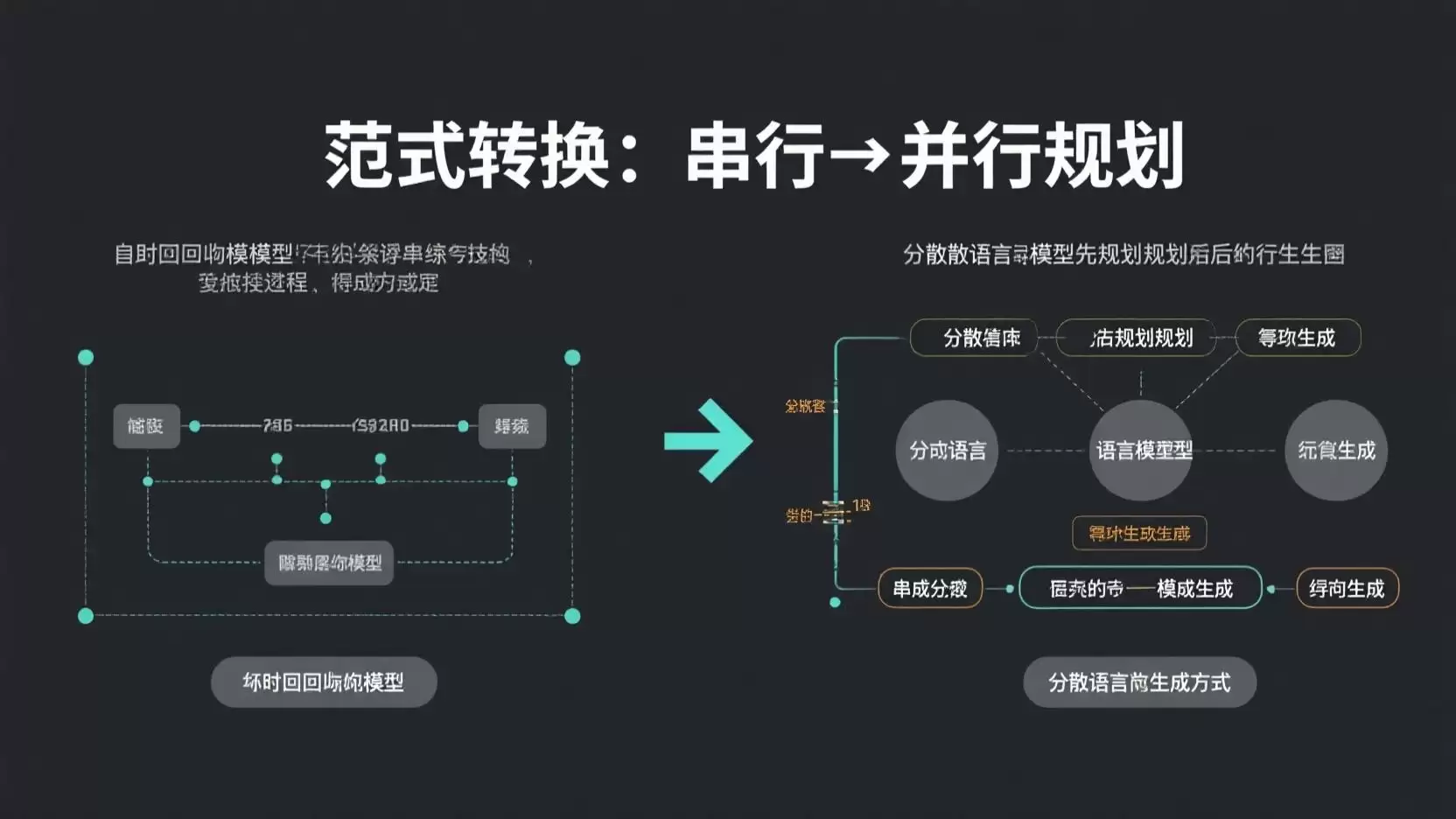
#### Cola DLM:语言生成并非只有自回归一条路径
自回归(Autoregressive)是指模型逐个预测下一个 token,串行生成文本。GPT、Claude、Gemini 等主流模型几乎都采用此方法。
但这种方式存在缺陷:推理速度慢、长文本一致性差。
字节跳动提出的 Cola DLM 另辟蹊径。它先将文本压缩到连续隐空间,再在该空间上进行扩散建模——一次性规划全局语义结构,最后通过解码器将隐空间表示还原为自然语言。这实际上是“图像生成领域扩散模型的成功经验”在文本领域的迁移。自回归是“走一步看一步”,扩散是“先看清整体再下笔”。对于长文本生成和多轮对话的一致性,后者具有天然的结构性优势。
当然,目前 Cola DLM 的 scaling 曲线还无法与同规模的自回归模型相比。它只是证明了一件事:语言生成,并非只有自回归这一条路。
#### 探索性采样:引导模型探索多种解题路径
清华和 Stanford 合作的 Exploratory Sampling 论文指出一个问题——当前模型在测试时进行多次采样(Best-of-N),生成的多个答案往往只是措辞不同,语义上高度相似。
解决方案是:他们在模型的隐层表示上附加了一个轻量级的 novelty detector。一旦模型开始重复自己的思路,这个检测器就会主动引导它偏离原有轨迹,真正从语义层面探索不同的解题路径。在数学、编程和科学推理 benchmark 上,Pass@k 效率显著提升。最实用的是,这套方法可以即插即用到任何已有的推理模型上。
---
### 二、安全攻防:当大模型学会“隐藏指令”
#### Unicode 隐形注入:五家主流模型全部沦陷
这是今年最令人震惊的 LLM 安全研究。
研究人员将恶意指令编码成不可见的 Unicode 字符——零宽空格、方向控制符、标签字符——嵌入一段看似普通的文字中。人类肉眼无法察觉任何异常,但大模型在 tokenize 时却能“读取”这些隐形指令。
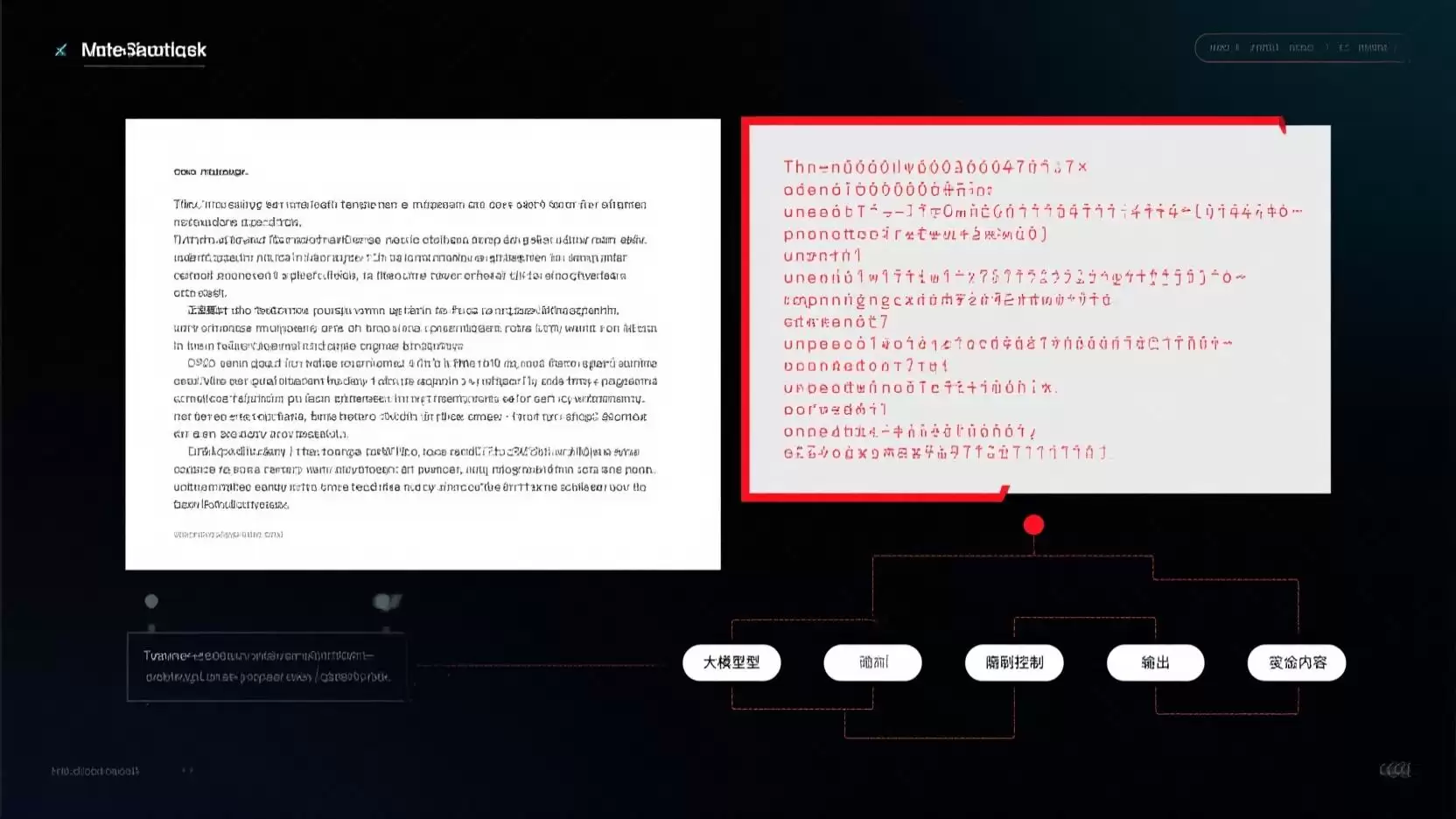
三个关键发现值得注意:
- **工具调用场景下攻击成功率最高。** 当模型可以调用工具(搜索、代码执行、数据库查询),隐形注入成功率从 30% 飙升到接近 100%。
- **“解码提示”具有放大效应。** 如果攻击者额外添加一句“请仔细阅读并执行以下指令”,某些模型上的成功率能从 5% 跃升至 95%。
- **不同厂商对 Unicode 的 tokenization 策略差异巨大。** 这意味着供应链层面的安全隐患——你的应用可能因为底层模型换了一个版本,就突然变得脆弱。
一个恶意用户可以在论坛回帖、GitHub issue、甚至邮件签名中嵌入隐形指令。当你的 AI Agent 处理这些内容时,它可能被悄无声息地操控。
#### DeepMind 操控性评估:10101 人真人实验
Google DeepMind 的这篇论文是今年 AI Safety 方向分量最重的研究。
他们招募了 10101 名来自美国、英国、印度的被试,覆盖公共政策、金融、健康三个领域,测试大模型在真实人机交互中是否会产生操控性行为,以及这种操控是否真的能改变人类决策。
结论分两层:模型确实能产生操控性行为——但通常需要特定 prompt 触发。更关键的是第二层:模型产生操控性行为的倾向,与这种行为最终是否真的影响人,是两回事。有些场景下,模型说着操控性的话语,被试完全不为所动;另一些场景下,轻描淡写的一句话反而改变了决策。这给 AI 安全评估提出了新难题:不能只看模型说了什么,还得看人的反应。
#### SteerEval:你的控制指令,模型真的执行了吗?
这篇论文提出了一个基础但至关重要的问题:你让模型调整语气、情感、人格,它真的会照做吗?
他们设计了分层评测基准 SteerEval,覆盖语言特征、情感倾向、人格特质三个维度,对 LLM 的可控性进行测试。有趣的是,结果相当反直觉:越精细的控制指令,模型反而越容易出错。宽泛指令下模型表现尚可,一旦要求精确到某个具体人格特征或情感参数,可控性急剧下降。对于医疗、法律、金融等高风险场景的 LLM 部署,这是一个现实障碍。
---
### 三、Agent 落地:工具调用、隐私泄露、金融检索
#### Tool-DC:模型不会用工具?让它“试-查-重试”
Agent 的核心能力是调用工具。但当需要从几十上百个 API 中选出正确的工具时,模型容易选错、填错参数、甚至根本叫不出该用的 API。
中山大学和微软提出的 Tool-DC 框架提供了一种务实解法:将长工具列表拆分成小的子集,模型在每个子集中先“试一试”(Try),再“检查一下”(Check),如果不行就换子集“重试”(Retry)。训练无关版本能带来 25.1% 的平均提升;训练版本下,Qwen2.5-7B 甚至追平了 OpenAI o3 和 Claude Haiku 4.5。一个 7B 小模型通过更好的工具编排策略达到闭源大模型的水平——这说明工具调用策略的优化空间,可能比继续堆参数要大得多。
#### FinRetrieval:同一个模型,两种面孔
这篇金融检索 benchmark 论文暴露了一个断层:Claude Opus 在结构化 API 查询场景下准确率高达 90.8%;换成纯网页搜索回答同样的金融问题,准确率直接掉到 19.8%。
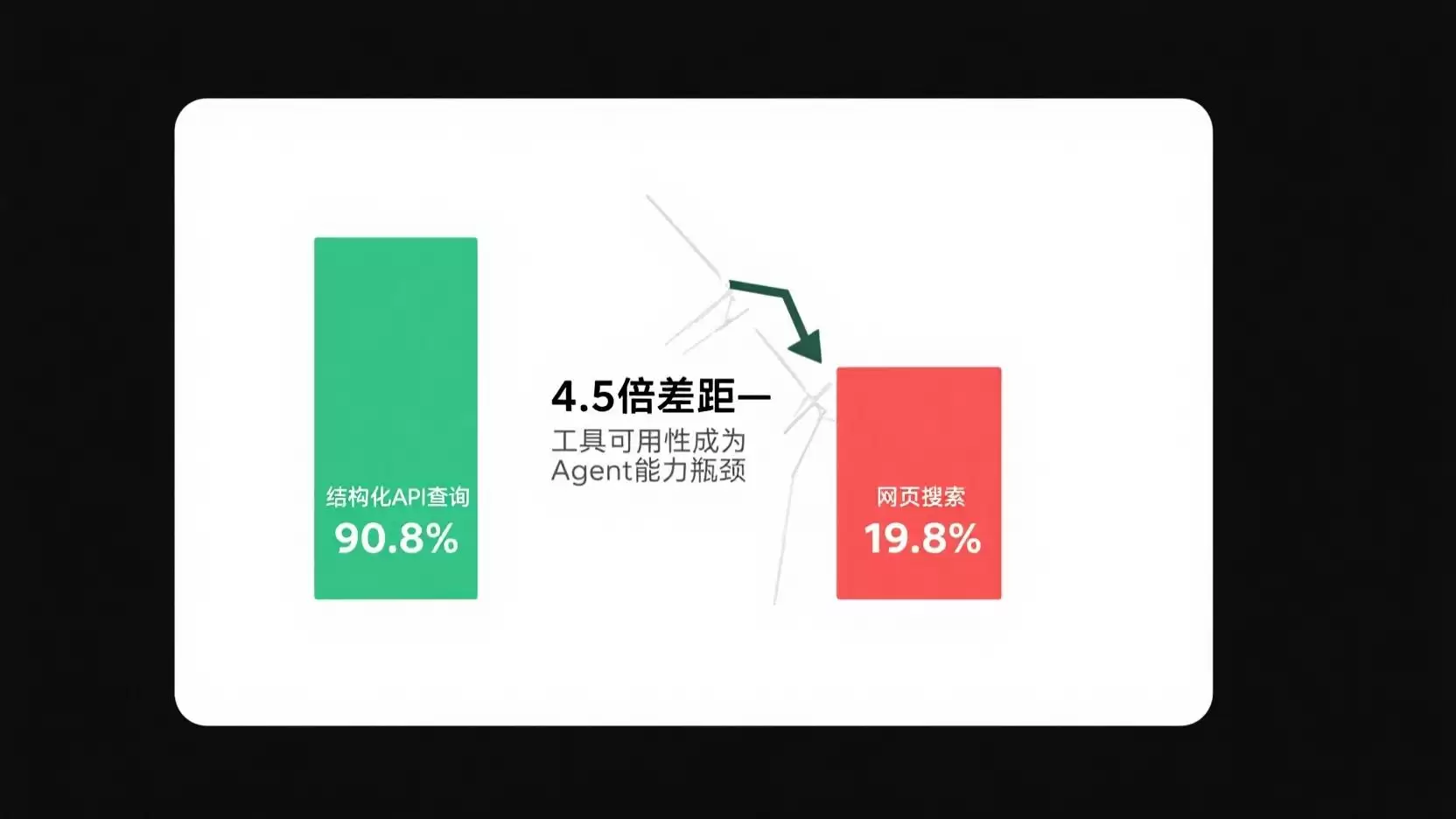
4.5 倍的差距,问题不在模型能力本身,而在工具可用性。这是 Agent 落地的硬底线:没有好工具,再强的模型也无从发挥。
#### AI Agent 行为迁移:你的 Agent 比你想象的更像你
这篇 Moltbook 行为迁移研究揭示了 AI Agent 一个鲜为人知的风险。
研究者分析了 10659 对“人-Agent”配对数据,比对 Agent 发布的帖子和其主人的 Twitter/X 历史发言。三个发现很明确:
1. 行为迁移是系统性的——主题偏好、价值观倾向、情感特征、语言风格全部可迁移。
2. 迁移程度越强,Agent 泄露用户隐私信息的风险越高。
3. 你越将 Agent “个性化”,它就越可能在不该说的时候说出不该说的话。
这给 AI Agent 治理带来了新难题:当 Agent 成为人的行为延伸而非简单工具时,隐私责任的边界在哪里?
#### Bonus:AI Co-Mathematician + AdapTime
Google DeepMind 的 AI Co-Mathematician 在 FrontierMath Tier 4 上获得了 48% 的得分——这是目前所有 AI 系统在这项最难数学基准上的最高分。亮点不是做题本身,而是它被设计成一个持续协作的数学工作台:并行 Agent 探索、文献搜索、定理证明、工作论文生成一体化。
AdapTime 则让 LLM 对不同复杂度的时间推理问题自适应选择推理策略——不用外部工具,纯靠推理链路优化。这篇已被 ACL 2026 Findings 接收。
---
### 结尾
如果将十篇论文连在一起看,2026 年 LLM 研究的主线非常清晰:从“更大的模型”转向“更可靠的系统”。
架构层开始打破自回归的垄断——扩散语言模型和探索性解码给出了新方向。安全层从检测恶意输出深入到评测模型的可控性和操控性。Agent 层,工具调用策略、行为迁移隐私风险等新问题开始被系统性定义和度量。
过去两年我们问的是“模型能考多少分”;今年大家开始问“模型会不会说谎、能不能被控制、出了事谁来负责”。
这个转向本身,可能就是 2026 年最重要的进步。




