VibeThinker-3B是VibeThinker系列在3B参数规模上的最新尝试,聚焦于那些带明确验证信号的挑战性推理任务——数学、编程、STEM领域。通过对VibeThinker-1.5B中引入的频谱到信号原理(SSP)后训练流程做系统化升级,这家伙在AIME、HMMT、IMO-AnswerBench、LiveCodeBench乃至最新的LeetCode竞赛中,成绩亮眼。在可验证推理基准上,它已经能与Qwen3.6 Plus、Gemini 3 Pro、GLM-5、Kimi K2.5这些顶尖前沿模型掰手腕了。
基于这些观察,我们发现一个很有意思的现象——不妨叫它“参数压缩-覆盖假设”:不同的能力,对参数的依赖方式根本不同。可验证推理更像是一种高可压缩、参数密集的能力,核心在于多步推理、约束满足、自我纠正、答案验证。只要任务空间结构足够清晰,反馈信号足够可靠,紧凑模型也能逼近前沿水平。相反,开放域知识、通用对话、长尾场景理解,则高度依赖大参数规模去广泛覆盖事实、概念和世界知识。
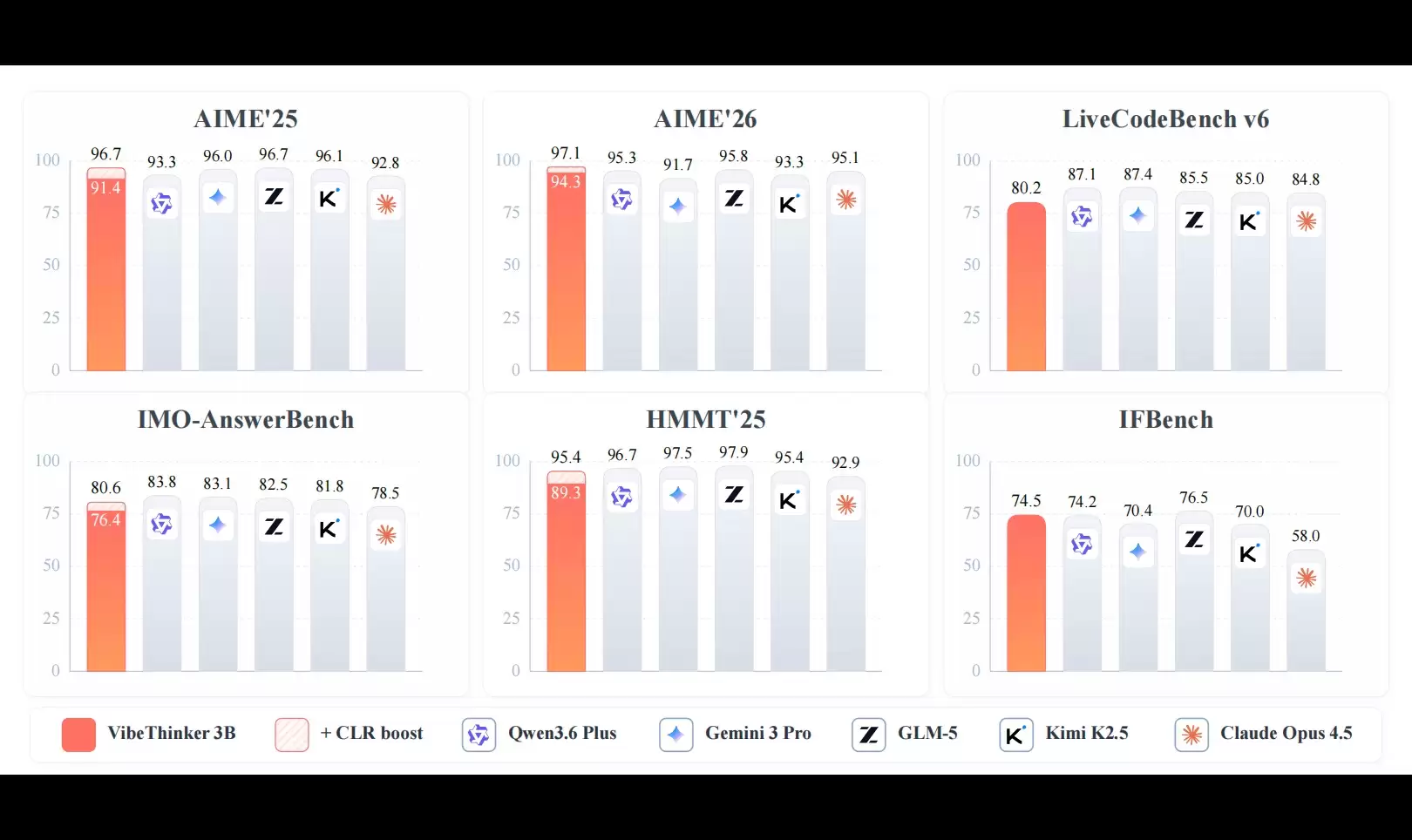
来看具体数字:VibeThinker-3B只有30亿参数,在IMO-AnswerBench(400个IMO级别问题的硬核基准)上拿到76.4分,借助一项叫Claim-Level Reliability Assessment(CLR,一种针对答案可验证推理的测试时缩放策略)的加持后,进一步提高到80.6分。对比一下:DeepSeek V3.2(6710亿参数)是78.3分,GLM-5(7440亿参数)82.5分,Kimi K2.5(1万亿参数)81.8分。不到3亿分之一的参数量,却跑出了同一梯队水平的分数,这才是关键所在。
更现实的一点:3B规模的模型,消费级显卡就能跑起来,部署成本和门槛大大降低。
从VibeThinker-1.5B到VibeThinker-3B,目标从来不是拿小模型去取代大模型,而是沿着特定能力维度,探一探小模型的真正边界。通过VibeThinker-3B,我们想传达一个信号:别再把小模型仅仅看作是降低部署成本的权宜之计。在有明确反馈和验证机制的能力领域,小规模语言模型(SLM)正在成为一条前景广阔的研究路线——性能达到前沿水平,跟传统参数扩展范式形成根本性互补。
这篇技术报告详细介绍了VibeThinker-3B——一个30亿参数的紧凑密集模型,核心目标就是在严格的小模型范围内,看看可验证推理到底能走多远。基于Spectrum-to-Signal后训练范式,通过优化流程系统增强,流程包括课程式有监督微调、多域强化学习、离线自蒸馏。评估结果相当硬核:AIME26上达到94.3分(声明级测试时间缩放后提高到97.1),LiveCodeBench v6上Pass@1得分80.2,在最近未见过的LeetCode竞赛中展现出强大的分布外泛化能力,接受率高达96.1%。这有效踏入了一流推理系统的性能行列,跟DeepSeek V3.2、GLM-5、Gemini 3 Pro等规模大几个数量级的旗舰模型相比,不落下风甚至超出。此外,IFEval上拿到93.4分,证实这种极端的推理增强并非以牺牲指令可控性为代价。这些发现延展了之前15亿参数成果,并催生了参数压缩-覆盖假设:可验证推理可以被压缩成紧凑的推理核心,而开放域知识和通用能力则需要对事实、概念、长尾场景进行广泛的参数覆盖。这一观点表明,紧凑模型并非仅仅是部署高效的替代品,而是在参数密集能力范围内实现前沿水平性能的补充途径。
参考资料:
https://github.com/WeiboAI/VibeThinker
https://huggingface.co/WeiboAI/VibeThinker-3B
https://arxiv.org/abs/2606.16140