经过漫长的预热,OpenAI 的 GPT-5 今日终于正式登场,如约亮相。
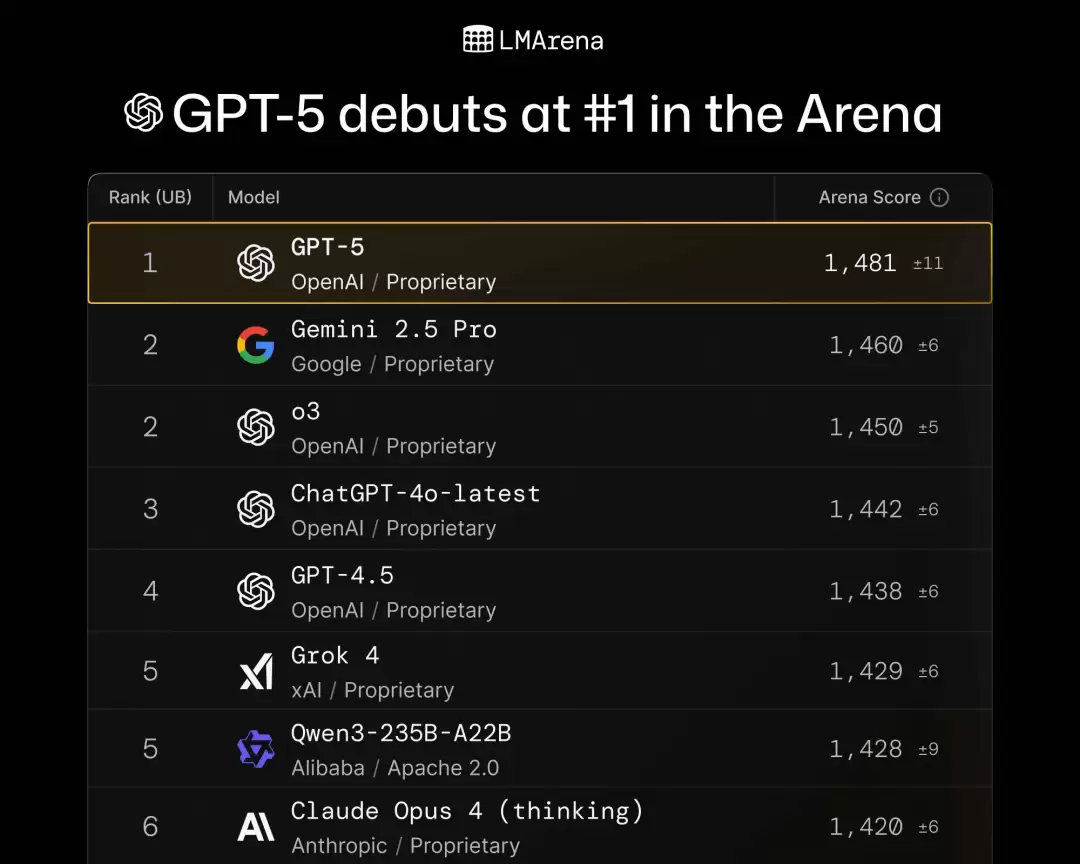
上线后不久,GPT-5 便在 lmarena.ai 的竞技排行榜上刷新了分数,一举跃居榜首:
- 在文本、Web 开发与视觉竞技场中均稳居第一;
- 在硬提示、编程、数学、创造力、长查询等多个赛道同样拔得头筹。
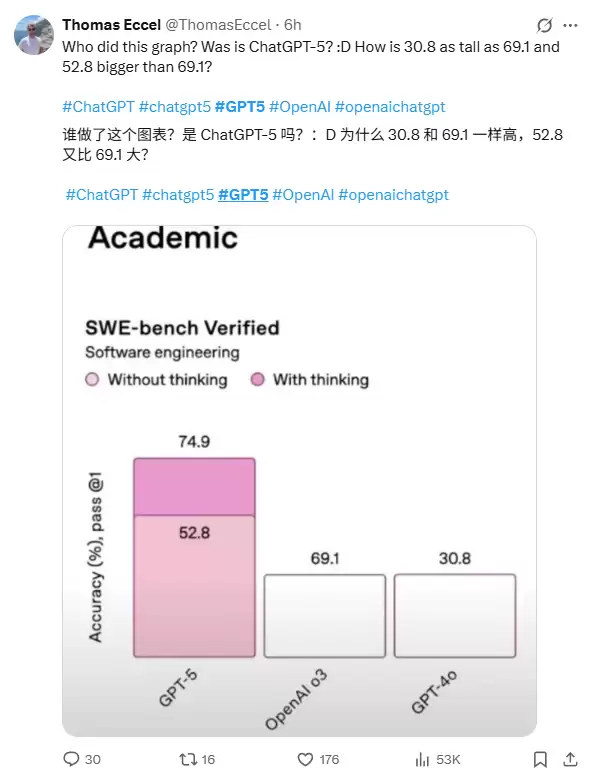
不过,发布会上 GPT-5 生成的图表却闹了个乌龙:52.8 比 69.1 大?30.8 和 69.1 一样高?这样的图表着实让人看得一头雾水。
这真的是 Sam Altman 口中“OpenAI 有史以来最聪明的模型”吗?带着这个疑问,我们第一时间进行了实测。结果发现,除了编程能力还算不错,其他方面的表现多少有些令人失望。不少测试者感叹:还是把 GPT-4o 还给我们吧。
01. 一手实测
case 1 经典易错题
先来一道经典的“陷阱题”热热身:
提示词:9.9和9.11谁大

GPT-5 回答:9.11 比 9.9 大,理由是比较数字时先看整数部分(都是 9),再看小数部分,11 大于 9。它还补充道,如果指的是日期,那么 9 月 11 日比 9 月 9 日晚。这个经典的数学推理错误再次暴露了模型在基础逻辑上的短板。
case 2 编程
提示词:写一个 ja vascript 代码,显示一个小球在旋转的正六边形内弹跳。球应该受到重力和摩擦力的影响,它必须从旋转的墙壁上真实地弹起,用 ja vascript 和 html 实现它
从生成的结果看,整体效果尚可,能够看出小球受到了重力和摩擦力的作用。不过,弹跳的物理反馈感不算特别突出,仍有提升空间。
case 3 图像生成
提示词:将图片里的内容翻译成中文,需要通俗易懂引人入胜,不改变原意,不要凭空添加没有的内容。

我们对比了几款主流模型的翻译效果,大家可以看看哪个更合心意。
Gemini 2.5 Pro 的翻译:

豆包的翻译:

GPT‑5 的翻译:

对比来看,Gemini 2.5 Pro 的翻译最为通顺自然,语言颇具“人味儿”;豆包的翻译准确但略显平淡;GPT‑5 的翻译水平与豆包相近,但与 Gemini 2.5 Pro 相比,在流畅度和生动性上存在肉眼可见的差距。对于需要高质量文本输出的用户来说,这一点值得关注。
case 4 前端
提示词:生成一个
番茄钟
的网页应用,包含以下功能:- 目标:计时器 + 会话记录。- 功能:自定义时长、自动启动选项、会话图表(SVG)、声音警报(提示音)、暗黑模式。- 界面应该适合日常使用,并能给用户一些活力!
GPT‑5 生成的番茄钟页面,整体审美在线,计时、暂停等按钮功能完整。但页面上那个巨大的环形设计,其用意实在让人有些费解,可能影响了实际操作的直观性。
相比之下,Gemini 2.5 Pro 生成的页面功能同样完整,只是界面略显简陋,布局和色彩搭配不如 GPT‑5 美观。不过,功能易用、稳定可靠才是硬道理,在这方面 GPT‑5 仍有改进空间。
02. 一些分享
经过这一轮实测,GPT‑5 在“幻觉”问题上是否有所改善尚不确定,但其在部分基础任务上的表现,确实让人感觉“智商”似乎不增反降。文案生成能力不仅没有显著增强,甚至在某些方面还不及之前的 GPT‑4o,这对于期待迭代升级的用户来说无疑是一种落差。
编程能力算是中规中矩,当然,这可能与测试时使用的提示词复杂度有关。前端页面的审美感有所提升,但偶尔还是会冒出一些小 BUG,稳定性有待加强。
需要说明的是,以上测试均为“一次性”生成,没有经过多次反复尝试。但话说回来,用户在实际使用中,也不可能每次都恰好避开模型的“雷区”。因此,这一评测结果对日常使用具有一定参考价值。
总而言之,这次发布会带来的期待,似乎被实际体验冲淡了不少。GPT‑5 目前已正式上线官网,面向所有用户开放。免费版用户每 5 小时可发送 10 条消息,Plus 版用户每 3 小时可发送 80 条消息。感兴趣的朋友,不妨亲自去试试看,感受一下这款“最聪明模型”的真实表现。




