差分进化算法(Differential Evolution, DE)作为进化算法家族中的独特成员,自1995年由Storn和Price提出以来,凭借其结构简洁、参数少量且性能强劲的特点,在连续函数优化领域始终占据领先地位。本文将从算法原理、执行步骤、优劣势分析、实际应用及改进方向等多个维度,全面解析这一经典优化方法的核心机制与应用价值。

1 算法原理
核心思想
DE的灵感源自遗传算法,但创新性地采用了“差分变异”机制。其基本流程是:从当前种群中随机选取两个个体,计算它们的向量差,并用该差值对第三个个体进行扰动,从而生成变异个体;随后将变异个体与目标个体进行交叉操作,得到试验个体;最后通过一对一贪婪选择,保留适应度更优的个体。这种基于向量差的变异方式使算法能够自适应调整搜索步长与方向——种群分散时(搜索初期)进行全局探索,种群收敛时(搜索后期)转向精细搜索,展现出极高的智能性。
数学描述
假设搜索空间为D维,种群规模NP通常设为5D至10D。第t代种群可表示为:

每个个体代表一个候选解。
核心操作
DE的三个核心操作:变异、交叉、选择。
变异操作
对于每个目标个体\(x_i^t\),生成对应的变异向量\(v_i^{t+1}\)。最经典的策略是DE/rand/1:
(公式略,原文保留)
其中,r1、r2、r3是从{1,2,...,NP}中随机选取的三个互不相同且不等于i的索引;F为缩放因子(通常取0.5),控制差分向量的放大倍数;\((x_{r2}^t - x_{r3}^t)\)即为差分向量,反映种群中个体间的差异信息。
其他常见的变异策略还包括多种变体:

交叉操作
将目标个体\(x_i^t\)与变异向量\(v_i^{t+1}\)混合,生成试验向量\(u_i^{t+1}\)。最常用的是二项式交叉:
(公式略,原文保留)
其中j为维度下标,CR为交叉概率(取值范围0到1),控制试验向量中来自变异向量的比例。CR越大,变异贡献越多。此外,随机维度\(j_{rand}\)确保试验向量至少有一维来自变异向量,避免与目标向量完全相同。
选择操作
采用一对一贪婪选择机制:比较试验向量\(u_i^{t+1}\)与目标个体\(x_i^t\)的适应度值(以最小化问题为例)。若试验个体更优,则替换原个体;否则保留原个体。该机制确保种群持续向更优方向进化,且永不退化。
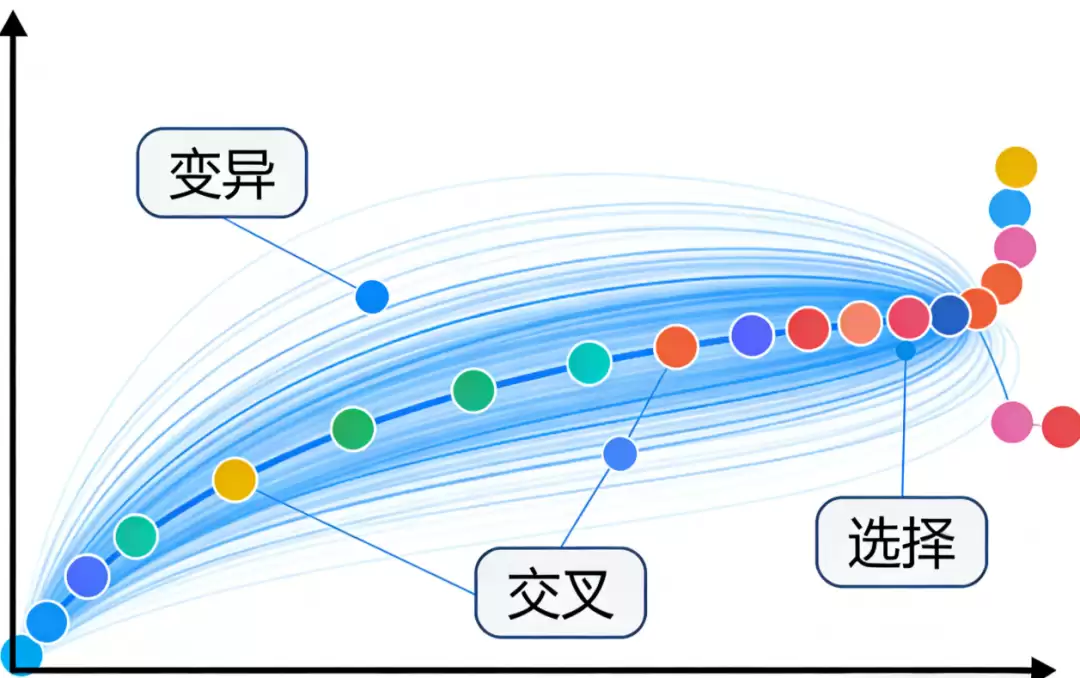
2 执行步骤
标准DE算法流程(以DE/rand/1/bin为例):

若达到最大迭代次数\(G_{max}\)或最优解满足精度要求,则输出最优解\(x_{best}\)及其适应度值;否则返回步骤2。
流程图如下(代码表示):
开始 ↓
初始化种群 (NP, F, CR, Gmax) ↓
计算初始适应度,记录最优个体 ↓
┌────────────────────────────────────┐
│ for t = 0 to Gmax-1 │
│ ↓ │
│ for each 个体 i in 种群 │
│ ↓ │
│ 随机选择 r1≠r2≠r3≠i │
│ ↓ │
│ 变异: v = xr1 + F*(xr2 - xr3) │
│ ↓ │
│ 交叉: 生成试验向量 u │
│ ↓ │
│ 选择: 若 f(u) ≤ f(xi) 则替换 │
│ └──────────┬───────────────────────┘
│ ↓ │
│ 更新全局最优个体 │
└──────────────┬───────────────────────┘
↓
输出最优结果 ↓
结束
3 优劣势分析
优点
结构简单,易于实现——核心代码通常仅需几十行,无复杂操作。
控制参数少:仅包含NP、F、CR三个主要参数,调参相对便捷。
鲁棒性强:在多种测试函数上表现稳定,对问题的数学性质(连续/不连续、可导/不可导)要求低。
收敛速度快:差分变异能有效利用种群分布信息,自适应调整搜索步长,前期探索与后期开发平衡良好。
记忆能力:通过种群保存历史信息,无需梯度信息。
并行性:个体操作独立,适合并行计算。
缺点
参数敏感:虽然参数少,但F和CR的设置对性能影响显著,不同问题需针对性调整。
易陷入局部最优:尤其在处理复杂多峰函数时,可能出现早熟收敛。
收敛停滞问题:当种群多样性丧失(个体聚集)时,差分向量变小,搜索陷入停滞。
对高维问题扩展性有限:随着维度增加,所需种群规模和迭代次数急剧上升。
离散优化能力弱:标准DE面向连续空间设计,处理离散或组合优化需特殊离散化方法。
无显式多样性维持机制:不同于NSGA-II的拥挤度距离,DE的多样性依赖差分变异本身,后期可能丢失。
4 应用场景
DE因高效鲁棒,被广泛应用于各类连续优化问题:
1. 工程参数优化
典型问题包括:机械设计参数优化(弹簧设计、压力容器设计、焊接梁设计),电路元件参数整定(滤波器设计、PID控制器参数优化),天线设计(优化天线几何参数以达最佳辐射性能)。
案例:某航空发动机涡轮叶片冷却结构参数优化,使冷却效率提升12%,同时满足温度约束。
2. 神经网络训练
典型应用是优化神经网络的权重和阈值,替代梯度下降。优势在于避免陷入局部极小,适用于前馈神经网络、径向基函数网络等。
案例:股票价格预测中,用DE优化LSTM网络的超参数(层数、神经元数、学习率),预测精度提高8%。
3. 电力系统优化
典型问题包括:经济负荷分配(最小化发电成本,满足负荷需求),无功功率优化(降低网损,提高电压稳定性),分布式电源选址定容。
案例:某区域电网的机组组合优化,采用DE算法,年发电成本降低约1500万元。
4. 图像处理与模式识别
典型应用:图像分割阈值优化(多阈值分割),图像配准参数优化,特征选择(从高维特征中选出最优子集)。
案例:医学图像分割中,用DE优化模糊C均值聚类参数,分割精度达到95%以上。
5. 化工过程优化
典型问题:化学反应器参数估计,分离过程操作条件优化,工艺参数整定。
案例:某精馏塔操作参数优化,使产品纯度提高2%,能耗降低5%。
6. 数据挖掘与机器学习
典型应用:聚类分析(优化聚类中心),分类器参数优化(如SVM的核参数和惩罚因子),关联规则挖掘。
案例:用DE优化SVM参数,用于信用卡欺诈检测,准确率提升3.5%。
7. 多目标优化扩展
典型算法:DEMO(Differential Evolution for Multi-objective Optimization)、NSDE(基于DE的NSGA-II变体)。
应用:在DE框架中引入Pareto支配和外部存档,处理多目标问题。
案例:汽车车身轻量化设计(最小化重量,最大化刚度),获得均匀分布的帕累托前沿。
5 改进变体
为克服标准DE的缺点,研究者们提出了多种改进版本:
| 变体名称 | 改进策略 | 适用场景 |
|---|---|---|
| SaDE(自适应DE) | 自适应调整F和CR | 复杂多峰优化,减少参数调试 |
| JADE | 采用当前最优信息,自适应F,可选外部存档 | 收敛快,多样性保持好 |
| CoDE(复合DE) | 组合多种变异策略和参数 | 提高鲁棒性,适合不同类型问题 |
| Hybrid DE | 与局部搜索算法(如单纯形法)结合 | 需要高精度解的工程问题 |
| 多目标DE | 引入非支配排序和拥挤度距离 | 多目标优化问题 |
6 总结
差分进化算法是一种基于向量差分的简单而强大的进化算法。它通过随机选取种群中的个体生成差分向量,对目标个体进行扰动,实现自适应搜索。结构简洁、参数少、鲁棒性强,这些优势使DE在连续优化领域成为首选算法之一。
与粒子群算法(PSO)相比,DE的变异基于种群中其他个体的向量差,而PSO依赖个体历史最优与全局最优;与遗传算法(GA)相比,DE的变异步长和方向由种群分布自适应确定,而GA通常采用固定概率的交叉变异。这些特性使DE在处理高维、非线性、不可导的复杂连续优化问题时表现出色。从工程优化到机器学习,从图像处理到电力系统,它都在实实在在地发挥作用。当然,没有算法是完美的,理解其局限才能更好地应用。
```



