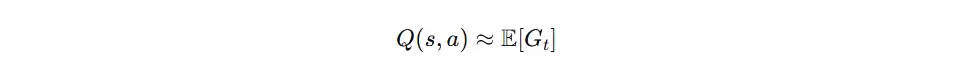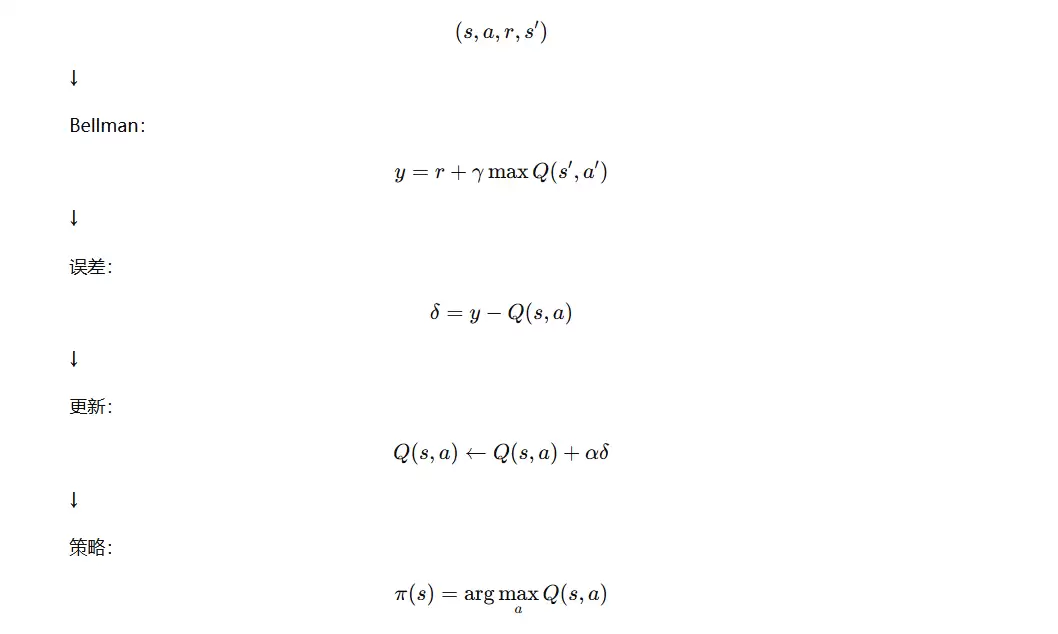Q-learning算法的基础认识
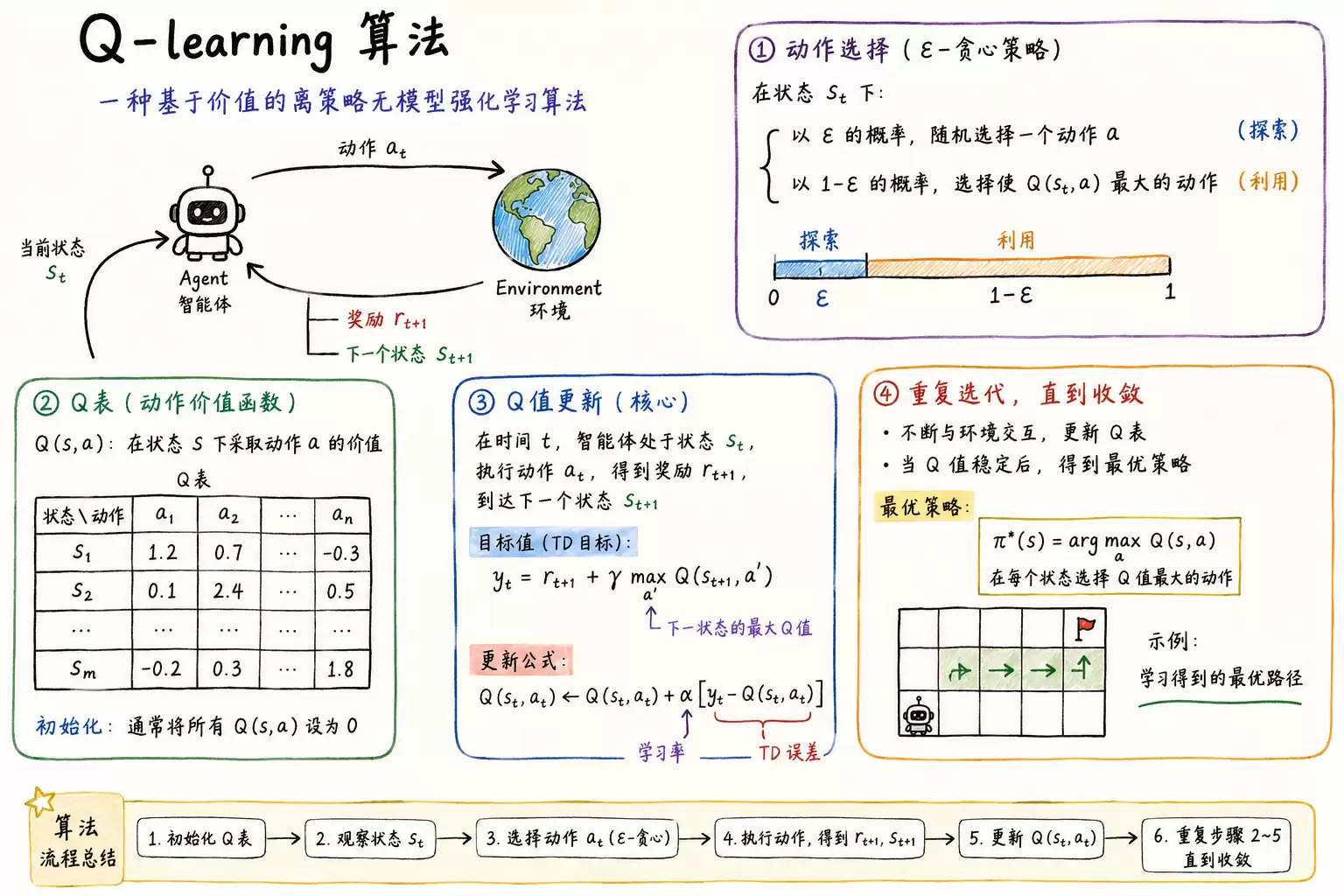
Q-learning 是一种基于价值的离线无模型强化学习算法。它通过持续学习动作价值函数来辅助决策,无法直接优化策略本身,因此对连续动作空间的适应能力有限。其核心机制是维护一张 Q 表,用于存储各状态-动作对的价值,并利用时序差分规则进行迭代更新,同时结合 ε-贪心策略在探索与利用之间取得平衡。折扣因子与学习率是影响训练效果的关键超参数。该算法在每次与环境单步交互后即完成更新,逻辑简洁、易于实现,然而当状态空间或动作空间较大时,Q 表规模容易发生指数级增长,导致“维度灾难”问题。

基础 Q-learning 结构
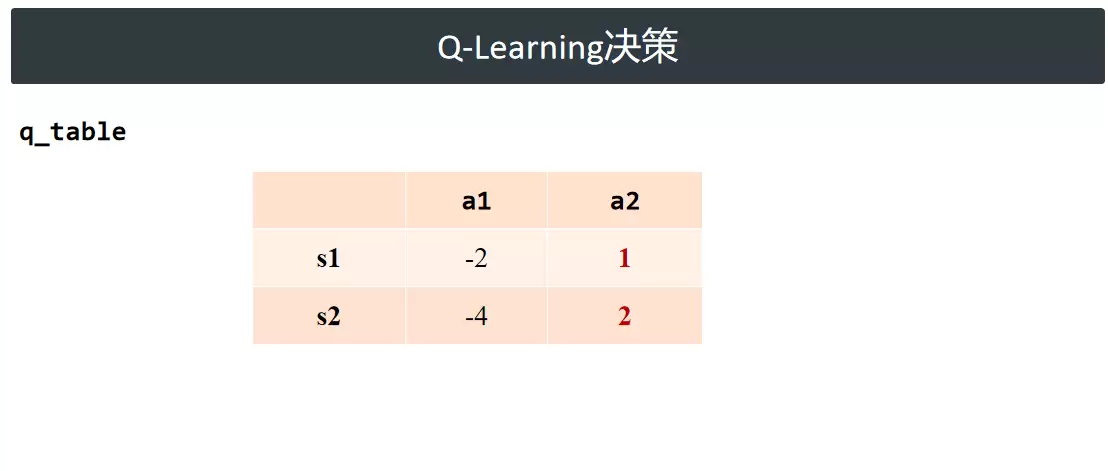
Q-Learning决策
Q-Learning 基于动作价值函数进行决策,核心操作为在 Q 表中选取当前状态下价值最高的动作。举例说明:假设智能体当前处于状态 s1,可选动作 a1 和 a2,查表得 Q(s1, a1) = -2,Q(s1, a2) = 1,显然 a2 的预期回报更高,因此选择 a2。执行该动作后,状态转移至 s2,接着重复查表、比较 Q 值、择优选择的完整流程。智能体持续跟随新状态循环执行该逻辑,直至任务终止。
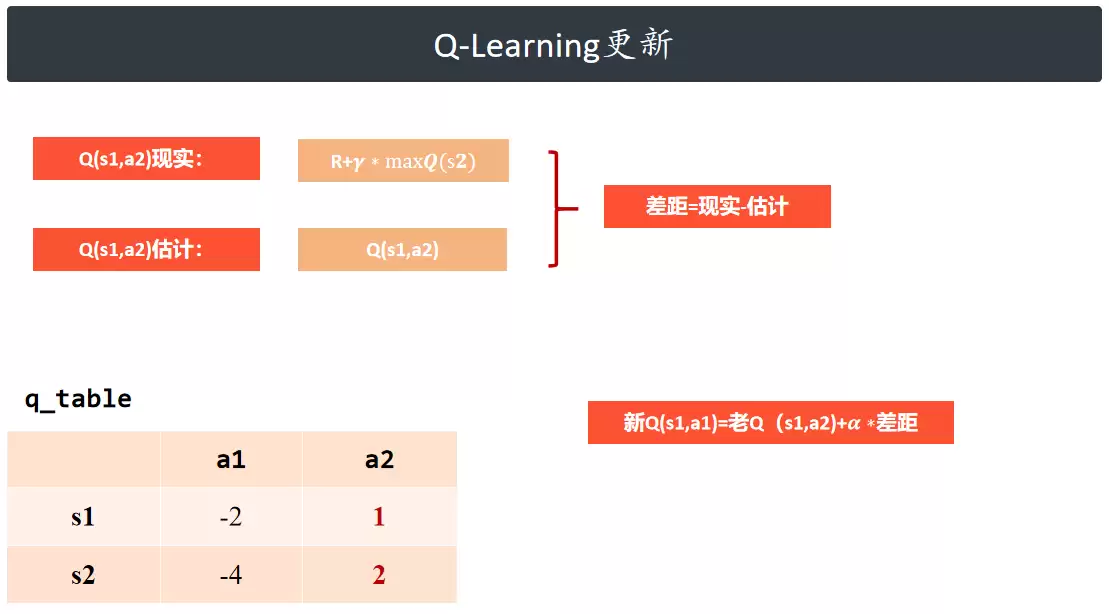
Q-Learning 更新
任一动作的总价值由当前即时奖励与后续状态的长期累积收益共同决定。
- 估计值:Q 表中记录的 Q(s1, a2),表示在当前状态下执行该动作的预估总价值。
- 真实目标值:即时奖励加上下一状态的最大动作价值;此处引入折扣因子 gamma,用于衰减远期收益的权重,反映未来奖励的不确定性。
算法超参数与决策策略:
- ε-greedy 策略:用于动作选择。例如 ε=0.9 时,智能体有 90% 的概率依据 Q 表选择最优动作,10% 的概率随机选取动作,从而有效平衡探索与利用。
- 学习率 alpha:取值小于 1,控制单次更新时误差修正的步长,影响收敛速度与稳定性。
- 折扣因子 gamma:对未来奖励进行衰减,决定智能体对长期收益的重视程度,值越大越关注远期回报。
手动计算过程
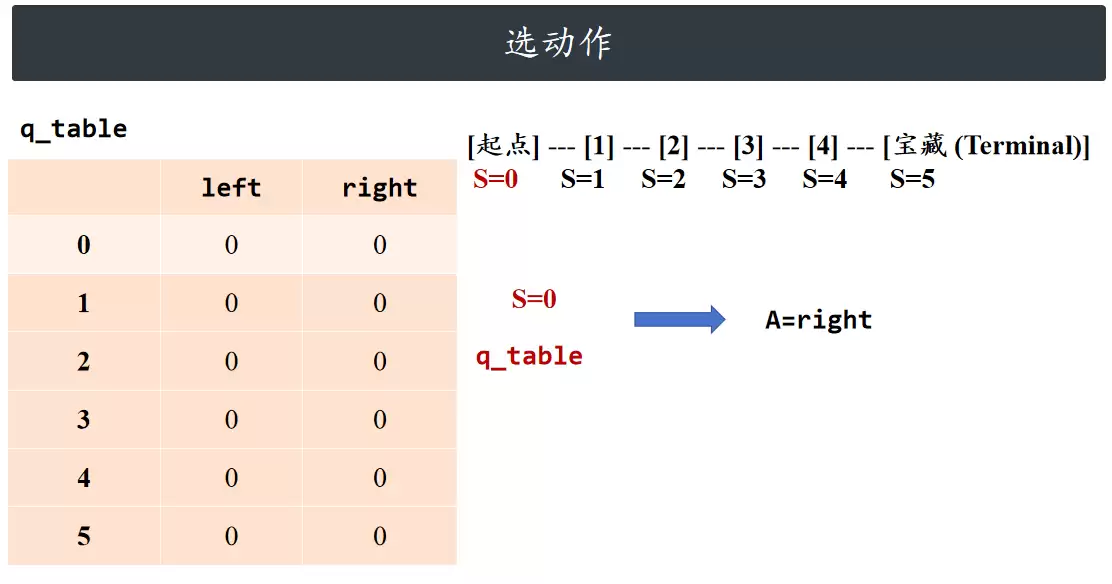
选动作
依据当前所处状态和 Q 表格,为智能体选择动作。
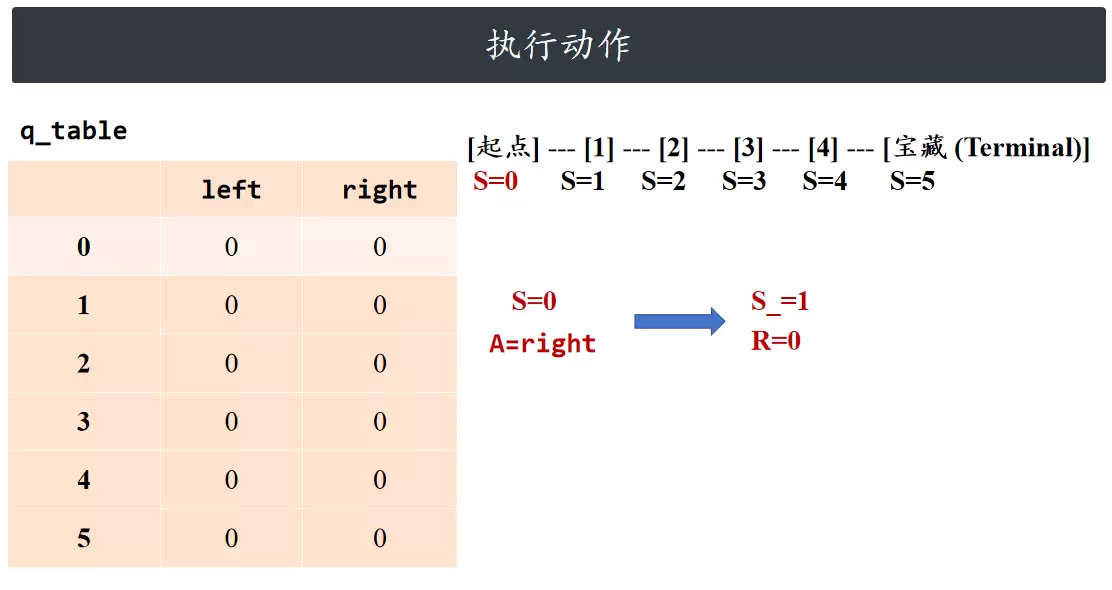
执行动作
根据当前状态与所选动作,环境反馈即时奖励并返回下一个状态。
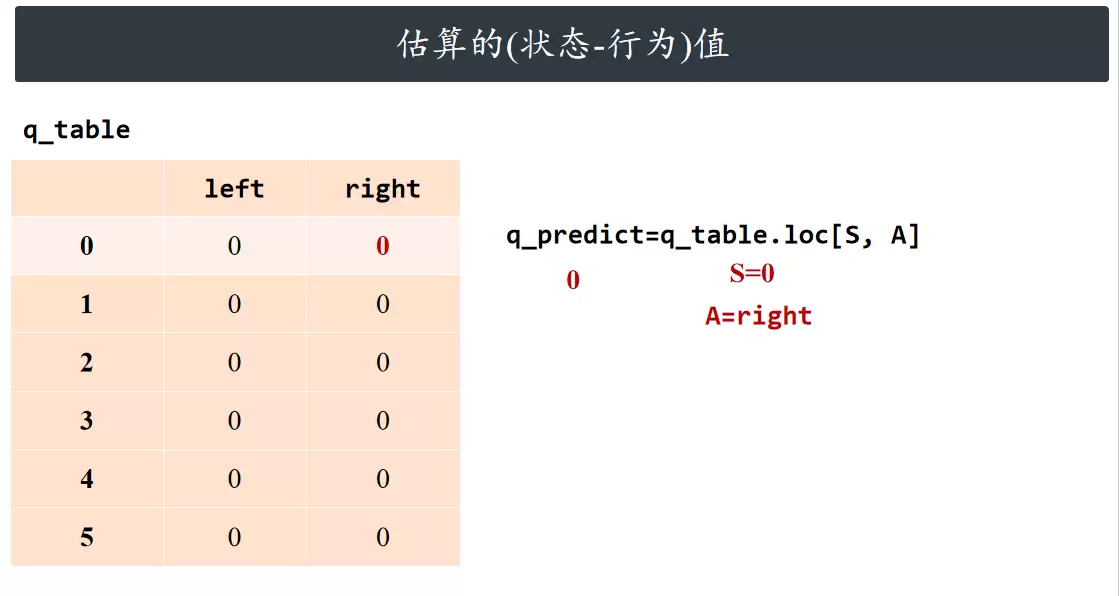
估算的(状态-行为)值
计算当前动作对应的动作价值估计值。
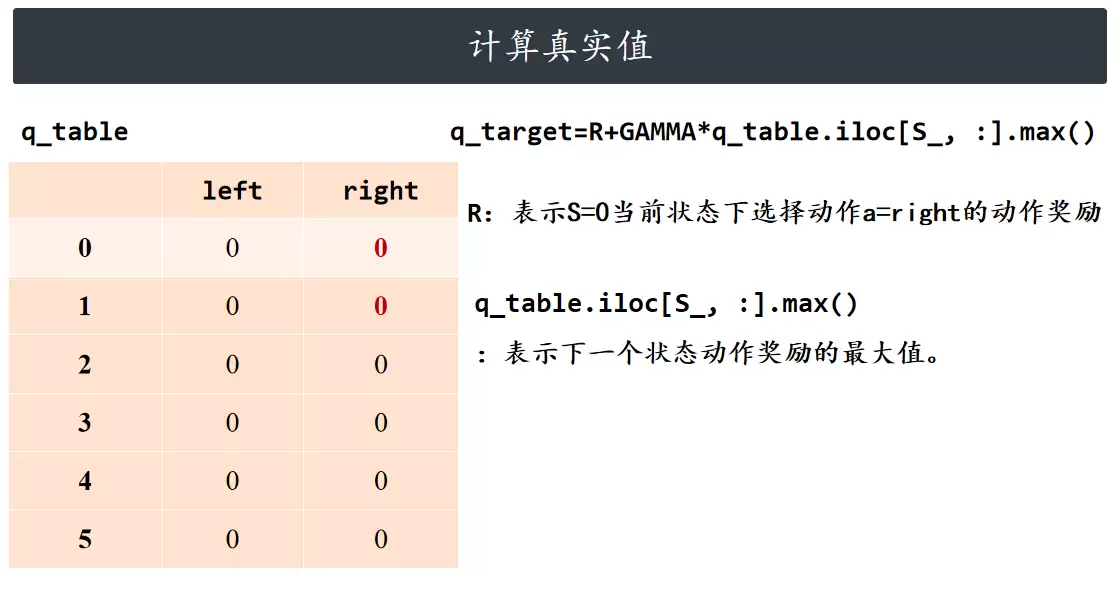
计算真实值
计算当前动作动作价值的真实目标值(基于下一状态的最大动作价值)。
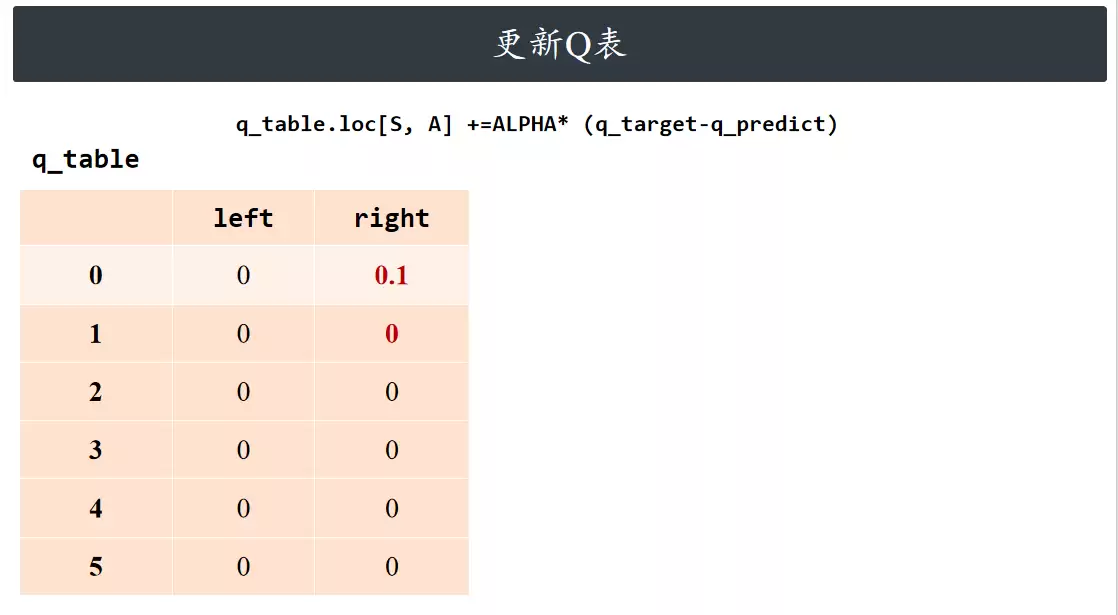
更新Q表
更新当前状态-动作对的动作价值函数,即 Q 值。
数学公式
动作价值函数(Q函数)
动作价值函数(Q 函数)定义为在状态 s 下采取动作 a 后,未来所能获得的累计回报期望值。
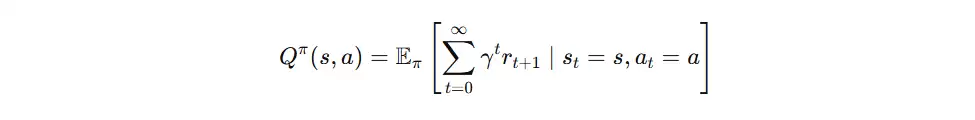
Bellman 最优方程
Q-learning 的理论基石是 Bellman 最优方程,公式如下:
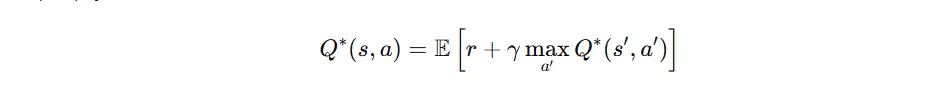
当前动作价值由当前奖励与下一状态的最大价值之和构成。通过持续迭代,Q 值逐步逼近最优 Bellman 解。
TD目标(Temporal Difference Target)
Q-learning 每次更新所使用的目标值称为 TD Target(时序差分目标),它代表当前样本所认知的“正确 Q 值”。
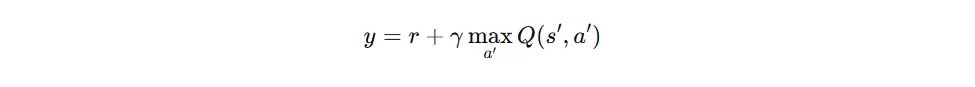
TD误差(Temporal Difference Error)
TD 误差(时序差分误差)指当前 Q 值与目标 Q 值之间的差值,用于衡量预测的偏差。
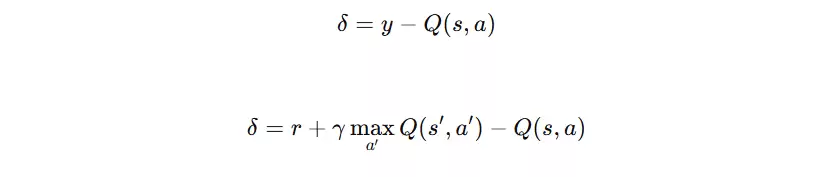
Q-learning 更新公式
Q-learning 更新公式遵循“新 Q 值 = 旧经验 + 新经验”的原则,通过引入学习率进行加权融合。
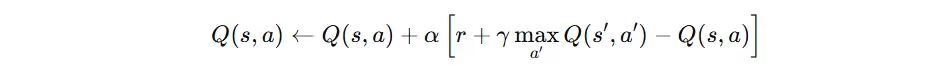
最优策略公式
最优策略为在每个状态下选择 Q 值最大的动作,即贪心策略。
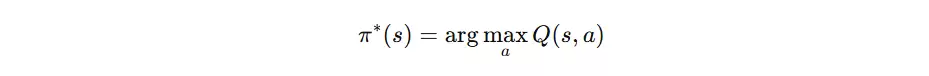
ε-greedy 探索策略
训练过程中若始终采用贪心策略,容易陷入局部最优,因此引入 ε-greedy 探索策略,以一定概率随机探索。
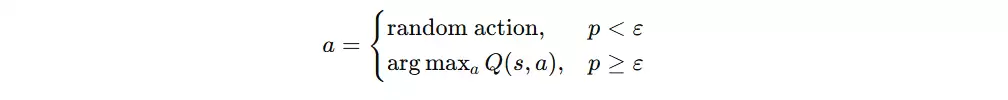
奖励累计公式(Return)
Q-learning 的最终优化目标为最大化累计奖励,公式如下:
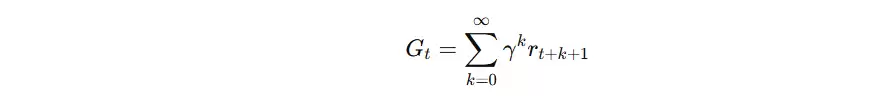
Q-learning 最终学得的策略可概括为:在每个状态下选择 Q 值最高的动作。随着训练推进,Q 表逐渐收敛至最优 Q 值。