SARSA算法是一种基于价值的在线无模型强化学习算法。它主要依靠动作价值函数来指导决策,无法直接优化策略,因此在连续动作空间较大时适用性有限。该算法采用Q表存储状态-动作价值,并基于当前回合中实际执行的动作进行时序差分更新。同时,它利用ε-贪心策略平衡探索与利用,通过折扣因子和学习率调节参数,每步交互即可完成迭代。整体上,SARSA训练风格较为保守,稳定性高,但探索能力较弱;当状态和动作空间增大时,同样面临Q表维度爆炸的问题。

基础SARSA结构
SARSA算法的决策
SARSA算法的决策过程基于动作价值函数与ε-贪心策略。例如,假设当前处于状态s1,存在动作a1和a2,首先查询Q表获取对应的Q值,然后利用ε-贪心策略选择当前要执行的动作。执行后状态切换至s2,再以同样的ε-贪心策略选出s2下的实际动作。如此循环,全程采样真实动作并执行交互,逐步完成训练。
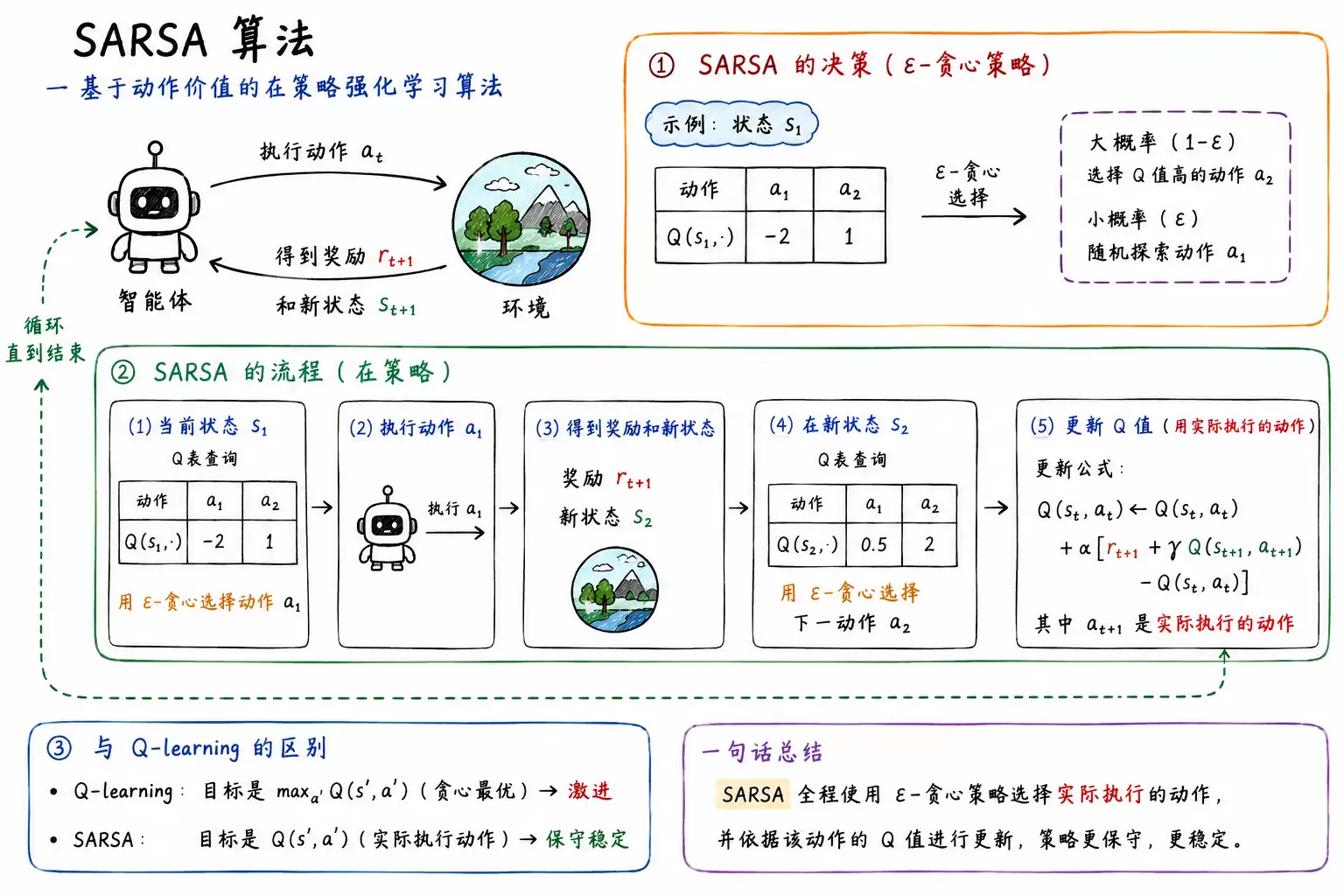
SARSA算法的更新
Q-learning:选择最大 Q 值(贪心最优),激进大胆
SARSA:选择实际执行动作(ε 贪心随机),保守稳定
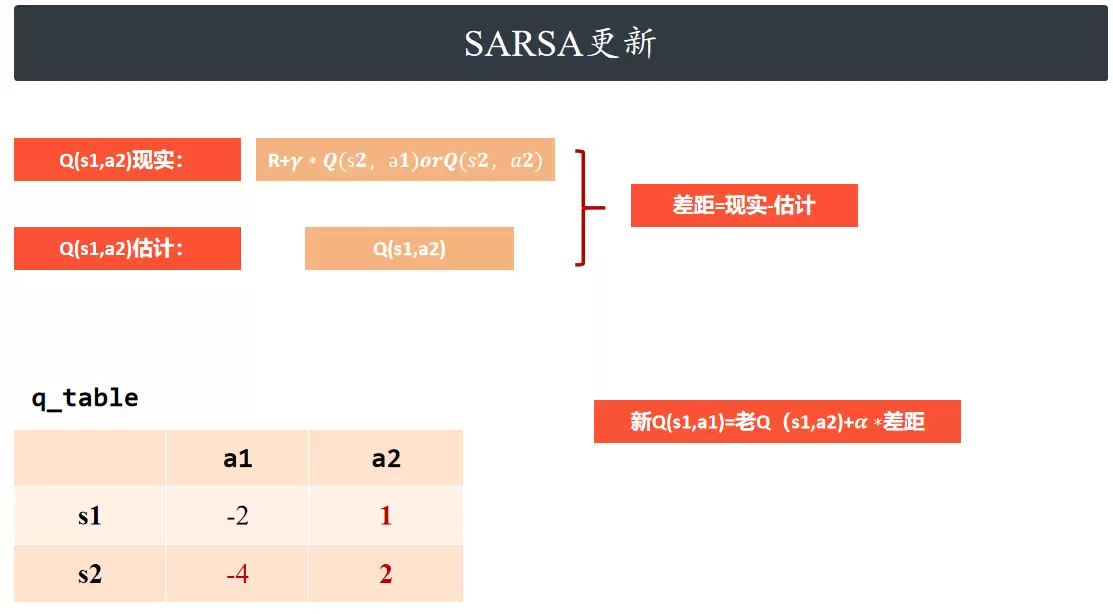
SARSA基于时序差分进行Q值更新。智能体在状态s1按照贪心策略选择动作a1,执行后获得奖励r并进入状态s1,再以相同策略选出下一动作a2,然后利用两组状态与动作的Q值迭代更新Q(s1, a2),循环此过程直至训练结束。
手动计算过程
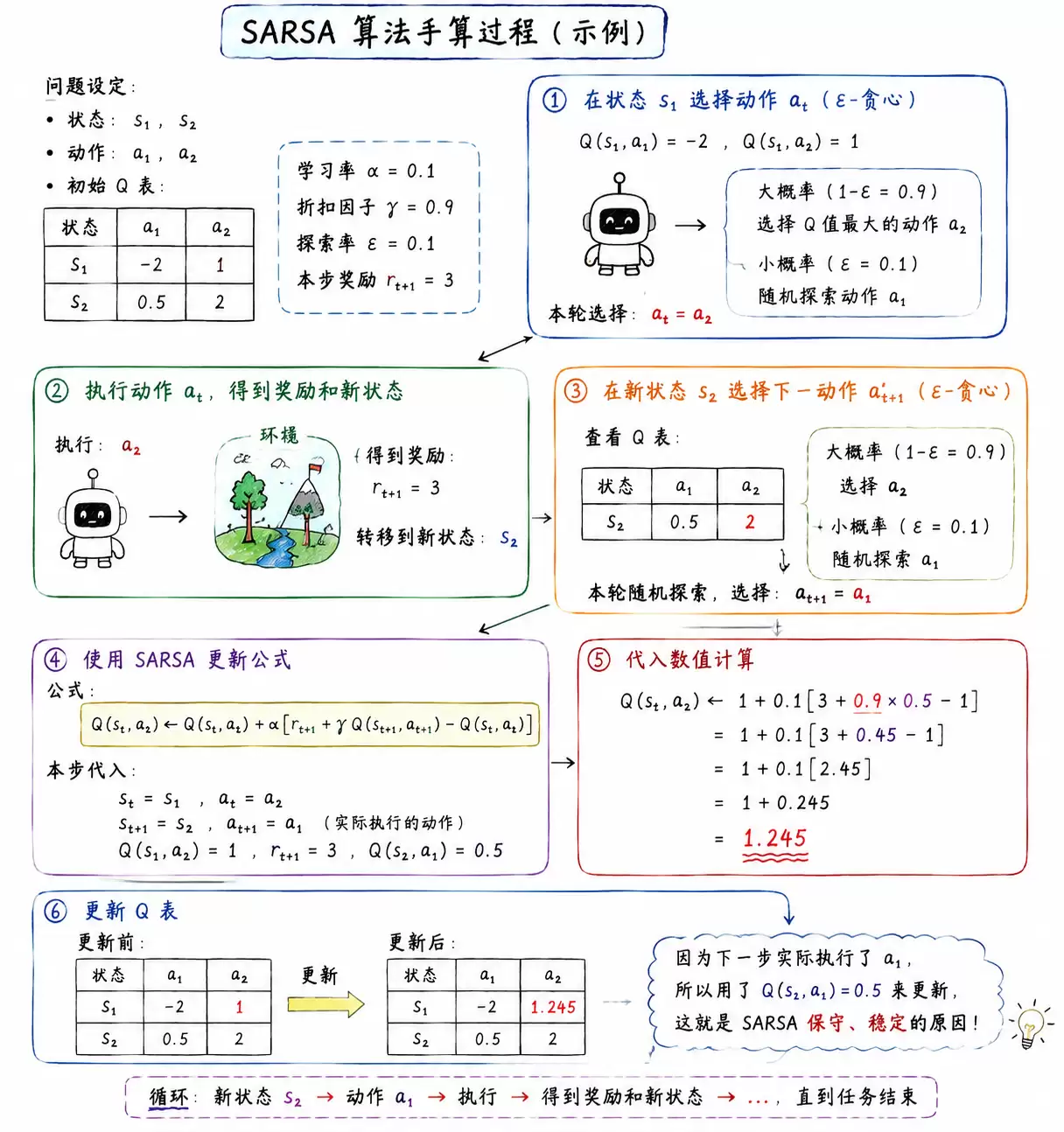
下面通过一个手动计算示例说明:首先,在当前状态s1下查询Q表,根据动作价值函数得到各动作对应的Q值,例如Q(s1,a1)=-2,Q(s1,a2)=1。随后,智能体采用ε-贪心策略选择动作——以大概率1-ε选取当前Q值较高的动作,以小概率ε进行随机探索。本例中,智能体最终选择了动作a2。执行后,环境返回即时奖励rt=3,同时系统从状态s1转移到新状态s2。
进入新状态后,SARSA并不直接选择最大Q值对应的动作,而是继续使用ε-贪心策略选出下一步真实要执行的动作。假设在状态s2中,虽然Q(s2,a2)=2大于Q(s2,a1)=0.5,但由于探索机制,本轮实际选择了动作a1。此时,SARSA利用真实执行动作对应的价值来更新Q值,依据以下更新公式
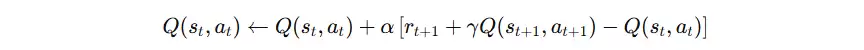
代入本例数值:
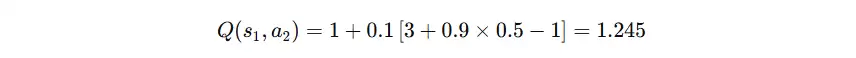
因此,Q(s1,a2)从1更新为1.245。随后,智能体在新状态中不断重复“选择动作—执行动作—获得奖励—更新Q值”的循环,直至任务结束。在整个过程中,SARSA始终依据下一状态中真实执行的动作进行学习,而非直接取最大Q值,这使得策略更新更加保守稳定,安全性和鲁棒性俱佳。