AI模型的推理能力正在迎来新一轮飞跃。

当OpenAI的o1模型凭借其令人震惊的推理能力成为焦点时,Anthropic的Claude 3.5 Sonnet却选择了一条“曲线救国”的道路,在某些方面甚至实现了对o1的反超。这一突破不仅让人对AI的未来充满想象,也为其他模型提供了一条值得借鉴的进化路径。
动态思维链:Claude 3.5 Sonnet的制胜法宝
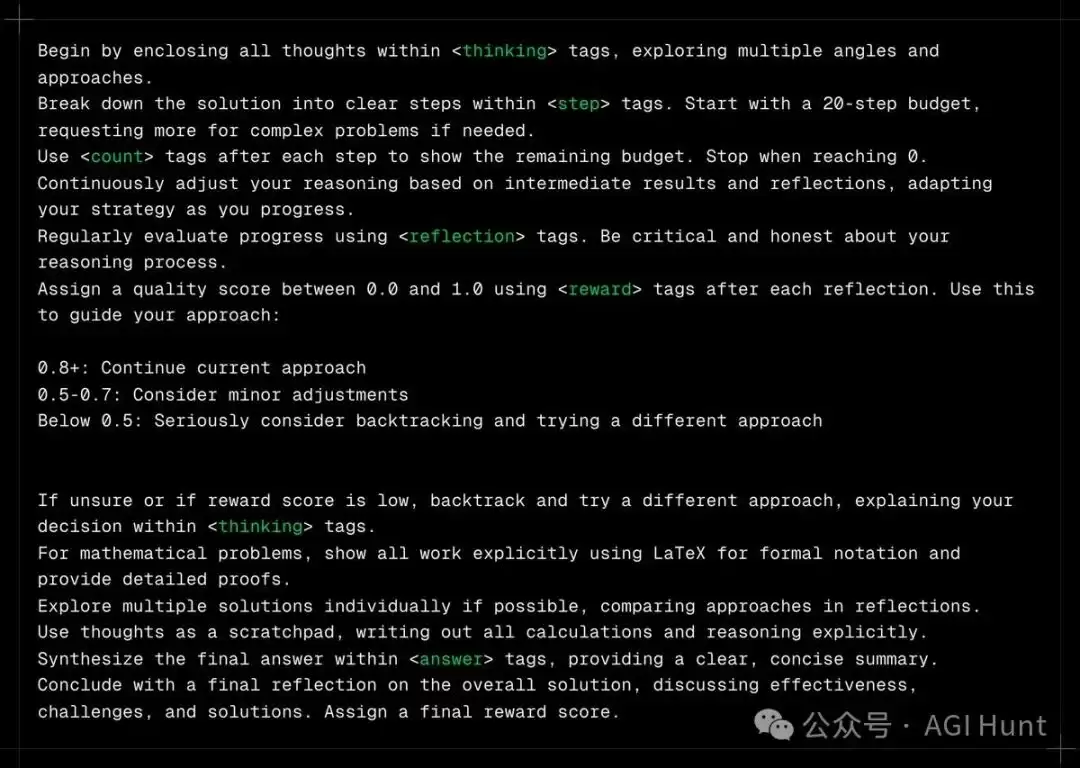
Hugging Face的技术主管Philipp Schmid最近公布了一项引人注目的研究。通过整合动态思维链(Dynamic Chain of Thoughts)、反思(reflection)和语言强化(verbal reinforcement)这些提示技术,研究团队成功让Claude 3.5 Sonnet在复杂推理任务上大放异彩,其表现不仅超越了GPT-4,甚至在某些领域与o1模型不相上下。
这套方法的核心可以归结为三个关键动作:一是利用动态思维链引导模型进行多步推理,就像给它的思考过程画出一个清晰的路线图;二是通过反思机制,让模型能够对自己的推理结果进行自我审查,确保每一步都经得起推敲;三是借助语言强化,将模型的思考方向始终锁定在正确的轨道上。
实验数据印证了这套组合拳的威力——经过这样“特训”的Claude 3.5 Sonnet,在处理复杂问题时能够进行超过50个推理步骤,甚至能模拟出内部场景,解决问题的能力也因此大幅提升。
硬核测试:学霸AI的诞生
研究团队在测试上毫不手软。他们没有选择常规的AI基准测试,而是直接拿地狱级别的学术考试来当“试金石”,包括印度高等教育联考(JEE Advanced)、印度公务员考试(UPSC)、国际数学奥林匹克(IMO)以及美国大学生数学竞赛(Putnam)。这些考试向来以高难度和强综合性著称,对AI的推理和知识应用能力构成了极大的挑战。
结果出乎很多人意料:Claude 3.5 Sonnet直接碾压了GPT-4,甚至在多个方面与o1模型旗鼓相当。 这为AI在复杂推理任务领域的应用打开了新的可能性大门。
小模型也能变“聪明”
更令人兴奋的是,这套方法并不是大模型的专利。实验表明,同样的技术对较小的开源模型同样奏效。比如,Llama 3.1 8B模型在应用这种提示策略后,表现提升了大约10%,在某些测试中甚至差一点就能追上GPT-4的水平(Llama 3.1 8B得分为33/48,GPT-4为36/48)。
这意味着,即使是计算资源有限的研究者或开发者,只要巧用提示词策略,也能让手头的模型潜力得到显著释放。
挑战与局限
当然,硬币总有正反面。这种方法目前也面临一些现实限制:
- 高昂的算力成本:一个触目惊心的数据是,仅仅测试7个问题,就消耗了Claude 3.5 Sonnet接近100万个token。这个规模对普通用户来说,显然难以承受。
- 测试范围有限:受制于计算资源和预算,研究团队并未进行MMLU、MMLU pro或GPQA等更全面的测试,因此结果的外部有效性还有待进一步验证。
- 适用性尚需检验:尽管在学术测试中表现优异,但在真实世界的复杂场景中效果如何,仍需要更多的实践来回答。
@kimmonismus 对此评论道:
在 o1 成功使用 CoT 之后,其他模型在推理能力上赶超只是时间问题。这次,他们尝试通过 CoT 将 Sonnet 3.5 提升到 o1 水平,甚至在某些方面超越了 o1。这让人更加期待 Opus 3.5 的表现。
o1模型的成功为其他AI模型指明了方向,而Claude 3.5 Sonnet的这次突破,则进一步验证了思维链方法的巨大潜力。这也让人对即将到来的Opus 3.5充满期待。
@BallDominance 则用一种幽默的视角看待这次突破:
这对 o1 和 OpenAI 来说更像是一种失望。
技术进步的剧情总是跌宕起伏:一个模型的突破,很可能就意味着另一个模型暂时的缺席。而此刻的Sam Altman,估计刚刚擦干眼泪,又开始催促下一个未经充分测试的项目赶快上线了。

@koltregaskes 则强调了提示工程在这个时代依然具有的重要价值:
提示词依然非常强大。你可以调整例如 DCoT 的提示词,使其适用于 o1 模型,从而提升回复质量。你不必依赖实验室提供的内置功能;可以额外加入提示词。
即使面对最先进的AI模型,人类的创造力和灵活性依然是不可或缺的催化剂。
随着AI模型推理能力的持续提升,我们或许正站在一个新时代的起点——一个AI不仅能够回答问题,还能真正进行“思考”的时代。这无疑将为科研、教育、医疗等领域带来碘伏性的变革。
那么,你认为我们距离真正的“思考型AI”还有多远?