可以看出,儿童绘本故事的整体运作流程大致如下:
整个流程中,核心其实只完成了两项任务:设定一个清晰明确的主题来定义需求,以及编排好完整的流程让应用顺利运行。至于构思文案、故事内容、图片生成、长音频合并等环节,都是围绕大模型在不同阶段的交付成果(构思和故事内容)进一步衍生出来的产物——换句话说,它们都是我们需求目标的延伸。
假如我们有一个基于大模型构建的程序,它能精准理解需求的内涵,然后将需求拆解成一个个小任务,最终组织整个任务的流程和依赖关系,并执行直至达成目标。那么,这个应用就是通常所说的Agent(智能体)。概括来说:大模型 Agent 是基于大语言模型(LLM)构建的、具备环境感知、自主理解、决策制定和执行能力的智能体。
这类 Agent 能够模拟独立思考的过程,调用各类工具,逐步逼近目标。从应用架构设计的角度来看,大模型 Agent 让我们从原先的“面向过程”架构(例如儿童绘本应用里的硬编码流程)转变为“面向目标”架构——提交需求后静待结果即可。它能处理相当复杂的目标任务,极大提升开发效率。
一般来说,大模型 Agent 由四个核心部分组成:规划、记忆、工具和行动。它们分别负责任务拆解与策略评估、信息存储与回忆、环境感知与决策辅助,以及将思维转化为实际动作。
还是以儿童绘本故事应用来举例:
- 规划:通过绘本主题,让大模型生成一本完整的绘本。Agent 需要先识别用户意图,然后进行任务拆分(构思、故事内容、插图、音频等),并制定处理流程。
- 记忆:包括主题、构思、故事等内容的记录,分为短期记忆和长期记忆。短期记忆主要用于上下文信息(比如多轮对话中关于绘本面向的年龄层、画风偏好等),长期记忆可能涉及用户特征,需要用特征数据库来存储。
- 工具:包括 API 调用、图片存储等,是 Agent 执行决策的辅助手段,帮助其与外部环境交互。
- 行动:将规划、记忆转化为具体输出的过程,执行中可能需要调用不同工具与外部环境进行交互。
接下来,我们看看几个常见的大模型 Agent 框架和应用案例。
Agent 框架简单介绍
目前开源和闭源的大模型 Agent 可谓百家争鸣、百花齐放:一个整理得很全的列表可以参考 awesome-ai-agents。
根据业务复杂度及实现方式的不同,Agent 框架大致可分为单 Agent 和多 Agent 两类。单 Agent 框架包括 BabyAGI、AutoGPT 等。这里重点介绍一个多 Agent 框架:MetaGPT(开源地址)。
MetaGPT 模拟了一家软件公司的组织架构,将多个 Agent 配置为不同角色,按照标准流程协作完成一个软件项目的全生命周期。它的目标就是:只要老板说一句话需求,从用户故事、竞品分析、需求文档到数据结构、API 设计,全部自动完成。内部多个 Agent 分别扮演产品经理、架构师、项目经理、研发工程师等角色,严格遵循标准化流程来推进业务。
MetaGPT 多智能体框架应用
接下来,我们来当一回老板:输入一句话需求,让 MetaGPT 帮我们实现目标。
第一步:环境准备
工欲善其事,必先利其器。建议用 Miniconda 来管理 Python 虚拟环境。Miniconda 的安装和使用可参考相关教程。
# 创建虚拟环境,名称:MetaGPT,Python版本:3.10
conda create --name MetaGPT python=3.10 -y
# 激活虚拟环境
conda activate MetaGPT
第二步:安装 MetaGPT 依赖
可以选择稳定版本或最新的研发版本(这里以稳定版本为例):
- 稳定版本:
pip install metagpt - 研发版本:
pip install --upgrade git+https://github.com/geekan/MetaGPT.git
如果希望 MetaGPT 能生成设计图(如类图、序列图),还需要安装 Node.js 包:sudo npm install -g @mermaid-js/mermaid-cli
第三步:配置大模型
大模型 Agent 离不开大模型底座。先初始化配置文件:metagpt --init-config。默认会在 ~/.metapgt/config2.yaml 生成配置。修改该文件,填上自己的大模型信息(以 Ollama 为例,其他模型配置类似):
llm: api_type: "ollama" model: "qwen2:7b" base_url: "http://127.0.0.1:11434/api" api_key: "EMPTY"
Ollama 的详细使用可参考其官方文档,此处不再展开。
第四步:当老板,一句话需求,静候结果
之前我们曾用大模型配合提示词完成过消消乐小游戏。今天想试试贪吃蛇,需求很简单:write a cli snake game
(MetaGPT) $ metagpt "write a cli snake game"
接下来就开始等待。在 MetaGPT 实现需求的标准流程中,每一步的输出都会清晰呈现。
首先,名为 Alice 的产品经理登场:根据老板需求,产出产品需求文档(PRD)。
有了 PRD,接下来是名为 Bob 的架构师:根据需求文档完成产品架构设计。
然后是名为 Eve 的项目经理:根据架构设计,整理研发任务。
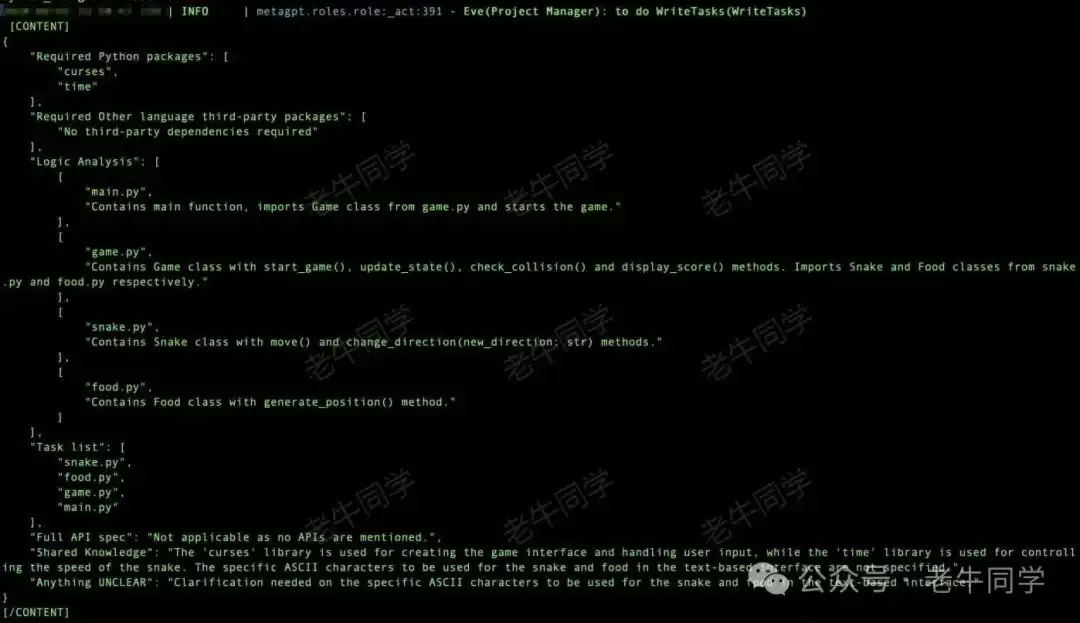
任务就绪,排期锁定资源,研发工程师开始开发:
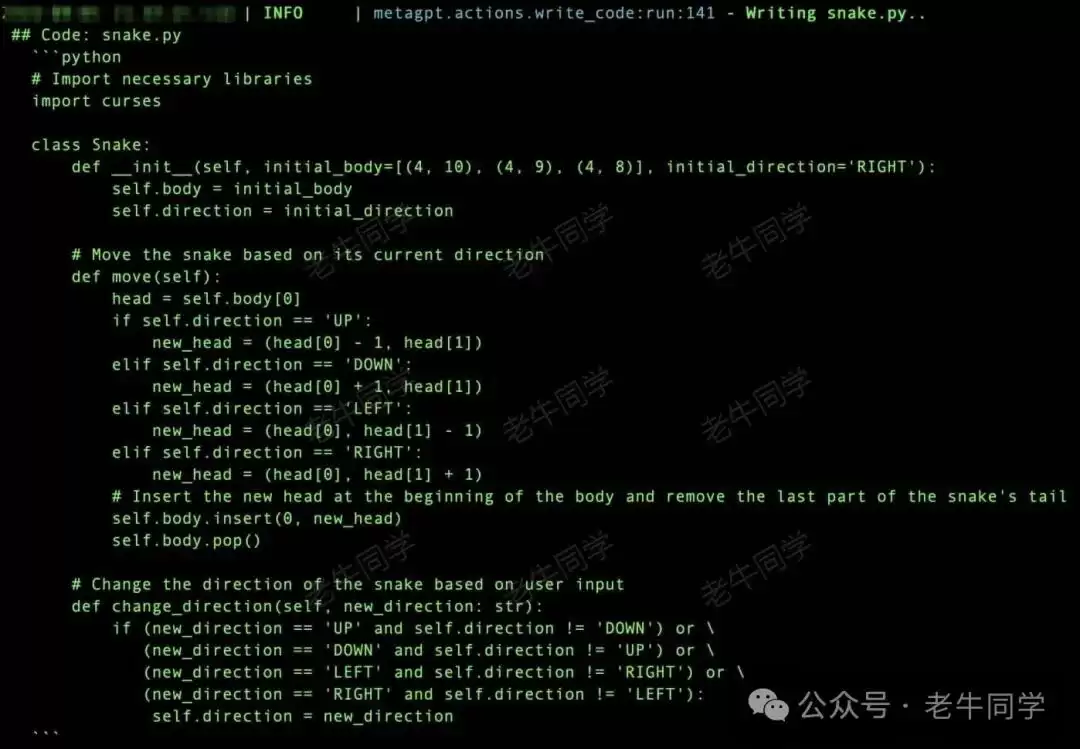
代码开发完成,进入代码 Review 环节:
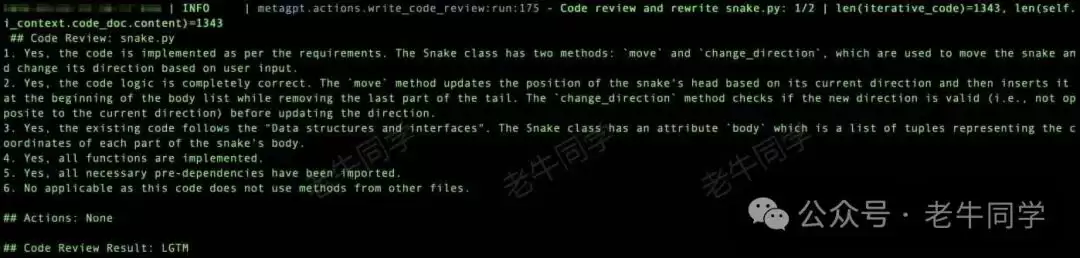
其他研发过程截图略过。经过多轮研发任务和 CR,终于完成整个需求,代码、文档等归档:
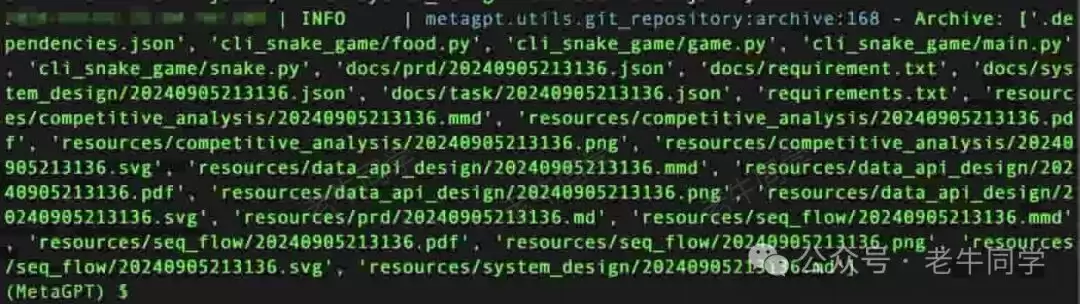
最终产出物如下:
- 代码源文件目录:
./workspace/cli_snake_game/cli_snake_game
(MetaGPT) $ tree
├── food.py
├── game.py
├── main.py
└── snake.py
- 项目实现文档目录:
./workspace/cli_snake_game/docs - 项目实现资源目录:
./workspace/cli_snake_game/resources
运行小游戏:python main.py。游戏确实能跑起来,但存在 Bug(比如蛇吃食物后自动退出,蛇撞墙异常退出)。
至此,MetaGPT 按标准流程帮我们完成了项目,但作为老板,并没有享受到完全的乐趣——还得自己去改 Bug。
最后,大模型 Agent 到底能解决什么问题?
上面用 MetaGPT 写出了一个有 Bug 的程序,显然不是理想结果。分析背后原因,其实并非大模型 Agent 本身的问题。
查看 MetaGPT 的源代码(roles 目录),核心逻辑在 role.py 文件(源码链接)。本质上,它仍然是通过 Prompt 提示词与大模型交互。大模型产出质量的好坏,直接决定了最终结果的优劣。
那么,大模型 Agent 在什么场景下更有优势?首先可以确定:那些底层大模型本身就擅长的领域。
- 复杂问题场景:大模型的设计初衷就是解决复杂问题。
- 需要多角色交互的场景:比如游戏故事生成、素材生成、内容创作,以及部分工作提效(如项目代码框架搭建等)。