Claude Opus 4.8 已正式上线——就在 5 月 28 日,Anthropic 将其同步推送至 API、App、Claude Code 以及各大云平台。这是当前 Claude 系列中能力最为强悍的模型,专为复杂推理、长周期智能体编码以及高自主性工作场景而打造。如果你已经在使用 Opus 4.7,升级仅需切换一行模型 ID。
先说几个核心判断:价格未涨,上下文窗口保持不变,真正带来变化的在于质量。Anthropic 的数据表明,Opus 4.8 在代码中遗漏缺陷的可能性比 4.7 低了大约四倍,面对未知信息时也变得更加诚实可靠。本指南将逐项拆解这些变化、获取方式,以及最实际的问题——到底值不值得切换。
简要总结
发布首日,有几个关键事实值得先记录下来:
- 模型 ID
claude-opus-4-8:同步登陆 Claude API、AWS、Vertex AI 和 Microsoft Foundry。 - 价格与 4.7 完全相同:标准模式下,每百万输入 token 5 美元,每百万输出 token 25 美元。
- 1M token 上下文、128K token 输出:这些规格参数没有变化,token 预算方案可以直接沿用。
除此之外,新增亮点包括:
- 全新的
effort参数,用于在响应深度和 token 效率之间取得平衡。 - 自适应思考,模型会自主判断每个请求需要思考到何种程度。
- Claude Code 中的动态工作流,一个会话可以启动数百个并行子智能体。
- 更高的诚实度和更高效的工具调用。
Opus 4.8 究竟有哪些全新变化
Opus 4.8 保留了 4.7 的规格参数,但底层模型做出了实质性改进。变化主要集中在四个方向。
代码质量。 模型能更频繁地发现并纠正自己的错误。Anthropic 的报告指出,与 4.7 相比,通过代码评审但未被察觉的缺陷减少了约四倍。对于智能体编码来说,这意味着生成的 diff 中静默 bug 大幅减少。
诚实度与对齐。 Opus 4.8 会更主动地标注不确定性,而不是给出未经证实的断言。Anthropic 还报告其欺骗行为和误用协作率低于 4.7。如果你运行的是无人值守的智能体,这种判断力的提升比单纯的基准测试分数更具实际意义。
工具调用。 模型选择工具的效率更高,无效调用明显减少,这在智能体循环中直接体现为延迟降低和 token 消耗缩减。
努力程度控制。 这是 API 层面最大的变化,值得单独展开详述。
努力程度控制:一个模型,五个档位
effort 参数允许你调节 Claude 消耗 token 的积极程度。它位于 output_config 内部,接受五个级别:low、medium、high、xhigh 和 max。在包括 API 和 Claude Code 在内的所有界面上,默认值为 high。
{"model": "claude-opus-4-8","max_tokens": 4096,"messages": [{"role": "user", "content": "Refactor this module."}],"output_config": { "effort": "xhigh" }}
关键之处在于:effort 会影响所有 token,不只是推理 token,还包括文本、工具调用和函数参数。较低的 effort 意味着更简洁的响应和更少的工具调用;较高的 effort 则对应更深入的分析和更彻底的执行。
Anthropic 的建议很直白:对于编码和智能体任务,从 xhigh 开始;多数重推理工作,high 是底线;只有在评估验证低级别仍能保持质量后,再降级到 medium 或 low。这个思路清晰且实用。
自适应思考取代手动预算
Opus 4.8 带来了自适应思考。你只需设置 thinking: {type: "adaptive"},模型就会自行判断每个请求是否需要推理、需要推理到什么程度。在 high、xhigh 和 max 努力级别下,它几乎总是会进行深度思考;在较低级别下,简单问题可能会跳过推理过程。
需要注意一个迁移点:Opus 4.8 不支持使用 budget_tokens 的手动扩展思考,如果沿用旧模式会返回 400 错误。如果你是从旧版 Opus 迁移过来,请改为自适应思考配合 effort 参数。
Claude Code 中的动态工作流
这次最引人注目的新功能之一是集成在 Claude Code 里的动态工作流。它允许单个会话启动数百个并行子智能体来处理大型、分支式的任务。底层的实现机制是 xhigh 努力级别与对话中途系统消息的结合——Messages API 现在支持在对话中途插入系统条目,而不只是在对话开始时。
这种中途干预的能力,赋予了编排智能体在任务展开时动态生成工作节点的权限。如果你对底层机制和如何通过原始 API 构建类似编排模式感兴趣,可以查阅相关的深度解析。
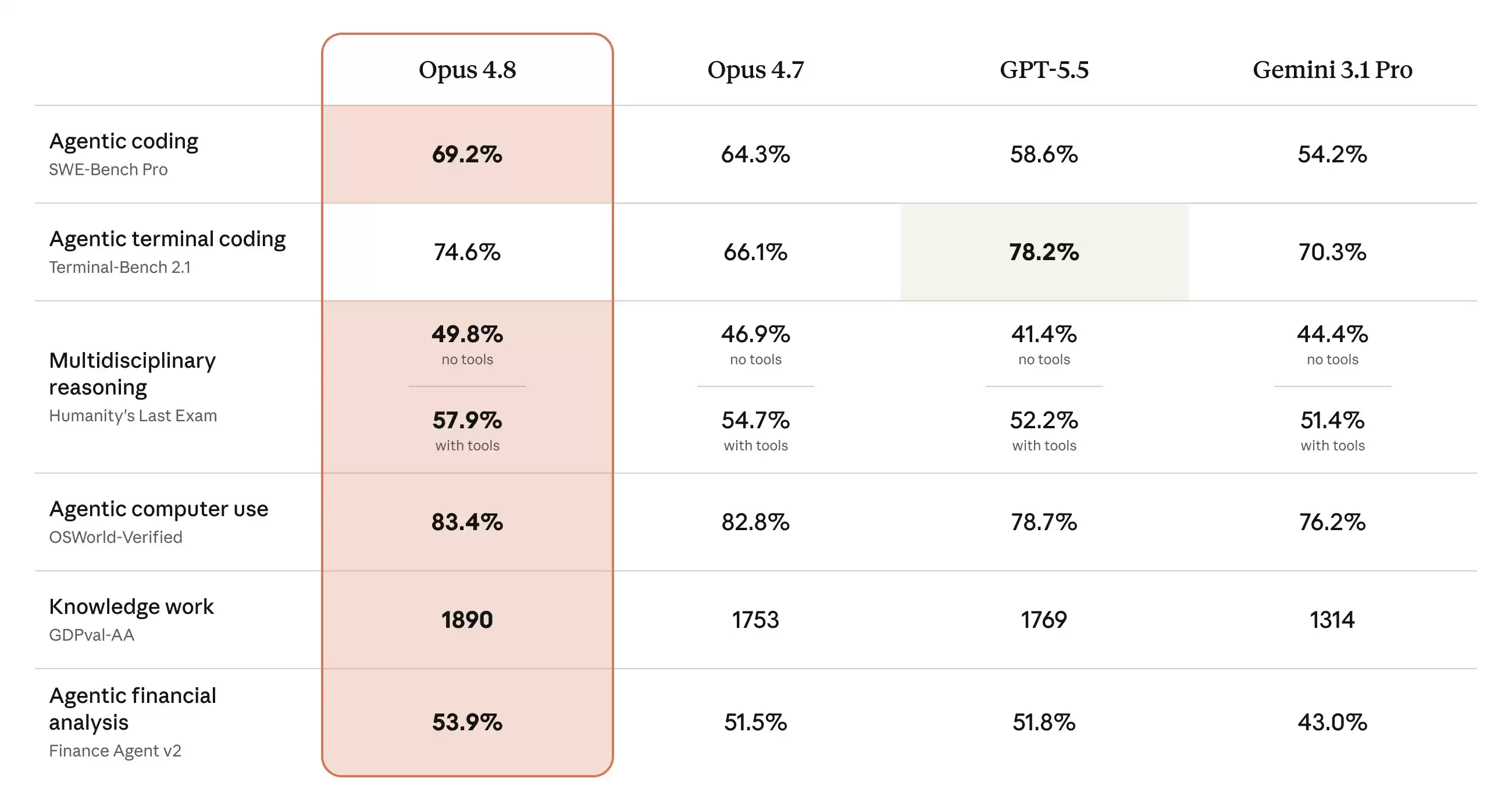
基准测试亮点
Anthropic 公布的核心数据集中在智能体工作能力上:
- 在 Super-Agent 基准测试中击败了 GPT-5.5,该测试衡量的是端到端任务完成能力。
- 领跑 Legal Agent 基准测试,并且是第一个在该测试中总分突破 10% 的模型。
- 在 Online-Mind2Web 中拿到 84%,这是一项网页导航智能体测试。
这些数字放在一起来看,信号很明确:Opus 4.8 的定位是智能体应用,而非简单的对话聊天。
Opus 4.8 与 Opus 4.7 一览
| 属性 | Opus 4.7 | Opus 4.8 | | :--- | :--- | :--- | | API ID | claude-opus-4-7 | claude-opus-4-8 | | 输入价格 | $5 / 1M tokens | $5 / 1M tokens | | 输出价格 | $25 / 1M tokens | $25 / 1M tokens | | 上下文窗口 | 1M tokens | 1M tokens | | 最大输出 | 128K tokens | 128K tokens | | 努力级别 | low 到 max | low 到 max | | 遗漏的代码缺陷 | 基准 | 约减少 4 倍 | | 诚实度 / 对齐 | 基准 | 已提升 | | 知识截止日期 | 2026 年 1 月 | 2026 年 1 月 |
规格参数的有意保持一致意味着——你用同样的价格得到了一个错误更少的模型。对于大多数团队来说,迁移风险极低。
如何访问 Claude Opus 4.8
有四个入口可以访问:
- Claude API:针对 Messages 端点使用模型 ID
claude-opus-4-8。 - Claude 应用程序:付费计划的默认高端模型,免费计划提供有限额度。
- Claude Code:作为顶级模型提供,选择高努力模式时支持动态工作流。
- 云平台:AWS、Vertex AI 以及 Microsoft Foundry(上下文窗口上限为 200K token)。
谁应该使用 Opus 4.8
Opus 4.8 专为工作负载中难度最高的场景而设计。适合以下几种情况:
- 运行长周期智能体编码任务,静默 bug 的代价很高。
- 需要智能体在无人值守时做出合理判断。
- 编排多步工具调用,希望减少无效调用。
- 任务确实需要前沿推理能力,而非简单的分类。
对于高吞吐、延迟敏感或简单的任务,较小的模型或较低的努力级别更合适。努力程度控制的意义正在于此——你不再需要通过切换模型来切换“档位”。
在发布前测试 Opus 4.8
模型切换在代码层面很简单,但也很容易出问题。流式块、工具调用验证、新的 output_config 结构以及自适应思考响应,都会改变代码需要解析的负载。在将模型推向生产之前,建议针对它重放真实请求并对比输出差异。
常见问题解答
Claude Opus 4.8 比 Opus 4.7 更好吗? 是的,在质量方面明显更好。它能多捕获约四倍的代码缺陷,面对不确定性时更诚实,工具调用效率更高。价格、上下文窗口和最大输出完全一致,几乎没有理由继续停留在 4.7。
Opus 4.8 的价格是多少? 标准模式下每百万输入 token 5 美元,每百万输出 token 25 美元。快速模式价格翻倍,但输出速度提升 2.5 倍。
Opus 4.8 的上下文窗口是多少? 同步 Messages API 上输入为 1M token,输出最高 128K token。Batch API 支持最高 300K token 的输出。Microsoft Foundry 上为 200K token。
Opus 4.8 支持扩展思考吗? 它使用自适应思考,由模型决定推理量。不支持手动的 budget_tokens 思考,否则会返回 400 错误。
什么是 effort 参数? 它是 output_config 内的一个设置,控制 Claude 在文本、工具调用和推理上消耗的 token 数量。级别包括 low、medium、high、xhigh 和 max。
什么是动态工作流? 这是 Claude Code 的一项功能,可在一个会话中启动多个并行子智能体,由 xhigh 努力模式和对话中途系统消息驱动。




