ResNet-18 深度拆解:残差网络的核心原理与代码实现
在深度学习的世界里,经常有人问这样一个问题:网络越深,效果一定越好吗?
答案显然是否定的。如果只是简单地把网络层数堆上去,训练反而会变得更困难,甚至出现梯度消失或退化问题——深度越大,训练效果反而可能变差。
ResNet(残差网络)就是为了解决这个困境而诞生的。它的核心思路非常巧妙:加一条“捷径”,让数据可以跳跃传播。
今天重点拆解的是 ResNet-18,这个“18”代表网络总共有 18 层(主要指包含可学习参数的卷积层和全连接层)。它的核心特点就是“残差连接”(Residual Connection),正是靠着这条捷径,信息能在网络中跳跃传播,从而避免梯度消失,让深层网络的训练变得可行。
下面这张图是 ResNet-18 的网络简图(假设输入的张量形状为 3×64×64)。从图中可以看到,结构分为四个 stage,完整的结构图在最后。
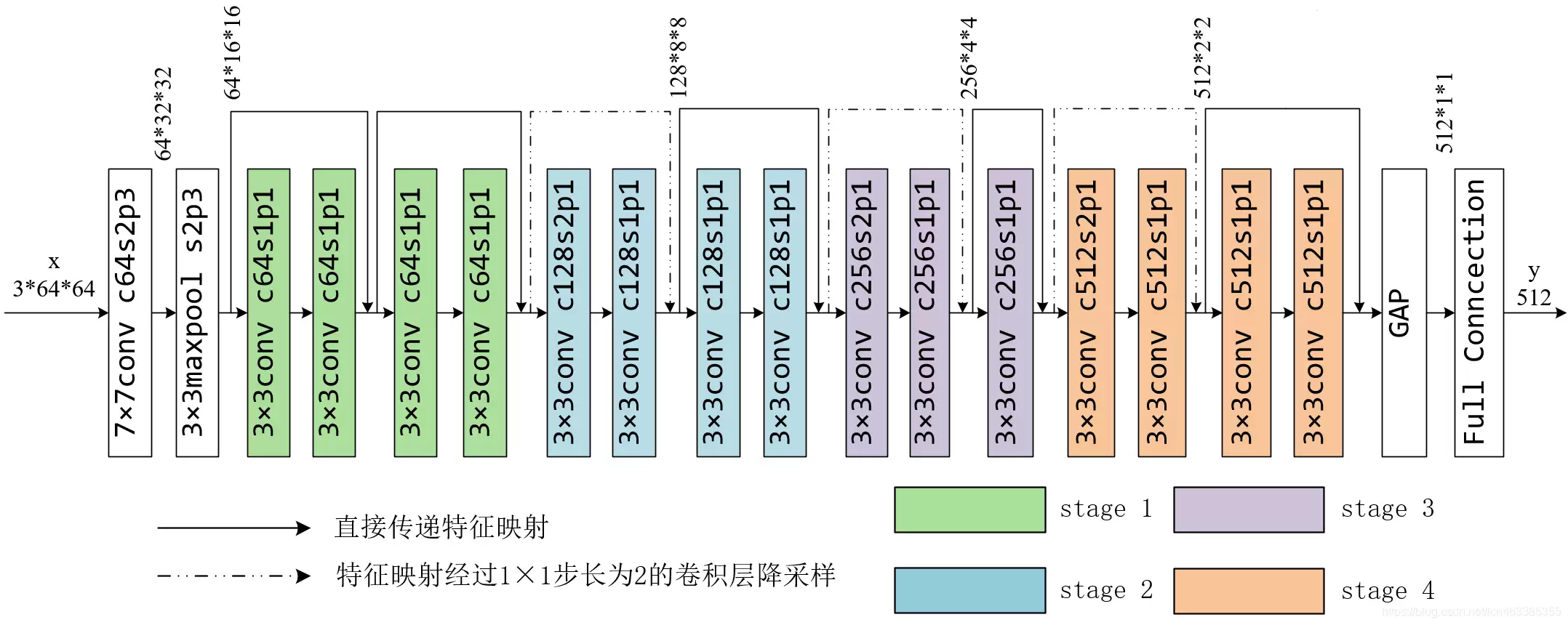
ResNet-18 的基本架构可以概括为:
- 残差块(Residual Block)负责特征提取,每个块内部包含两个 3×3 卷积。
- 跳跃连接(Shortcut)让数据既可以通过卷积层,也可以直接“抄近路”传递到下一层。
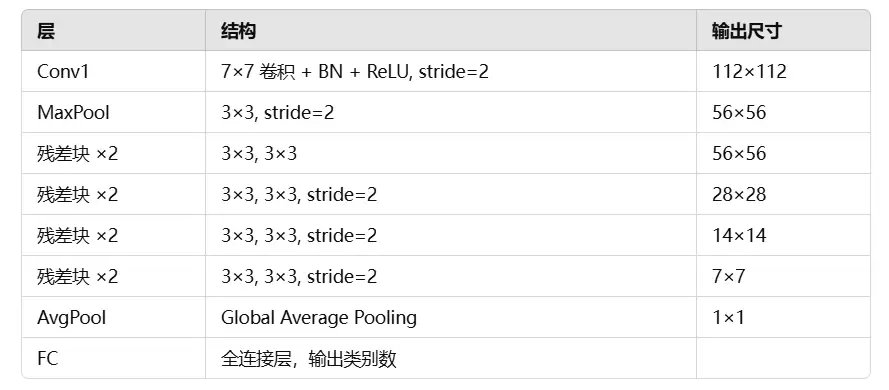
残差连接
假设输入是 X,普通 CNN 的目标是直接学一个映射 F(X),但 ResNet 让网络学的是 F(X) - X。这样一来,我们可以重写成:
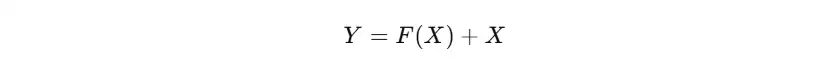
其中,F(X) 是卷积层学习的内容(即残差),X 是输入的跳跃连接(shortcut),最终输出就是 F(X) + X。
残差块通常包含两个卷积层,每个卷积层后面跟着批量归一化(Batch Normalization)和激活函数(如 ReLU)。这些层负责提取和转换输入特征。
那么问题来了:为什么残差块会有两种模式?
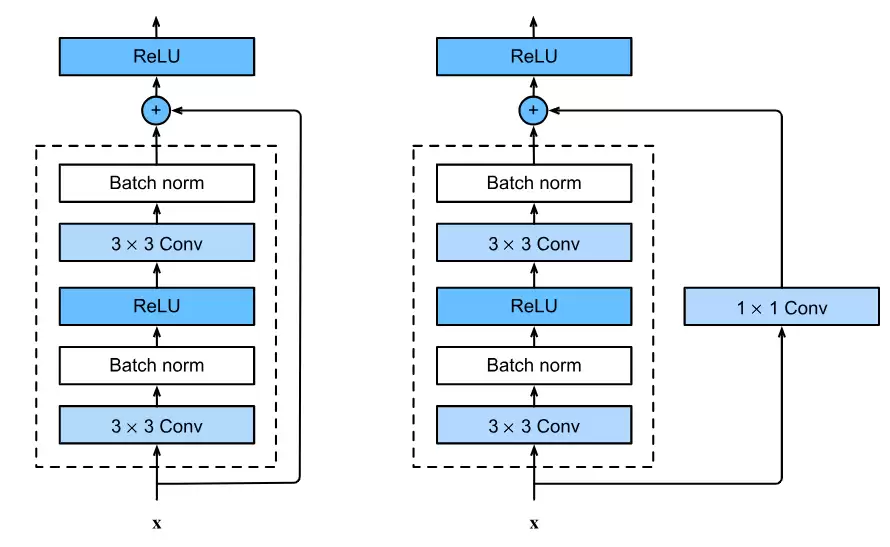
现在我们手动模拟一下残差块的运算过程:
- 给定 3×3 的输入张量。
- 通过第一个卷积层,批量归一化,激活函数(ReLU,负数变成 0)。
- 通过第二个卷积层,批量归一化,激活函数(ReLU,负数变成 0),得到 F(X)。
- F(X) + X 得到最后的输出。
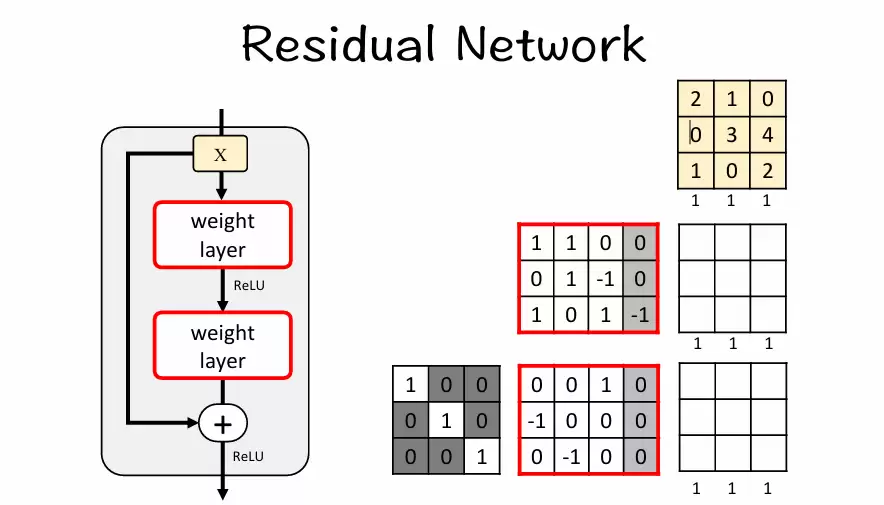
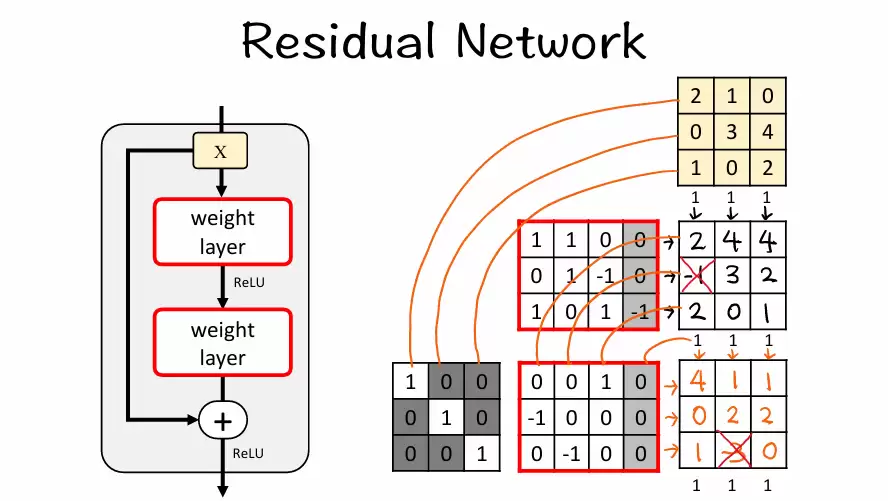
需要注意:F(X) + X 可以直接相加的前提是两者的大小和通道数完全一致。所以当两者不一致时,就需要增加一个分支(用 1×1 卷积进行调整),这就是需要 shortcut 的情况:
- 可以通过设置 1×1 卷积的卷积核数量来调整通道数。
- 可以通过设置 1×1 卷积的填充 padding=0 来调整大小。
那么,什么时候两者会不一致呢?
- 步长 ≠ 1 时:意味着输入的尺寸会缩小。比如 stride=2 时,H×W 变为 H/2×W/2。由于 x 形状变小了,需要用 1×1 卷积让 x 也变小,以便与 F(x) 匹配。
- in_channels != out_channels 时:输入通道数不等于输出通道数,意味着 x 的通道数不能直接加到 F(x) 上。例如,之前的特征图有 64 个通道,当前块的 F(x) 计算出了 128 个通道。这样 x 是 64 通道,而 F(x) 是 128 通道,无法相加。解决办法:用 1×1 卷积进行升维/降维,把 x 变成与 F(x) 相同的通道数。
残差块的实现
代码实现
import torch
import torch.nn as nn
import torch.nn.functional as F
# ===== 定义 BasicBlock =====
class BasicBlock(nn.Module):
expansion = 1
def __init__(self, in_channels, out_channels, stride=1):
super(BasicBlock, self).__init__()
self.conv1 = nn.Conv2d(in_channels, out_channels, kernel_size=3, stride=stride, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(out_channels)
self.conv2 = nn.Conv2d(out_channels, out_channels, kernel_size=3, stride=1, padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(out_channels)
# 如果尺寸或通道不同,调整 shortcut
self.shortcut = nn.Sequential()
if stride != 1 or in_channels != out_channels:
self.shortcut = nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(out_channels)
)
def forward(self, x):
print("输入 x 形状:", x.shape)
identity = self.shortcut(x)
if len(self.shortcut) > 0:
print("shortcut 调整后形状:", identity.shape)
else:
print("shortcut 未调整(直接跳接)")
out = self.conv1(x)
print("conv1 输出:", out.shape)
out = self.bn1(out)
print("bn1 输出:", out.shape)
out = F.relu(out)
print("relu1 输出:", out.shape)
out = self.conv2(out)
print("conv2 输出:", out.shape)
out = self.bn2(out)
print("bn2 输出:", out.shape)
out += identity
print("残差相加后:", out.shape)
out = F.relu(out)
print("relu2 输出:", out.shape)
print("-" * 50)
return out
# ===== 二、创建一个实例并测试 =====
# 情况1:输入输出通道相同,不降采样
block1 = BasicBlock(in_channels=3, out_channels=3, stride=1)
x1 = torch.randn(1, 3, 32, 32) # batch=1, 通道=3, 尺寸=32x32
print("===== 测试 block1(stride=1)=====")
out1 = block1(x1)
print("最终输出:", out1.shape)
# 情况2:输入输出通道不同,降采样
block2 = BasicBlock(in_channels=3, out_channels=4, stride=2)
x2 = torch.randn(1, 3, 32, 32)
print("\n===== 测试 block2(stride=2)=====")
out2 = block2(x2)
print("最终输出:", out2.shape)
现在一步步图解这个过程:
情况1:输入输出通道相同,不降采样
首先,经过第一个卷积、归一化和激活函数,大小仍然是 3×32×32。
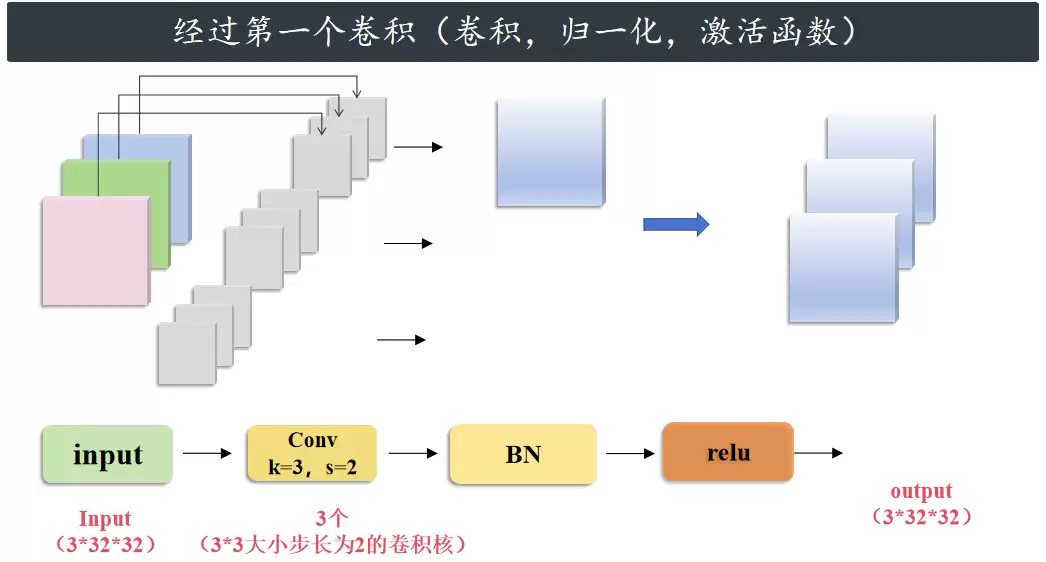
然后经过第二个卷积、归一化,大小仍然是 3×32×32。到这里,第一个支路计算结束。
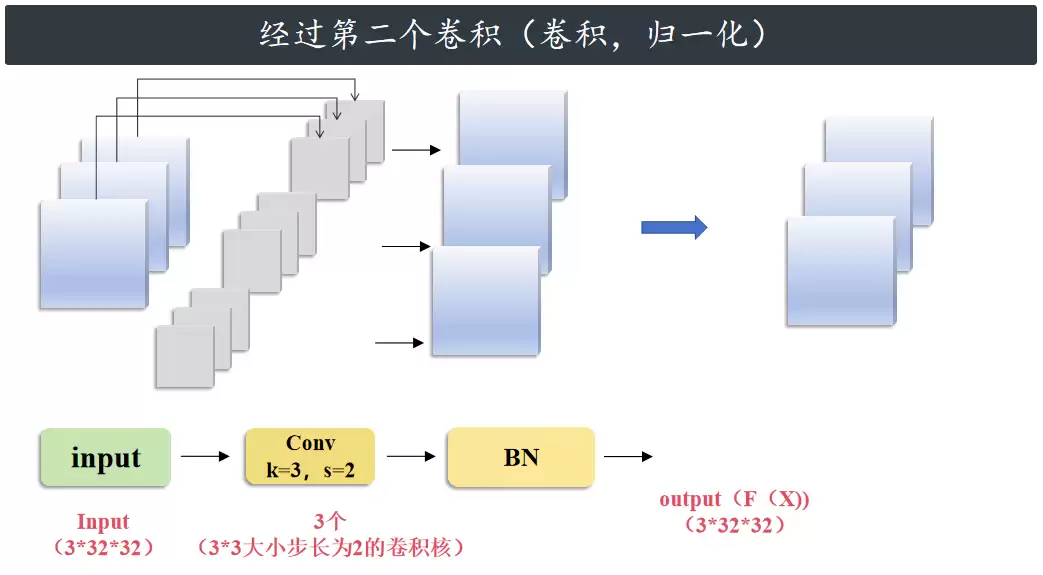
接着计算残差分支。由于这个残差模块的输出通道数和输入通道数一样,步长也是 1,所以不需要残差分支,输出就是原始的 X。然后把 X 和另一个分支的 F(X) 逐元素相加,再经过一个 ReLU 激活函数处理,残差模块计算结束。
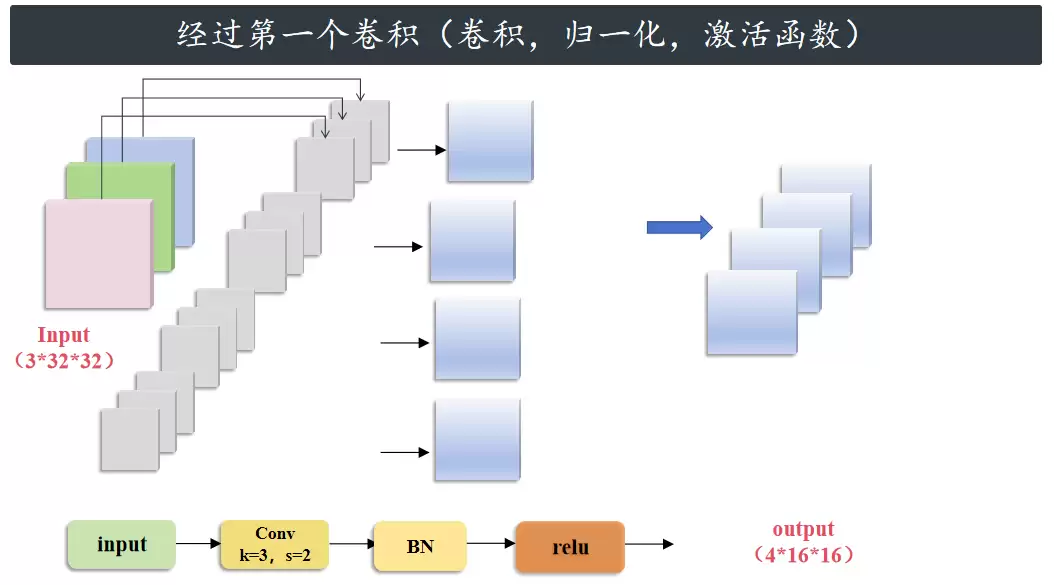
情况2:输入输出通道不相同,降采样
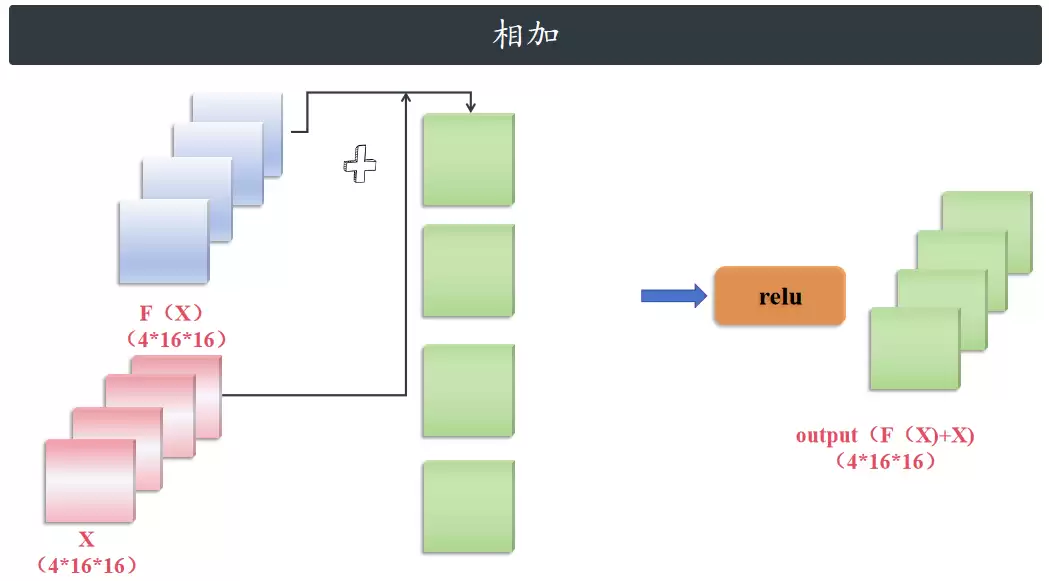
首先,经过第一个卷积(4 个大小 3×3、步长为 2 的卷积)、归一化和激活函数。由于卷积核的数量是 4,最后输出通道数也是 4;步长为 2,所以图片大小变为原来的一半,最终得到 4×16×16。
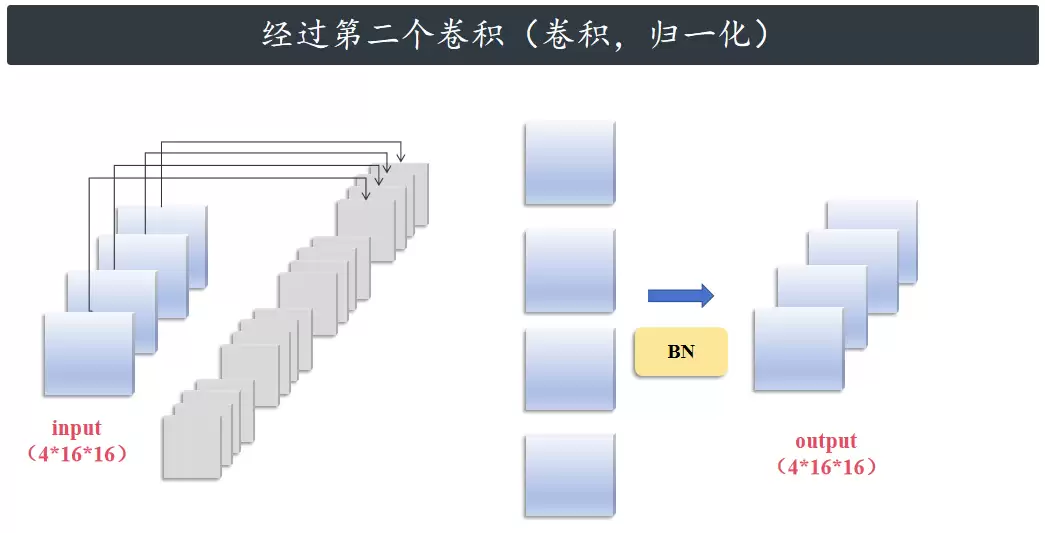
然后经过第二个卷积(4 个大小 3×3、步长为 1 的卷积)、归一化,大小仍然是 4×16×16。至此,第一个支路计算完成。
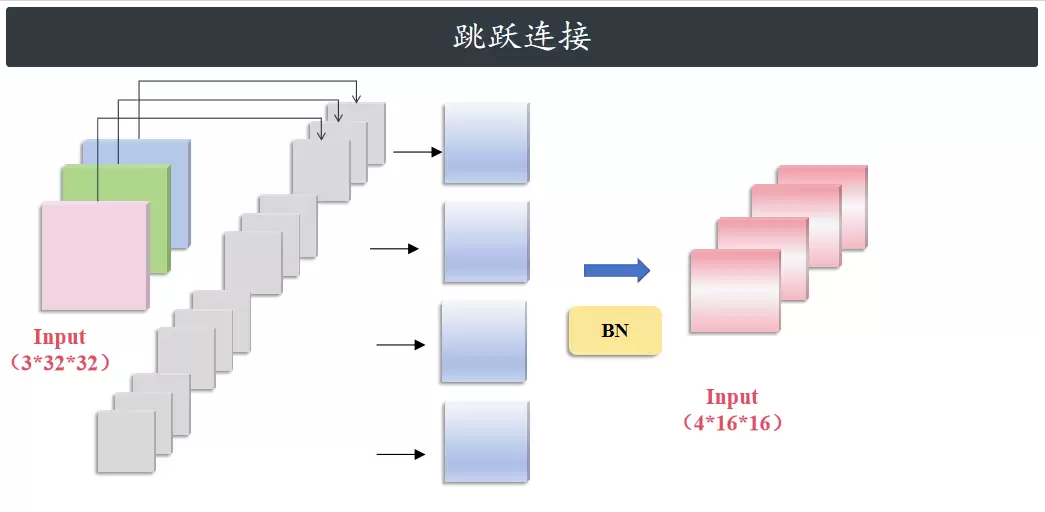
接着计算残差分支。由于残差模块的输出通道数和输入通道数不一致,所以残差分支的输出是原始的 X 经过 shortcut 后的结果(1×16×16)。
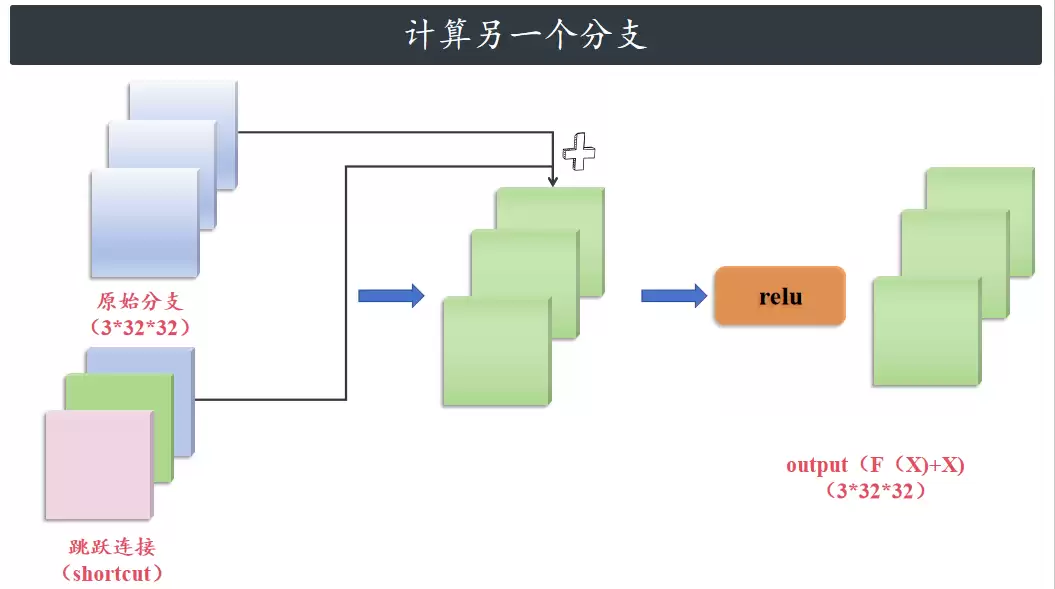
最终输出是原始分支的输出 F(x) 和残差分支的输出 X 相加,再经过 ReLU 激活函数,得到 4×16×16 大小的特征图。
make_layer:堆叠多个 BasicBlock
ResNet 共包含 4 个 layer,每个 layer 中有多个 num_blocks。为了更简洁地表示,可以用一个 layer 函数来集成多个残差层。
def _make_layer(self, out_channels, num_blocks, stride):
layers = [] # 创建一个空列表,用于存储这一层的 BasicBlock
# 第一个 BasicBlock 的 stride 为输入参数 stride
layers.append(BasicBlock(self.in_channels, out_channels, stride))
# 更新当前通道数
self.in_channels = out_channels
# 接下来的 num_blocks - 1 个 BasicBlock 都使用 stride=1
for _ in range(1, num_blocks):
layers.append(BasicBlock(self.in_channels, out_channels, stride=1))
# 将所有的 BasicBlock 堆叠成一个 nn.Sequential 模块
return nn.Sequential(*layers)
这里简单解释一下这个过程:
- 初始化 layers 列表:用于存储构建的每一个 BasicBlock,最终返回的是 nn.Sequential(一个有序的模块容器)。
- 添加第一个 BasicBlock:使用传入的 stride,并且将当前的输入通道数(self.in_channels)作为输入通道数,输出通道数为 out_channels。stride 影响卷积操作的步长,通常第一个 BasicBlock 需要通过卷积来改变特征图的尺寸(例如降采样)。
- 更新当前通道数:每次添加一个 BasicBlock 后,输入通道数变为该 BasicBlock 输出的通道(out_channels)。
- 添加后续的 BasicBlock:从第 2 个 BasicBlock 开始,使用 stride=1,即不改变特征图尺寸。这是为了保持相同的空间分辨率,通常在残差网络的后续块中使用步长为 1 来保证特征图尺寸不变。
- 返回 nn.Sequential:最后通过 nn.Sequential 将所有的 BasicBlock 按顺序组合成一层。nn.Sequential 会按照列表中的顺序依次执行每个 BasicBlock。
来看一个简单的例子:
# ---------- 包含 _make_layer 的简单 ResNet 片段 ----------
class MiniResNet(nn.Module):
def __init__(self):
super(MiniResNet, self).__init__()
self.in_channels = 3
# 使用 _make_layer 创建一层:不降采样,保持 64 通道
self.layer1 = self._make_layer(out_channels=64, num_blocks=2, stride=1)
def _make_layer(self, out_channels, num_blocks, stride):
layers = []
layers.append(BasicBlock(self.in_channels, out_channels, stride))
self.in_channels = out_channels
for _ in range(1, num_blocks):
layers.append(BasicBlock(self.in_channels, out_channels, stride=1))
return nn.Sequential(*layers)
def forward(self, x):
print("input:", x.shape)
x = self.layer1(x)
print("after layer1:", x.shape) # 64 通道, 空间尺寸不变
return x
# ---------- 测试 ----------
model = MiniResNet()
# 假设输入是常见的 32x32 RGB 图像
inp = torch.randn(1, 3, 32, 32)
out = model(inp)

完整代码
import torch
import torch.nn as nn
import torch.nn.functional as F
class BasicBlock(nn.Module):
def __init__(self, in_channels, out_channels, stride=1):
super(BasicBlock, self).__init__()
self.conv1 = nn.Conv2d(in_channels, out_channels, kernel_size=3, stride=stride, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(out_channels)
self.conv2 = nn.Conv2d(out_channels, out_channels, kernel_size=3, stride=1, padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(out_channels)
self.shortcut = nn.Sequential()
if stride != 1 or in_channels != out_channels:
self.shortcut = nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(out_channels)
)
def forward(self, x):
out = F.relu(self.bn1(self.conv1(x)))
out = self.bn2(self.conv2(out))
out += self.shortcut(x)
return F.relu(out)
class ResNet18(nn.Module):
def __init__(self, num_classes=2):
super(ResNet18, self).__init__()
self.in_channels = 64
self.conv1 = nn.Conv2d(3, 64, kernel_size=3, stride=1, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(64)
self.layer1 = self._make_layer(64, 2, stride=1)
self.layer2 = self._make_layer(128, 2, stride=2)
self.layer3 = self._make_layer(256, 2, stride=2)
self.layer4 = self._make_layer(512, 2, stride=2)
self.a vgpool = nn.AdaptiveA vgPool2d((1, 1))
self.fc = nn.Linear(512, num_classes)
def _make_layer(self, out_channels, num_blocks, stride):
layers = []
layers.append(BasicBlock(self.in_channels, out_channels, stride))
self.in_channels = out_channels
for _ in range(1, num_blocks):
layers.append(BasicBlock(self.in_channels, out_channels, stride=1))
return nn.Sequential(*layers)
def forward(self, x):
print("输入形状: ", x.shape)
out = self.conv1(x)
print("conv1输出: ", out.shape)
out = self.bn1(out)
print("bn1输出: ", out.shape)
out = F.relu(out)
print("relu输出: ", out.shape)
out = self.layer1(out)
print("layer1输出:", out.shape)
out = self.layer2(out)
print("layer2输出:", out.shape)
out = self.layer3(out)
print("layer3输出:", out.shape)
out = self.layer4(out)
print("layer4输出:", out.shape)
out = self.a vgpool(out)
print("a vgpool输出:", out.shape)
out = torch.flatten(out, 1)
print("flatten输出:", out.shape)
out = self.fc(out)
print("fc输出: ", out.shape)
return out
# 测试网络(打印结构+输出形状)
if __name__ == "__main__":
model = ResNet18(num_classes=2)
print("="*50)
print("ResNet18 网络结构:")
print(model) # 打印网络结构
print("="*50)
x = torch.randn(1, 3, 32, 32) # 输入:1张3通道32x32图像
print("\n各层输出形状:")
model(x)

以下是运行后打印的网络结构和各层输出形状,可以清晰地看到 ResNet-18 每一层的构成与数据流变化:
==================================================
ResNet18 网络结构:
ResNet18(
(conv1): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(layer1): Sequential(
(0): BasicBlock(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(shortcut): Sequential()
)
(1): BasicBlock(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(shortcut): Sequential()
)
)
(layer2): Sequential(
(0): BasicBlock(
(conv1): Conv2d(64, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(shortcut): Sequential(
(0): Conv2d(64, 128, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): BasicBlock(
(conv1): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(shortcut): Sequential()
)
)
(layer3): Sequential(
(0): BasicBlock(
(conv1): Conv2d(128, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(shortcut): Sequential(
(0): Conv2d(128, 256, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): BasicBlock(
(conv1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(shortcut): Sequential()
)
)
(layer4): Sequential(
(0): BasicBlock(
(conv1): Conv2d(256, 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(shortcut): Sequential(
(0): Conv2d(256, 512, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): BasicBlock(
(conv1): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(shortcut): Sequential()
)
)
(a vgpool): AdaptiveA vgPool2d(output_size=(1, 1))
(fc): Linear(in_features=512, out_features=2, bias=True)
)
==================================================
各层输出形状:
输入形状: torch.Size([1, 3, 32, 32])
conv1输出: torch.Size([1, 64, 32, 32])
bn1输出: torch.Size([1, 64, 32, 32])
relu输出: torch.Size([1, 64, 32, 32])
layer1输出: torch.Size([1, 64, 32, 32])
layer2输出: torch.Size([1, 128, 16, 16])
layer3输出: torch.Size([1, 256, 8, 8])
layer4输出: torch.Size([1, 512, 4, 4])
a vgpool输出: torch.Size([1, 512, 1, 1])
flatten输出: torch.Size([1, 512])
fc输出: torch.Size([1, 2])




