最近,一份由郎瀚威团队发布的《微软Edge浏览器Copilot综合能力测试报告》在行业内引发了广泛关注。这份报告并未停留在泛泛而谈,而是将Copilot置于信息检索、PPT生成、表格处理等八项具体任务中,与OpenAI、Manus等主流AI工具进行了一场硬碰硬的横向对比。测试结果如何?简单来说,Copilot在“快”与“深”之间,做出了非常鲜明的取舍。
测试数据显示,Copilot的平均响应速度仅为26秒,在快速信息检索类任务中优势尽显。然而,当任务复杂度上升,比如需要生成可下载文件或进行深度分析时,它的短板就暴露了出来。整体来看,其表现与Comet接近,但逊色于Manus和Genspark。报告通过详实的案例和1-5分的难度分级,为我们在实际工作中如何选型AI工具,提供了一个相当实用的参考框架:关键在于根据任务复杂度,在效率与质量之间做出权衡。


测试目标
本次测试的目的非常明确:就是要全面评估微软Edge浏览器Copilot的综合能力。通过将其与OpenAI Agent、Perp Comet、Manus和Genspark等主流选手同台竞技,在信息检索、报告生成、PPT制作、数据整理等多个真实场景下,客观分析其在响应速度、内容质量和功能实现等方面的优势与不足。最终,这份报告旨在为用户提供一个清晰的参考,帮助大家根据自身需求,找到最趁手的那把“AI工具”。
测试感受
在实际测试过程中,Copilot给人的第一印象就是“快”。平均26秒的响应速度,特别是在查找“旧金山财务报告”这类任务中,8秒内就能给出有效链接,效率之高令人印象深刻。然而,这种速度优势在复杂任务面前会迅速消退。例如,它无法生成可直接下载的PPT或Excel文件,提供的内容往往深度不足,有时甚至会偏离核心需求。
相比之下,OpenAI和Manus在生成专业报告方面表现更为出色。一个有趣的发现是,Copilot的视频摘要能力超出了预期,但测试中也遇到了诸如界面提示“这不是你的错”等小问题。总而言之,Copilot呈现出的是一种典型的权衡特性:它非常适合那些对响应速度有极高要求,但对内容深度和格式完整性要求不高的快速查询场景。

综合测试结果
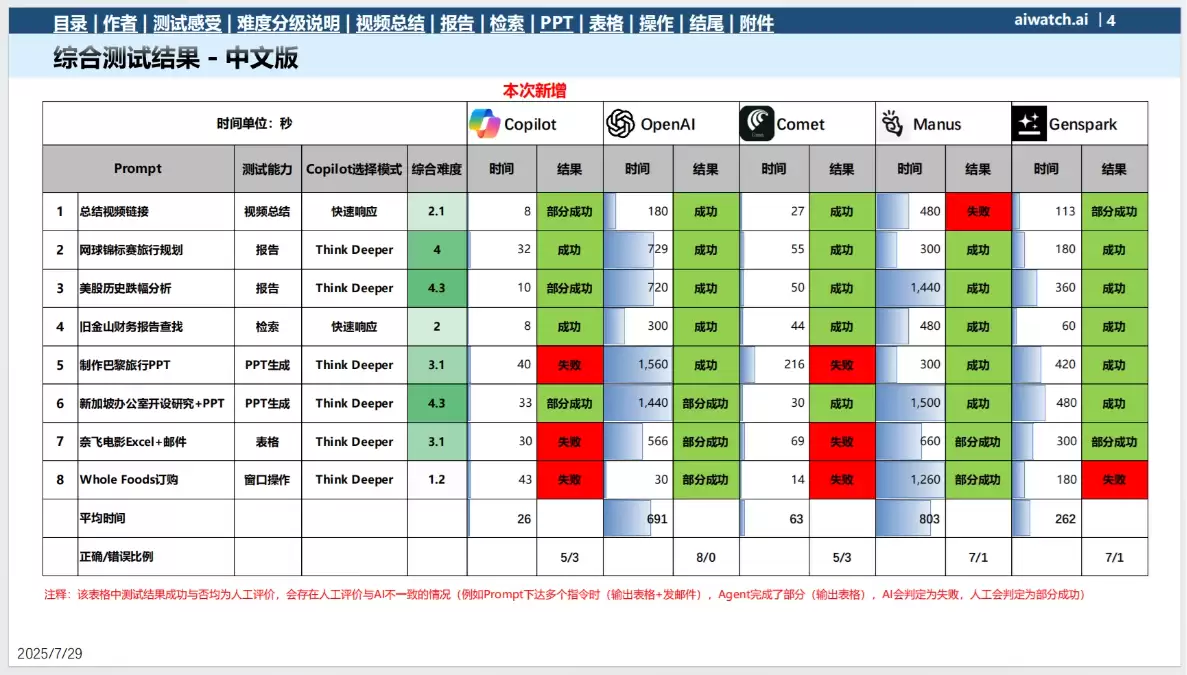
测试任务与结果
下面,我们通过八项具体任务的测试结果,来详细拆解Copilot的能力边界。
视频总结
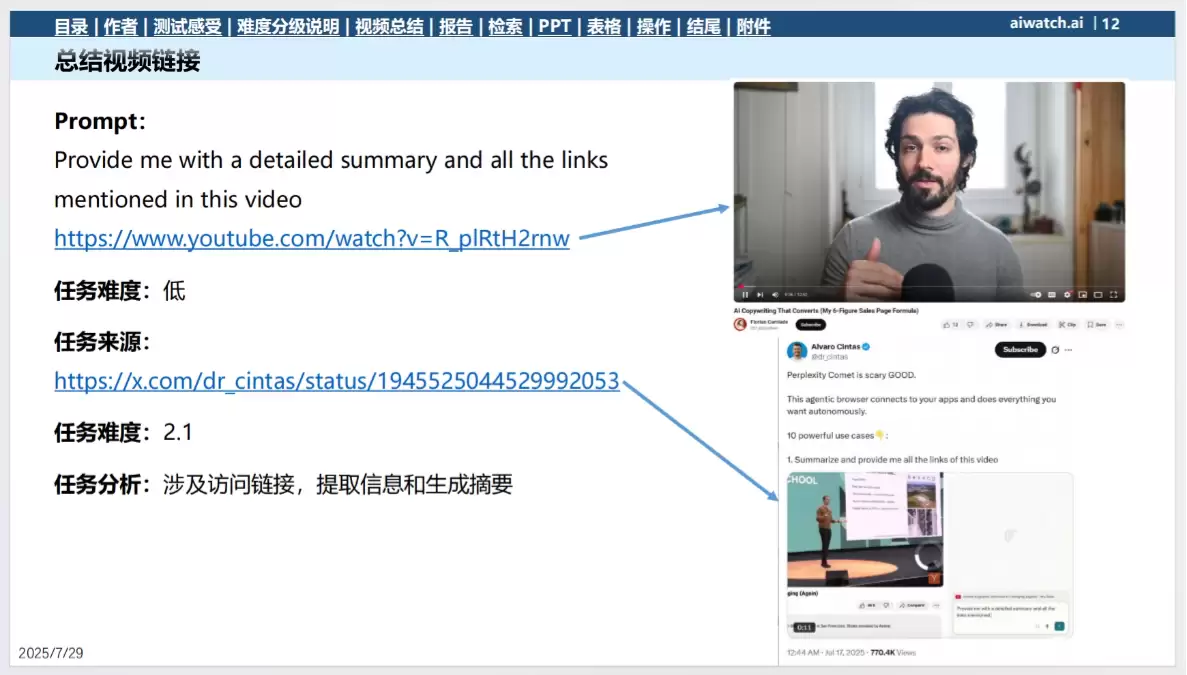
任务:总结指定视频内容并准确提取其中的链接。
结果:Copilot耗时8秒完成了总结,但在提取链接环节出现了偏差,准确性不足,因此被判定为“部分成功”。
对比:OpenAI和Comet在此任务上表现更优,总结和链接提取的准确度更高。
网球锦标赛旅行规划
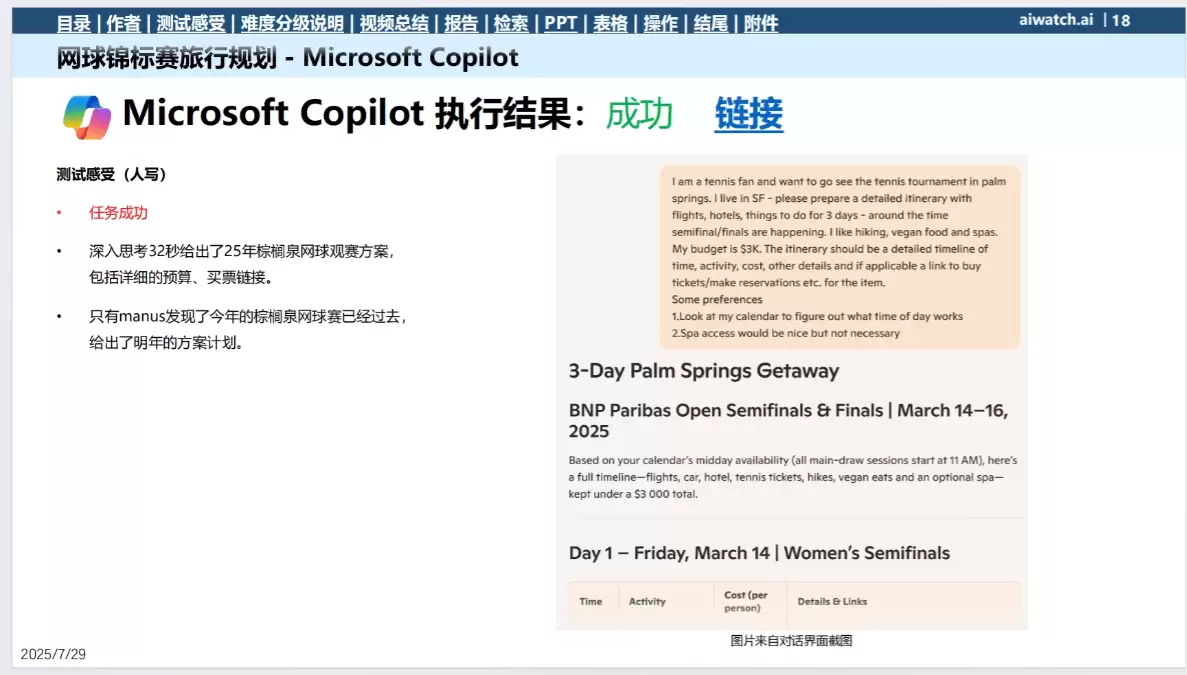
任务:为前往观看网球锦标赛制定一份详细行程,包括航班、酒店和活动安排。
结果:Copilot用时32秒生成了一份行程计划,任务算作成功,但其中对预算的预估明显偏低,不够合理。
对比:Manus和Genspark提供了更为全面和细致的方案,考虑更加周详。
美股历史跌幅分析
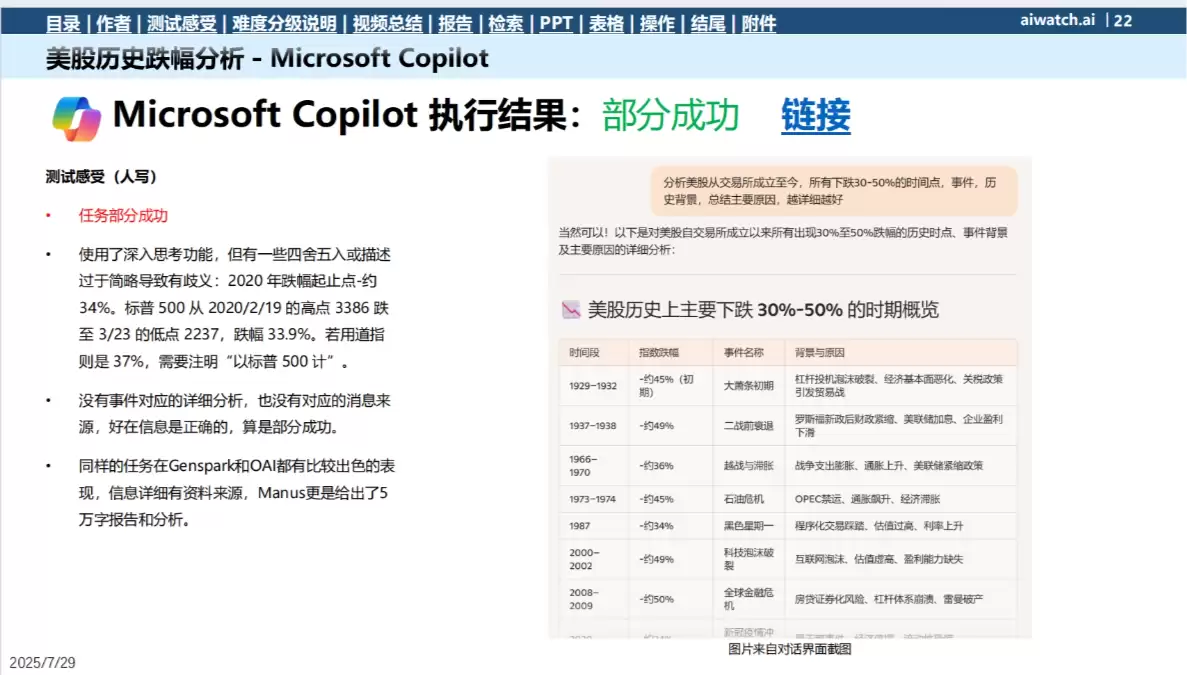
任务:分析美股历史上的重大跌幅事件及其背后原因。
结果:Copilot仅用10秒就给出了回复,速度很快,但提供的信息较为简略,缺乏深度分析,故为“部分成功”。
对比:Manus直接生成了一份长达5万字的详细报告,而Genspark的分析也更为深入和全面。
旧金山财务报告查找
任务:查找旧金山市2020年至2024年的官方财务报告。
结果:这是Copilot的“高光时刻”,仅用8秒就成功找到了并提供有效链接,任务圆满完成。
对比:虽然OpenAI和Manus在此任务上也表现良好,但Copilot在速度上占据了绝对优势。

PPT生成
任务:制作一份关于巴黎旅行的演示文稿(PPT)。
结果:Copilot未能完成该任务。它只提供了文字描述和大纲,无法生成可下载的PPT文件。
对比:OpenAI、Manus和Genspark均成功生成了可用的PPT文件,在这一功能性任务上优势明显。
表格生成与邮件发送
任务:整理奈飞(Netflix)电影数据成表格,并通过邮件发送。
结果:Copilot任务失败。它既无法生成可下载的表格文件,也无法执行邮件发送操作。
对比:其他部分工具虽然能生成表格,但也均未完全执行邮件发送这一最终步骤。

窗口操作(Whole Foods订购)
任务:在Whole Foods网站完成食品订购操作。
结果:Copilot任务失败。它只能提供购物清单,无法实际完成网站上的下单支付流程。
对比:所有参与测试的其他AI工具同样未能完成核心的下单操作,这表明此类涉及复杂交互和支付的动作仍是当前AI的普遍短板。





