很多人觉得GPT像个黑盒子——你问它一个问题,它就能给出一段像模像样的回答。但AI模型背后究竟是怎么工作的?为什么它能“理解”语言,甚至能“推理”?
这篇文章想帮大家拆开这个黑盒子,从最基础的神经网络讲起。没有AI基础的小伙伴也能看懂,希望读完以后,你再聊起大模型时能更有底气。
一、GPT与神经网络的关系
GPT这个词大家应该已经不陌生了。当我们跟它对话时,关注的通常是输入的问题和输出的答案,至于中间发生了什么,几乎一无所知。它就像一个神秘的黑匣子。

实际上,GPT是一种基于神经网络的自然语言处理模型。它的工作流程大体是这样的:先用海量数据训练一个神经网络,让模型的输出逐渐符合我们的预期;训练完成后,模型就能接收用户输入,并针对输入中的关键信息给出经过“思考”后的回答。要理解GPT究竟是怎么“思考”的,我们不妨先从神经网络本身入手。
二、什么是神经网络
神经网络这个词听起来很高大上,但它的灵感其实来自生物学。高中生物课讲过,人类的神经系统由数以亿计的神经元连接而成——每个神经元有细胞体、树突、轴突,不同神经元通过突触相互连接,形成复杂的大脑网络。
人工智能想模仿这种机制,让机器获得接近人类的智力,于是创造了一种计算模型:人工神经网络。它由多层神经元组成,每个神经元接收输入并产生输出。下图中的每个圆圈就是一个神经元,它们能进行简单计算,然后把结果传递给下一个神经元。
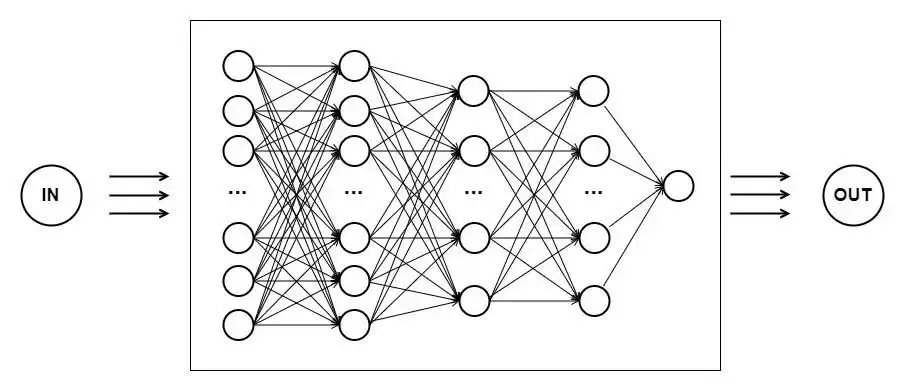
生物学上,大脑结构越简单,智力越低;神经系统越复杂,能处理的问题也越多。人工神经网络也一样——越复杂的网络结构,计算能力越强。这也是为什么后来发展出了“深度”神经网络:“深度”指的是网络拥有多个隐藏层(上图中纵向的神经元层数)。训练这种深度神经网络的过程,就叫深度学习。
构建好深度神经网络后,我们只需要把训练数据喂进去,网络就会自发地学习数据中的特征。举个例子:想训练一个网络来识别猫,那就把大量不同种类、不同姿势、不同外观的猫的图片扔进去让它学习。训练成功后,随便给一张新图片,它就能告诉你里面有没有猫。
三、神经网络是如何计算的
知道了神经网络是什么,接下来要解决一个更具体的问题:神经元到底是怎么对输入数据进行计算的?在讨论计算之前,得先搞清楚数据是怎么输进去的。我们以图像和文本两类常见数据为例来说明。
数据是如何输入到神经网络中的
1、图像输入处理
想象一下:把一张图片放大到一定程度,会看到一格一格的小方块,那就是像素点。像素越多,图片越清晰。每个像素只有一种颜色。光学三原色(红、绿、蓝)通过不同强度混合能产生所有颜色。在RGB模型中,每种颜色的强度用0到255之间的数值表示——0代表没有该色光,255代表最强。计算机存储一张图像时,会存三个独立的矩阵,分别对应红、绿、蓝的强度。比如一张256×256像素的图,在计算机里就是三个256×256的二维数组。把这三个矩阵的颜色层叠在一起,就能还原出原图。
那怎么把这些矩阵交给神经网络呢?通常的做法是将三个矩阵“拉直”成一个向量——也就是一个1×n或n×1的数组。256×256×3 = 196608,所以这个向量有196608个维度。在AI领域,每个输入到神经网络的数据点都叫一个“特征”,这张图像就有196608个特征,这个向量也叫特征向量。神经网络接收特征向量作为输入,进行预测,然后给出结果。
2、文本输入处理
文本的处理方式不同。文本由字符组成,首先需要把它切分成有意义的单词,这个过程叫分词。分词后,构建一个词汇表(可以只包含出现过的单词,或只保留高频词),给每个单词分配一个唯一的索引。这样文本就变成了离散的符号序列。在输入神经网络之前,通常还要把符号序列转换成密集的向量表示(比如one-hot向量)。
以句子“How does neural network works?”为例:
分词:["how", "does", "neural", "network", "works"]
词汇表:{"how": 0, "does": 1, "neural": 2, "network": 3, "works": 4}
序列化:[0, 1, 2, 3, 4]
向量化(one-hot):
[[1, 0, 0, 0, 0],
[0, 1, 0, 0, 0],
[0, 0, 1, 0, 0],
[0, 0, 0, 1, 0],
[0, 0, 0, 0, 1]]
最后将这个向量序列输入神经网络进行训练或预测。
神经网络是如何进行预测的
先明确两个概念:训练和预测。训练是用已知数据集调整模型参数,让模型学会输入和输出之间的关系;预测是用训练好的模型对新输入数据进行推断。
神经网络的预测基于一个非常简单的线性变换公式:
z = w·x + b
其中 x 是特征向量,w 是每个特征的权重(代表该特征的重要程度),b 是阈值(影响预测结果)。点乘运算就是 w 和 x 对应分量相乘再相加。如果有 i 个特征,公式展开就是:
z = x₁w₁ + x₂w₂ + ... + xᵢwᵢ + b
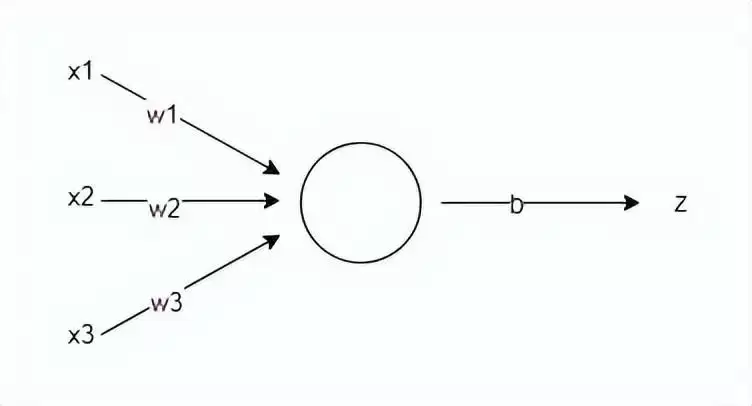
用一个生活化的例子来理解:你想决定周末要不要去公园划船,犹豫不决,于是请神经网络帮忙。影响决策的有三个因素:天气是否晴朗温暖、地点是否远近适中、同行玩伴是否合心意。实际情况是:天气阴且有阵风、地点在20公里外的偏远郊区、同行玩伴是你心仪已久的大帅哥。这三个因素就是特征向量 x = [x₁, x₂, x₃]。负向因素我们取-1,正向因素取1,所以 x = [-1, -1, 1]。接下来根据你的偏好给每个特征设置权重——如果你根本不在乎天气和地点,只要跟大帅哥同行就风雨无阻,那权重可以设为 w = [1, 1, 5];如果你是个懒人,可能会设为 w = [2, 6, 3]。权重反映了每个因素在你心中的重要程度。
我们选第一组权重 w = [1, 1, 5],特征向量 x = [-1, -1, 1],阈值 b = 1。假设 z ≥ 0 表示去,z < 0 表示不去。计算:z = (-1×1) + (-1×1) + (1×5) + 1 = 4 > 0。所以神经网络预测的结果是:去公园划船。
上面用的公式本质上就是逻辑回归,它能把输入数据映射到二分类的概率输出。逻辑回归通常配合Sigmoid函数使用,把 z 值转换到0到1之间的概率:大于等于0.5视为正类,小于0.5视为负类。Sigmoid函数的公式和图像如下:
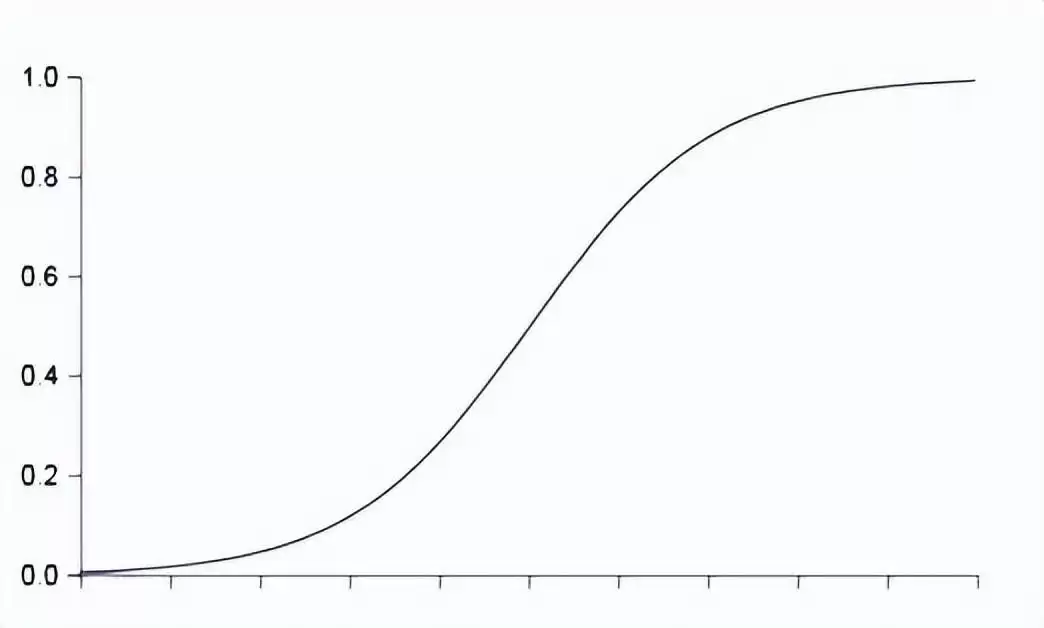
除了把输出限制在0到1之间,激活函数还有一个更重要的作用:引入非线性。如果没有激活函数,神经网络只能解决线性问题;加入激活函数后,只要层数足够深,网络就能逼近任意复杂的函数。所以激活函数是必不可少的。
神经网络是如何进行学习的
得到预测结果后,神经网络会通过损失函数判断预测是否准确。如果不准确,网络会自我调整——这就是学习的过程。
损失函数衡量预测结果与真实标签之间的误差。损失值越小,说明预测越准;损失值越大,说明误差越大。下面是一个常用于二分类问题的对数损失函数:
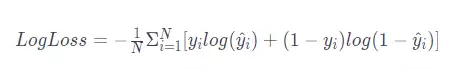

神经网络学习的目标就是调整模型参数(主要是权重 w 和阈值 b),让损失函数达到最小值。梯度下降算法就是用来实现这一目标的——它会一步步地改变 w 和 b 的值,让损失函数越来越小,直到找到最优解。

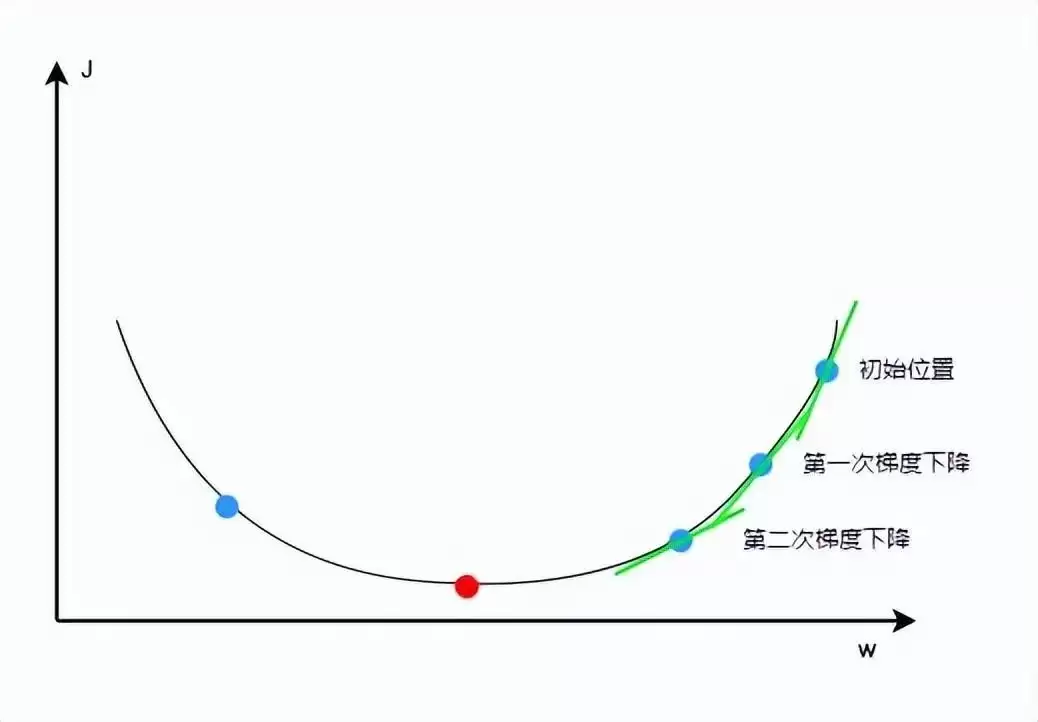
需要注意的是学习率的设置:如果太小,需要很多次梯度下降才能到达最低点,浪费计算资源;如果太大,可能直接跳过最低点,跑到另一侧去了。所以得根据实际情况选一个合适的学习率。
整个计算过程包含两个步骤:正向传播和反向传播。正向传播就是前面讲的——对输入特征加权求和,再通过激活函数做非线性变换,得到输出。反向传播则是从输出层向输入层反向传播梯度,计算损失函数关于各层参数的梯度,然后更新参数。反向传播涉及大量数学运算,感兴趣的读者可以深入研究。
四、综述
总结一下,神经网络训练和学习的过程,本质上就是对模型参数不断调优、不断减少预测损失的过程。经过充分训练后,模型能从输入数据中学习到有效的特征表示和权重分配,从而对未见过的数据做出准确预测。
训练好的神经网络可以用在很多实际场景中:图像分类任务里,卷积神经网络能自动识别物体或图案;自然语言处理任务里,循环神经网络可以理解和生成文本;推荐系统里,多层感知机可以根据用户历史行为做个性化推荐……
这篇文章对神经网络工作机制做了浅层次的讲解,希望能帮你迈出理解AI模型的第一步。如有不正之处,欢迎指教。