今天凌晨,谷歌告别了过去秉持的"克制"态度,全面转向了智能体时代。在刚刚落幕的I/O大会上,谷歌发布的一系列新产品传达出极其清晰的核心理念:打造一个"24小时不间断工作的智能体"。由此看来,由OpenClaw率先掀起的这股智能体浪潮已成定局,未来每个人手中的AI都将在不知疲倦的状态下持续运转。

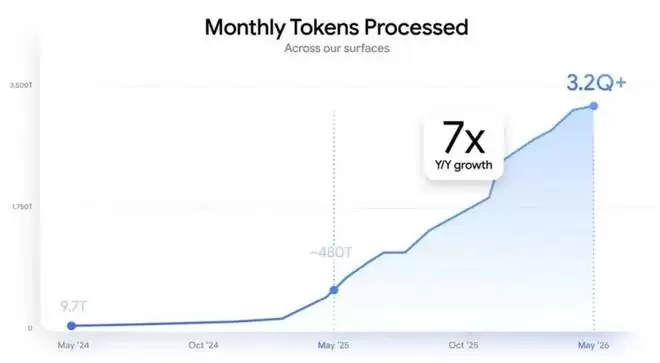
谷歌首席执行官桑达尔・皮查伊在大会上分享了一组关键数据,清晰地揭示了行业竞争焦点的转移:机器学习模型领域的竞争焦点,已经从单纯的指标比拼,全面转向了智能体工程的实际落地。而衡量AI应用普及程度最直观的指标——token消耗量这一AI应用普及度的关键衡量指标,正以惊人的速度增长。两年前,用户每月通过谷歌各类渠道消耗9.7万亿token;去年,这一数字飙升至480万亿;而时至今日,更是在此基础上增长了七倍,达到每月超过3.2千万亿。
生态系统的蓬勃发展同样显而易见。目前,每月有超过850万活跃开发者正在利用Gemini构建新的应用与体验。谷歌旗下一共有13款产品用户量突破10亿大关,其中覆盖5款产品甚至超过30亿用户。这些产品无一例外均以AI技术为驱动。例如,谷歌搜索中集成的"AI模式",月活跃用户早已突破10亿;而Nano Banana图像生成模型则已累计生成了超过500亿张图像。
本次大会的最大亮点,是推出了最新一代模型系列Gemini 3.5。谷歌将其描述为一款融合了前沿智能与行动能力的作品,标志着其在构建更强大智能体的征途中迈出了关键一步。不过,率先亮相的是轻量级版本Gemini 3.5 Flash。这款模型在智能体应用和编程方面展现了业界前沿性能,尤其擅长处理那些复杂、长周期且能产生现实价值的任务。
至于定位更高级的Gemini 3.5 Pro,谷歌坦承目前仍在紧锣密鼓地开发中,仅供内部使用。当皮查伊宣布新旗舰模型尚未准备就绪时,现场观众发出一片叹息声。他只好承诺:"下个月一定亮相。"
而Gemini 3.5 Flash则从即日起正式面向全球用户开放:普通用户可通过Gemini App和Google搜索中集成的AI模式直接体验;开发者则能通过Google Antigra vity开发平台,以及Google AI Studio和Android Studio中的Gemini API进行调用;企业用户则可通过Gemini Enterprise Agent Platform和Gemini Enterprise来获取服务。
Gemini 3.5 Flash:具备面向智能体与编程的前沿性能
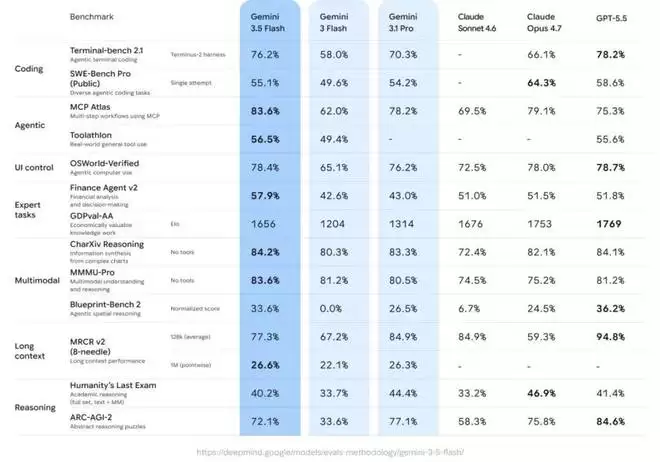
根据官方介绍,Gemini 3.5 Flash在多个智能维度上的表现已接近大型旗舰模型,同时传承了Flash系列一贯的"快速"优势,堪称当前最强的智能体与编程模型。
数据可以作为有力佐证。在Terminal-Bench 2.1、GDPval-AA、MCP Atlas等高难度编程与智能体基准测试中,其得分分别达到了76.2%、1656 Elo和83.6%,表现已经超越Gemini 3.1 Pro。在多模态理解方面,它同样展现出业界领先水平,在CharXiv Reasoning上取得了84.2%的成绩,且按输出token速度计算,要比其他模型快上4倍。
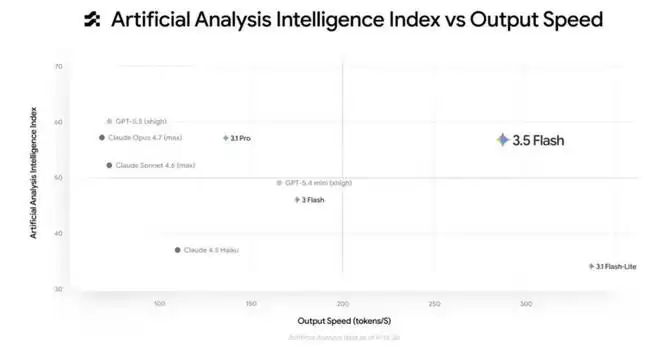
在Artificial Analysis指数中,3.5 Flash被定位在代表高性能与高速度的右上象限。这种速度与性能之间的理想平衡,使其尤其适合处理流程较长的智能体任务。与此同时,其使用成本通常不及其他前沿模型的一半。谷歌为此提出了最新观点:"用户无需再在模型质量与响应延迟之间做出艰难取舍。"
当与全新升级的开发者平台Antigra vity执行框架结合使用时,3.5 Flash能够转化为部署协作式智能体的强大引擎,用于大规模处理最具挑战性的各类任务。在人类监督下,它可以可靠地执行多步骤工作流以及复杂的编程任务,同时保持业界领先的性能水平。
大会现场展示了几个令人印象深刻的实例:借助Antigra vity,3.5 Flash利用两个智能体对AlphaZero相关论文进行深入解析与整合,并在6个小时内成功编写出一款完全可运行的游戏。

在另一个案例中,3.5 Flash利用子智能体在Antigra vity平台中成功构建出全新的城市景观。

此外,值得关注的是,谷歌还显著增强了Gemini 3.5系列模型的网络安全防护能力。新模型严格遵循Frontier Safety Framework进行开发,全面强化了网络安全与CBRN相关安全防护。这意味着,新模型生成有害内容的可能性更低,同时也能更准确地判断并响应安全相关的问题,避免误判。
全家桶式AI应用全面升级
基础模型的重大迭代,自然带动了旗下全线产品的发布与革新。
首先是一款名为Spark的全新AI智能体。它基于Gemini 3.5构建,并与Gmail、Docs和Slides等Google Workspace应用进行了深度集成。用户可以通过自然语言"指导"它执行各类任务,例如在Gmail中创建重要截止日期列表并发送给自己,或者从冗长的邮件往来中提炼出最新进展。你甚至可以设定规则,让它自动执行那些重复性的繁琐任务,比如每月查找信用卡账单中的隐藏费用。
更进一步,你还可以设置规则,让它完成多个相互关联的任务,从而构建完整的工作流。例如,让Spark查看聊天记录和邮件中的会议纪要,在Google文档中自动生成一份精美的报告,并自动撰写一封附带报告的邮件。
谷歌对其核心盈利支柱——搜索业务,进行了有史以来规模最大的革新。引入Gemini 3.5 Flash后,全新的AI模式功能被直接嵌入搜索框,同时允许新的智能体在后台执行搜索任务。
现在,当用户输入搜索查询时,搜索框会自动扩展,提供更充足的交互空间,方便用户使用自然语言继续提问。这个全新的AI搜索框还允许用户在上传图片、视频、文件甚至Chrome浏览器标签页的同时进行搜索,为AI提供丰富的交互参考。
更进阶的功能是给搜索框"派任务":用户可以向搜索智能体提供与查询相关的所有信息,随后智能体将全天候扫描新闻、博客和社交媒体等多元信息源,查找最相关、最新鲜的内容。例如,如果用户正在寻找公寓,他们可以向搜索智能体输入全部住房要求,AI便会持续扫描并推送符合条件的新房源列表。这是谷歌搜索框诞生25年来的首次重大更新。
多模态能力的发展也翻开了新篇章。去年Nano Banana的爆火场景还历历在目,今年谷歌则正式推出了Gemini Omni系列。这是一个将Gemini的推理能力与创作能力深度融合的全新系列,其首个版本为Gemini Omni Flash。作为新一代模型,Omni能够基于任何形式的输入内容来"生成万物"——首批支持的输出生成形式即为视频。
借助Omni,用户可以将图像、音频、视频及文本等多种形式混合作为输入,进而生成基于Gemini现实世界知识的高质量视频。此外,还可以通过自然对话交互的方式,轻松完成对视频的编辑。
来看几个演示案例:例如,输入提示词"把这座雕塑做成泡泡材质",模型便能生成相应的创意视频。
你甚至可以将自己拍摄的一段视频交给Omni,只需告诉它你想把画面里发生的事件改成什么样,它就能修改动作、加入新角色或新物体,甚至将一个瞬间扩展成意想不到的场景。比如,输入提示词"公寓里的灯光开始随着音乐同步亮起",便能实现动态效果。

目前,Gemini Omni Flash正在面向全球范围内的Google AI Plus、Pro和Ultra订阅用户开放,用户可通过Gemini App和Google Flow使用。同时,从本周开始,也将免费向YouTube Shorts和YouTube Create App上的用户开放。未来几周内,则会通过API渠道向开发者和企业客户开放。
或许,本次大会中最令人印象深刻的一句话,来自DeepMind联合创始人德米斯·哈萨比斯:"当我们回顾这段时期时,我想我们会意识到,我们当时正站在技术奇点的山脚下。"这句话,为这场宣告智能体时代全面到来的发布会,写下了一个充满想象力的有力注脚。




