最近有个项目引起了注意,GitHub 上的地址是 interpretml/interpret(链接在文末)。它的目标很明确:既帮你训练可解释的机器学习模型,也帮你解释那些已经训练好的黑盒模型。说白了,就是让模型把判断依据摊开来给你看。
 interpret GitHub 预览
interpret GitHub 预览
 InterpretML 标志
InterpretML 标志
Stars:6,850 | Forks:784 | License:MIT |
|---|
1. 它到底是什么
interpret 是一个开源的可解释性工具包,把所有常用的方法收在同一个包里。你可以用它训练 glassbox 模型(本身就是透明的),也可以给已有的 blackbox 模型做事后解释。
注意,这里不聊聊天、不搞 Agent,也不是 RAG 那一套。它属于 AI 工程里一个老问题,但一直很关键:模型给出预测之后,人到底怎么知道它为什么这么判断。
2. 它解决什么麻烦
很多模型上线前,问题往往不在“能不能跑”,而在“出了结果能不能解释清楚”。
举个场景:风控模型拒绝了一笔申请,医疗模型给出高风险判断,内部预测模型突然偏向某个特征。光看分数远远不够——你需要知道全局上哪些特征最重要,单条预测里哪些因素把结果推高或拉低。
interpret 把这两类视角都塞进了同一个工作流。你可以看模型的整体行为(全局解释),也可以拆开某一次预测,看局部原因。
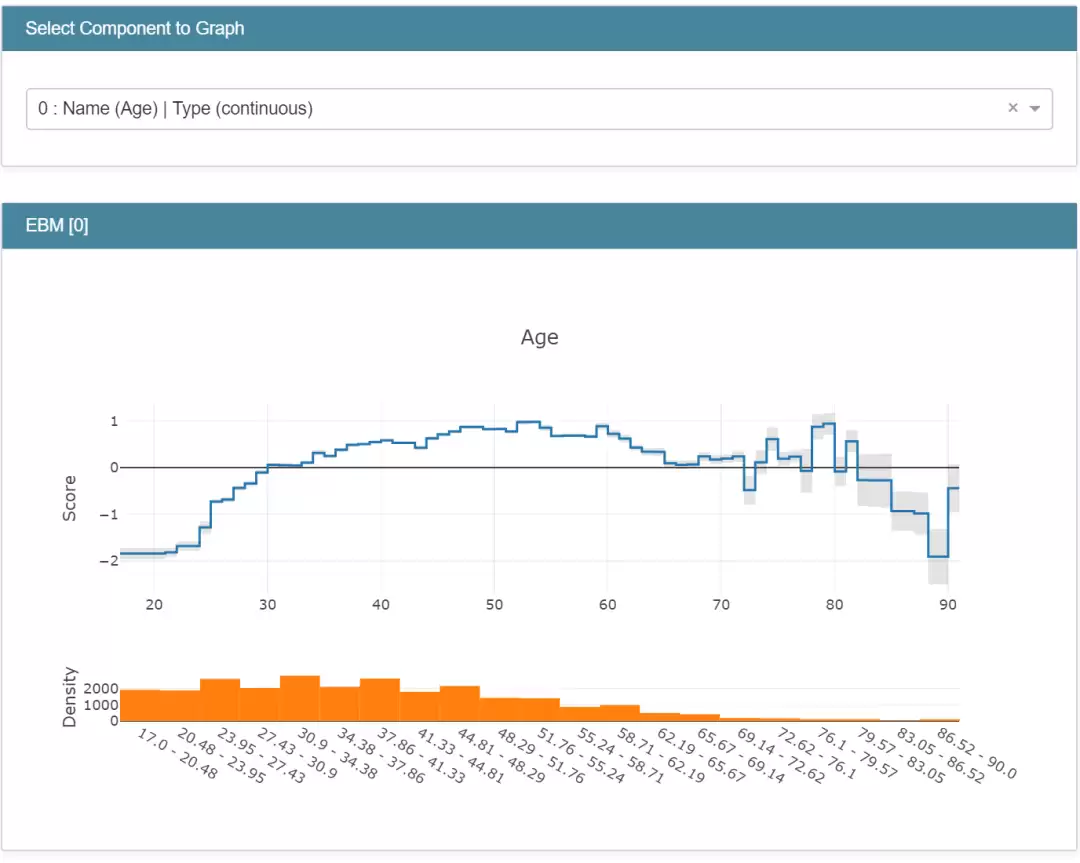 EBM 全局解释
EBM 全局解释
3. 核心看点
最值得关注的,是它把 Explainable Boosting Machine (EBM) 放在了很靠前的位置。
EBM 来自 Microsoft Research。它不是在黑盒模型跑完以后硬套解释,而是从一开始就训练一个本身就很透明的模型。README 里提到,它用了 bagging、gradient boosting、自动交互检测这些方法,把传统 GAM 的表达力往前推了一大步。
用法和普通 Python 机器学习库差不多:
from interpret.glassbox import ExplainableBoostingClassifier
from interpret import show
ebm = ExplainableBoostingClassifier()
ebm.fit(X_train, y_train)
show(ebm.explain_global())
如果要看单条预测,也是同一套接口。
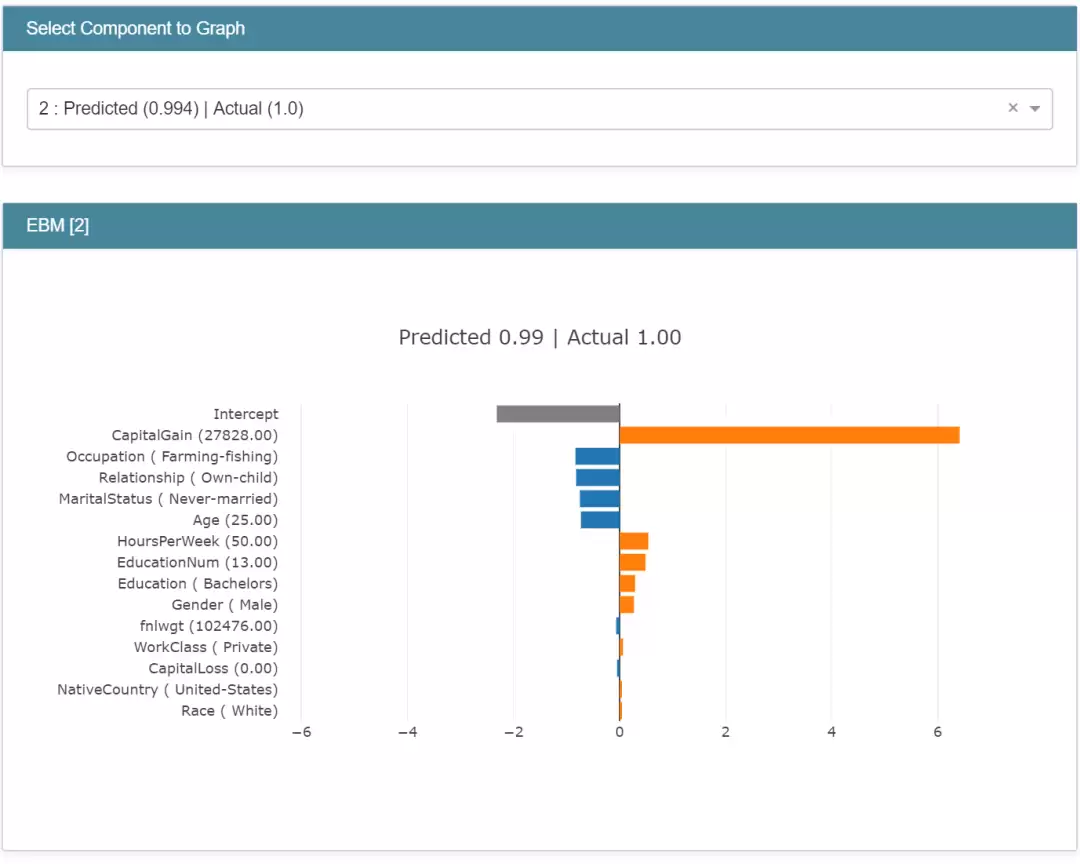 EBM 局部解释
EBM 局部解释
4. 为什么值得看
它真正值得关注的点,不在于 star 数字多漂亮,而在于边界非常清楚。
这个项目没有把自己包装成“全流程 AI 平台”,仓库描述就两句:fit interpretable models,explain blackbox machine learning。反而因此好判断。
如果你需要可解释模型,可以看 glassbox 里的 EBM、APLR、决策树、规则列表、线性模型。如果已经有现成的黑盒模型,也可以看 blackbox explainers 里的 SHAP Kernel、LIME、Partial Dependence、Morris Sensitivity。
此外,它还带了一个 dashboard 视图,多个解释结果可以并排放一起对比,直观很多。
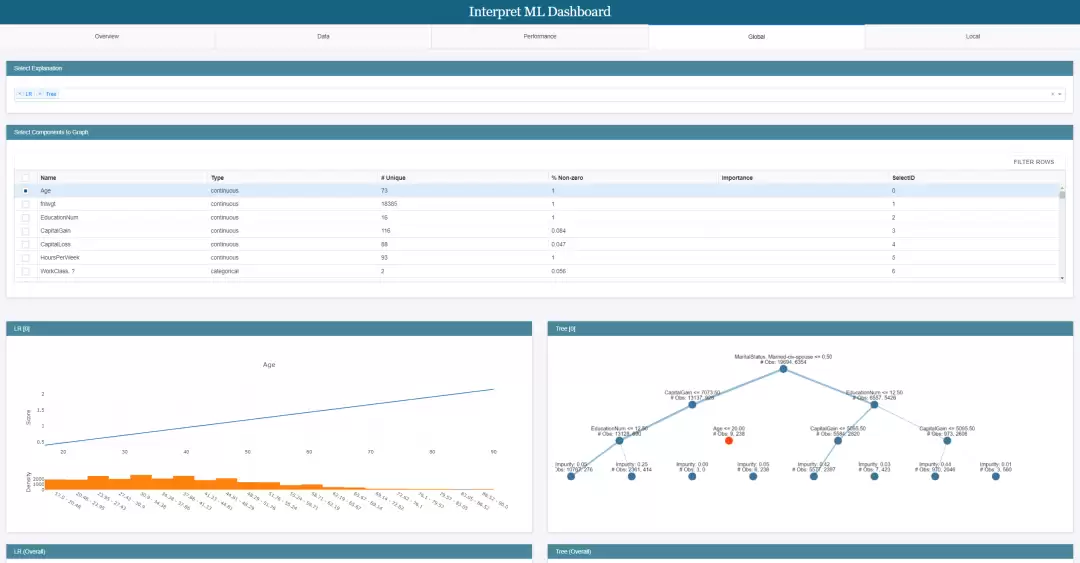 解释结果 Dashboard
解释结果 Dashboard
5. 怎么用起来
安装方式很普通:
pip install interpret
也可以用 conda:
conda install -c conda-forge interpret
README 标注的是 Python 3.10,Linux、Mac、Windows 都支持。PyPI 上当前版本是 0.7.8,发布时间是 2026-03-17。
实际操作时,可以先拿一个小型分类数据集跑 EBM。先跑 explain_global() 确认模型整体在看哪些特征,再用 explain_local() 挑几条预测拆开看。如果团队已经有模型,从 blackbox 解释器入手就行,不用一上来就换模型。
 项目卡片
项目卡片
6. 适合谁,以及先注意什么
这个工具适合做表格数据建模的人。
典型场景包括风控、医疗、运营预测、用户分层、欺诈检测、价格预测等。只要你不是单纯追一个最高分,而是要把模型判断讲给业务、审计、合规或者自己听,interpret 就派得上用场。
但有一点得提醒:可解释性不是免死金牌。解释图能帮你发现模型在看什么,但不能自动证明数据没偏见、业务假设没错、上线后分布不会漂。EBM 也不是所有任务的默认最优解。它更像一个值得认真对照的基线——先让模型把话说清楚,再决定要不要为了更高分去换更复杂的东西。




