先给出几个核心判断:在机器人三维操作领域,扩散策略虽然具备较强的建模能力,但推理速度慢、模型体积大,落地难度几乎是行业共识。流匹配策略虽然已经取得一定进展,但大多数方法仍然死守UNet骨干架构,计算负担和推理延迟依然居高不下。
那么,有没有可能在保持性能的同时,把模型做得更小、跑得更快?

一、整体概述
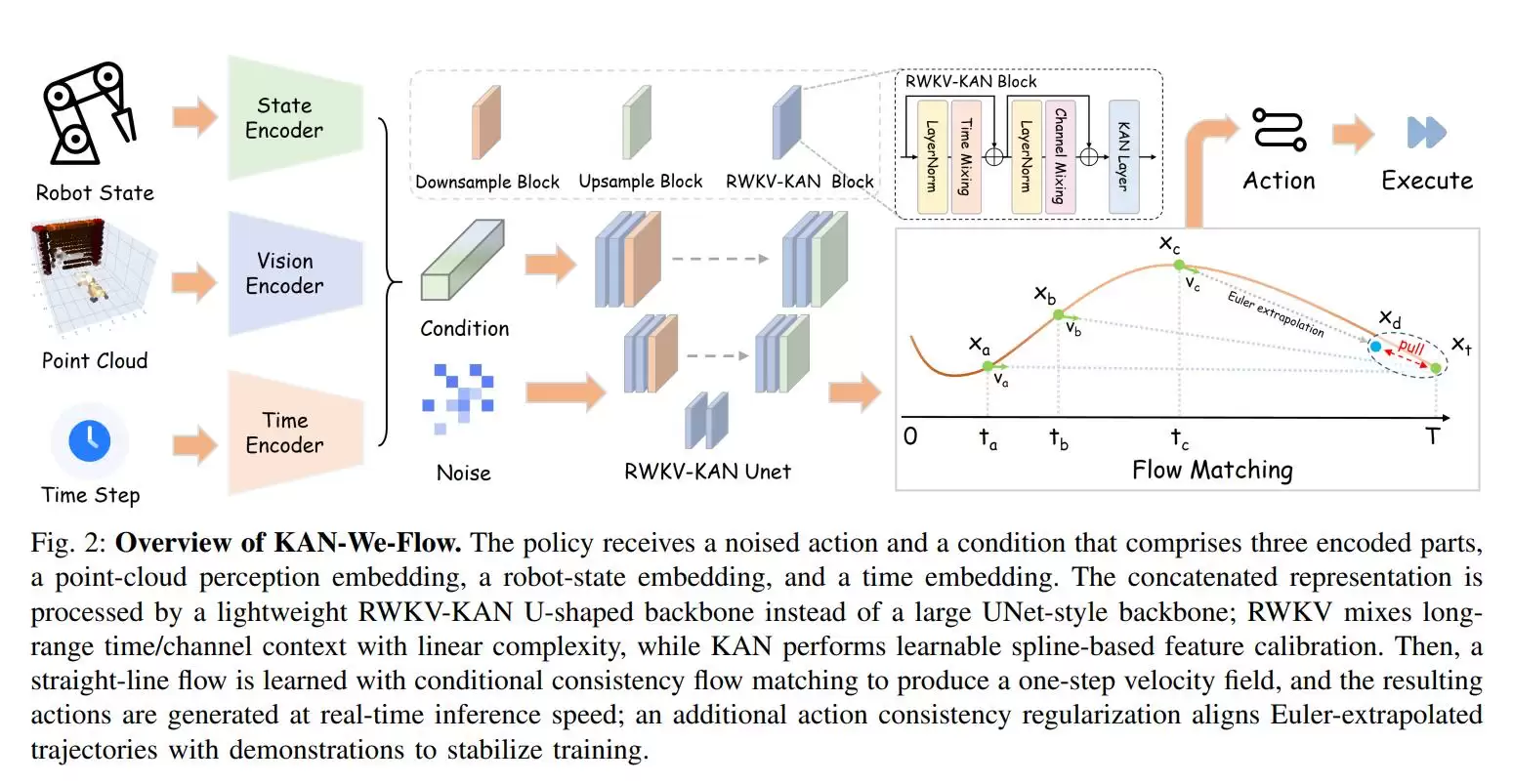
本文要介绍的KAN-We-Flow,正是针对这一问题提出的解决方案。它的思路非常直接:用RWKV加KAN替代传统的大规模UNet骨干网络。结果如何?参数量削减了约86.8%,推理延迟压缩到毫秒级,关键在于——成功率不仅没有下降,反而在Adroit、Meta-World、DexArt三个主流基准上取得了当前最优或并列最优的成绩。
可以这样理解:在保持甚至提升操作精度的前提下,将模型从“重型卡车”换成了“跑车”,并且真正实现了实时控制。
二、研究背景
先来看一下这个领域目前面临的主要瓶颈。
扩散式策略的优点在于动作分布建模能力强,生成的动作更加平滑自然。但代价也很明显:多步去噪、推理慢、模型重,一旦部署到真实机器人上,延迟根本无法承受。
流匹配策略算是一个改进方向,它通过学习一步向量场实现快速生成。然而,现有的流匹配方法依然普遍依赖UNet这类庞大结构,计算和存储开销仍然不小。
因此核心问题其实非常明确:如何在保证精度的前提下,进一步压缩模型大小,同时提升实时性?
三、动机直觉
讲完问题,再看驱动这个方案的直觉。其实并不复杂:
RWKV的线性复杂度时序建模能力,天然适合机器人的长时序动作预测;而KAN通过可学习的一维函数逼近,可以用更少的参数表达更复杂的非线性映射。将两者结合,目标就是同时解决“长时序依赖”和“参数效率”这两个痛点。
换句话说,与其在UNet的大框架下修修补补,不如直接换一个更轻量、更高效的骨干架构。

四、技术路线
整体框架遵循“一致性流匹配”路线,目标是实现一步动作生成。输入包括点云感知信息、机器人当前状态以及时间编码。
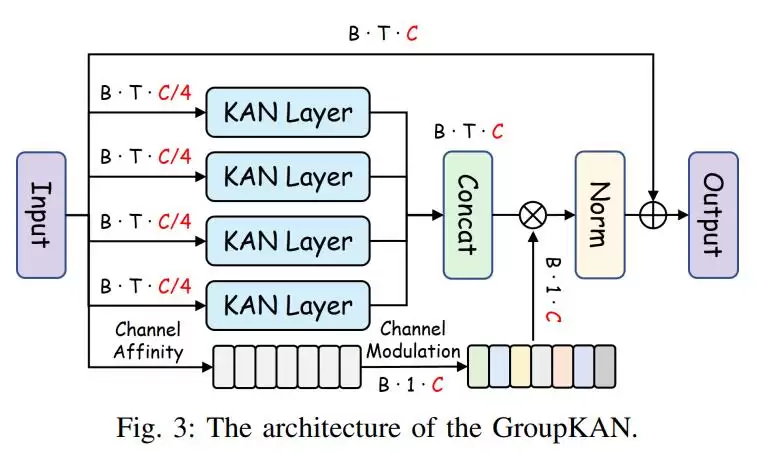
核心网络部分采用RWKV-KAN骨干架构。其中,RWKV负责时间与通道混合,专门建模动作序列的上下文;GroupKAN则对特征通道进行分组,做非线性的函数校准,直接替代传统MLP。
值得特别提及的是Action Consistency Regularization(ACR)。它通过欧拉外推,让一步预测的动作在末端与专家轨迹对齐。这相当于在训练阶段提供了一层额外的监督,能稳定训练,关键是——推理阶段完全没有任何额外开销。
最终的学习目标也很清晰:把一致性流匹配损失与ACR正则项联合起来进行端到端训练。
五、实验结果
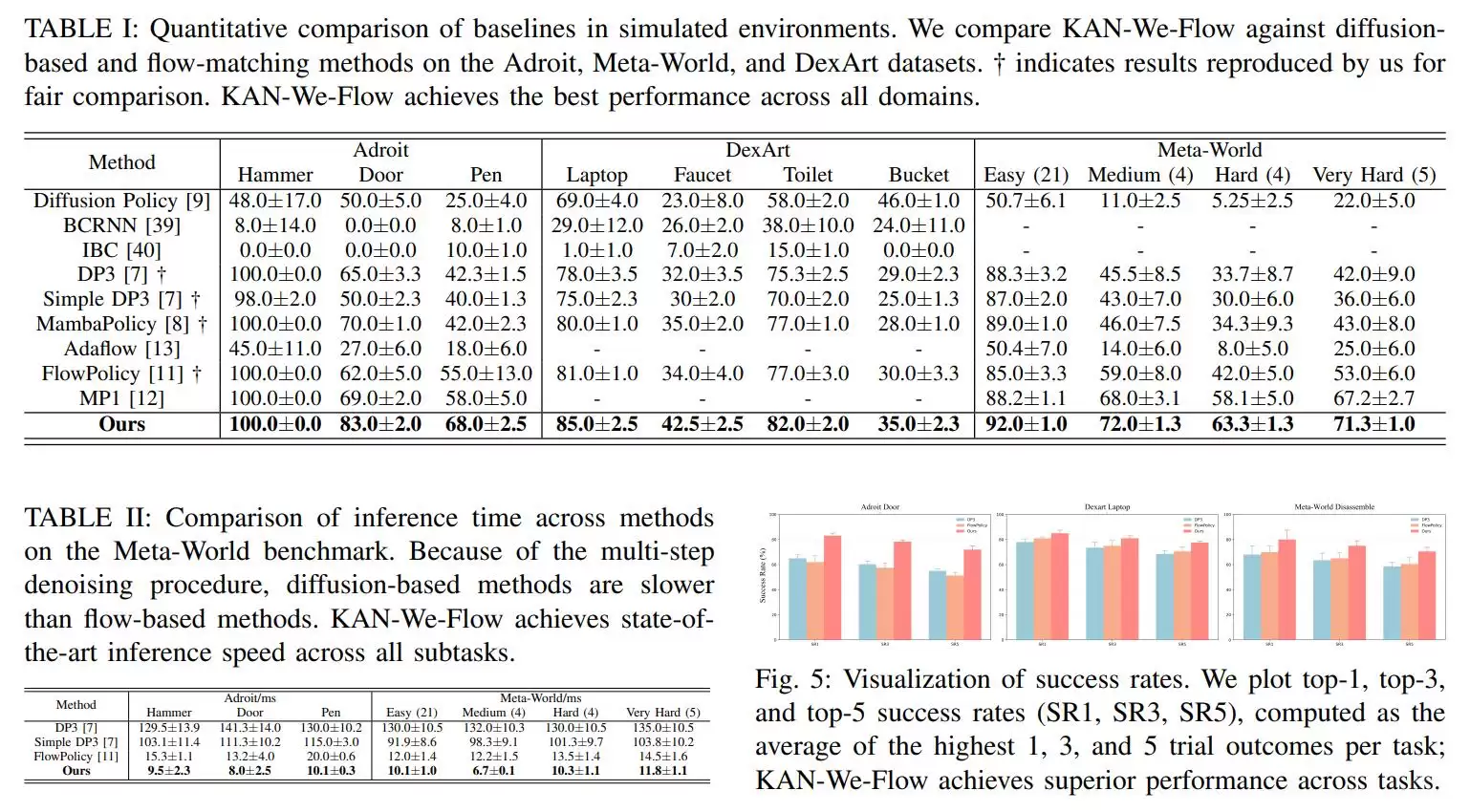
从性能来看,在Adroit、Meta-World、DexArt三个基准上,KAN-We-Flow的整体成功率均优于FlowPolicy和DP3。尤其在高难度、长时序的任务上,优势更为明显。
效率方面的数字更直观:参数量约33.6M,相比DP3减少86.8%;推理时间仅8到11毫秒,足以支撑100Hz的实时控制。
消融实验的结果也符合预期:RWKV、GroupKAN和ACR三个组件对性能都有稳定的正向增益。其中,ACR在长预测窗口下能够明显抑制动作漂移问题。




