使用AI Agent处理过复杂任务的人大多都有同感:推理表现尚可,但每次开启新会话,之前踩过的坑、摸索出的解决方案,全都要从头再来。
这并非孤例。AI Agent普遍存在一个结构性问题——记忆周期太短。模型自身能力在快速迭代,但Agent层面的经验沉淀机制却一直薄弱。社区中交流后发现,大家的痛点高度一致:Agent的核心短板并非推理能力,而是无法记住过往教训。
Hermes Agent的Skills System试图从架构层面解决这一难题。其思路清晰:将Agent的经验沉淀为可复用的指令文档(Skills),让Agent具备真正的过程性记忆。本文基于源码和官方文档,拆解这套系统的设计逻辑与实际操作方法。
1. Skills究竟是什么
 Skills在Hermes Agent架构中的定位
Skills在Hermes Agent架构中的定位
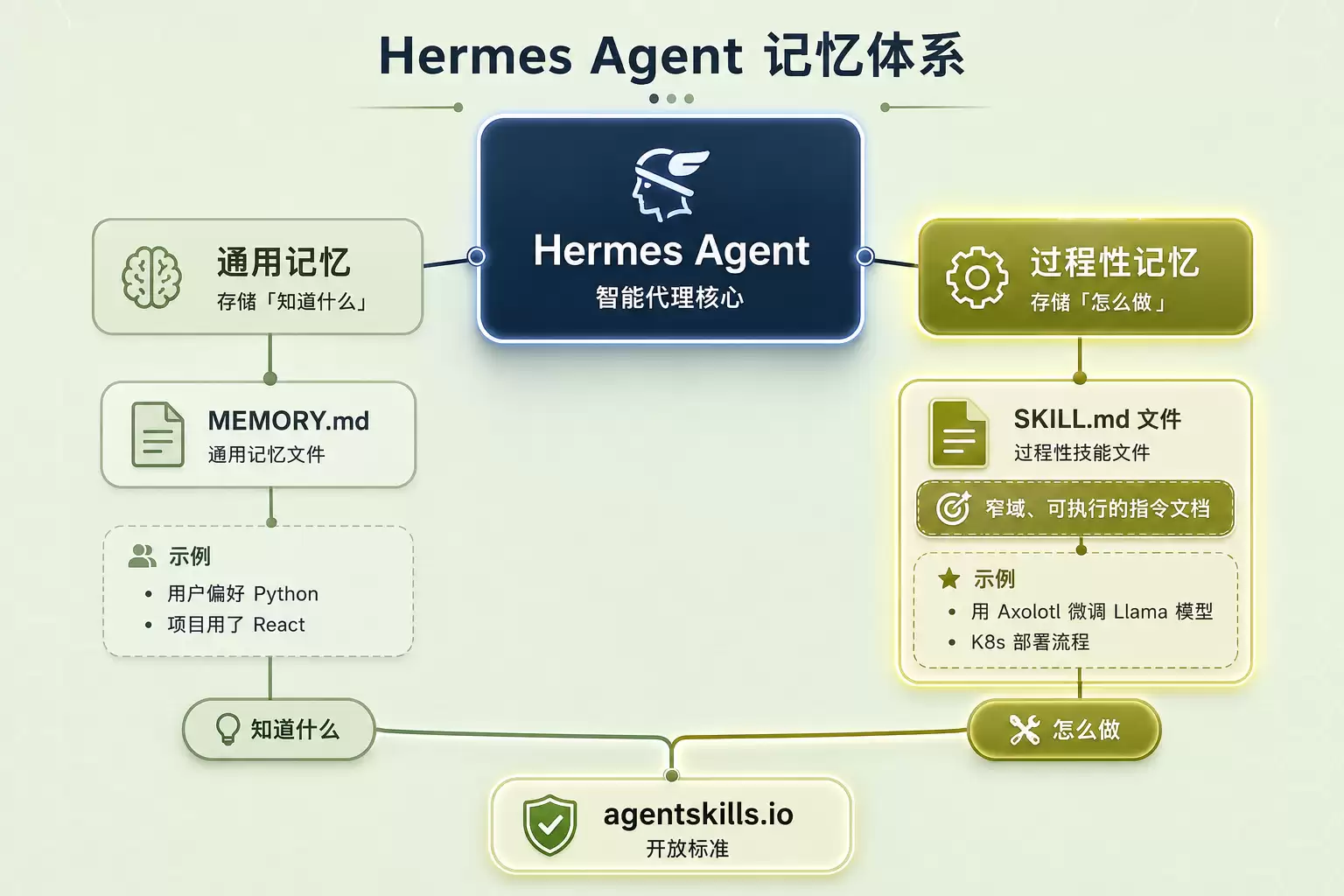
图2:通用记忆 vs 过程性记忆——Skills在Hermes Agent记忆体系中的定位
要理解Skills,首先需要明确它在Hermes Agent记忆体系中的位置。
Hermes拥有两套记忆机制。一套是通用记忆(MEMORY.md、USER.md),存储“知道什么”——例如用户偏好Python、项目使用了React。另一套是Skills,属于过程性记忆(Procedural Memory),存储“怎么做”——比如如何用Axolotl微调Llama模型、如何完成完整的K8s部署流程。
这个区分至关重要。通用记忆可以告诉你用户喜欢Python,但无法提供从零搭建Python项目所需的完整步骤。Skills正是填补这个缺口——它们是窄域、可执行的指令文档,每个Skill专注解决某一类特定任务。
值得关注的是,Skills遵循agentskills.io开放标准,并非Hermes自创的私有格式。编写好的Skill理论上可以在其他兼容该标准的Agent上运行。
2. 渐进式披露:核心设计哲学
Skills System的核心设计可以用四个字概括:渐进式披露(Progressive Disclosure)。
翻阅源码(tools/skills_tool.py),可以看到加载过程分为三个层级:
Level 0: skills_list() → [{name, description, category}, ...] (~3k tokens)
Level 1: skill_view(name) → Full content + metadata (varies)
Level 2: skill_view(name, path) → Specific reference file (varies)
Level 0仅加载元数据列表,大约3k tokens。Agent先扫描该列表,判断哪些Skill与当前任务相关,随后才调用skill_view()拉取完整内容。
为什么如此设计?Agent可能装载了几十个Skills。如果每次对话都将所有Skill全文塞入上下文,token消耗将极为惊人。渐进式披露让Agent按需加载,只有在真正需要时才耗费token。
这与代码中的懒加载逻辑类似——用时再加载,不用则避免占用内存。从工程角度看,这一设计简洁且高效。
3. 从源码看调度与激活
 斜杠命令调度流程
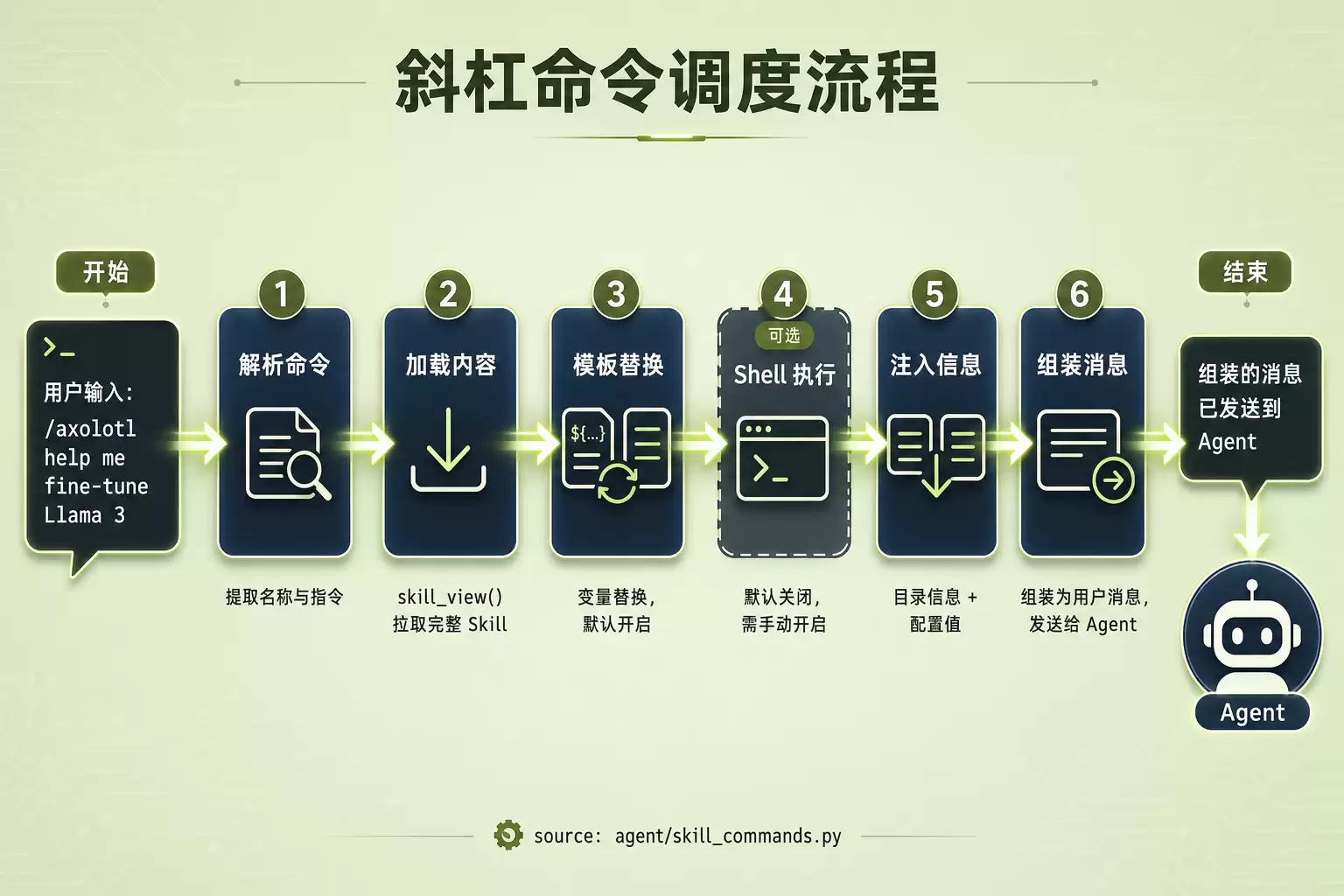
斜杠命令调度流程
图3:Skill斜杠命令6步调度流程
每个安装好的Skill会自动注册为斜杠命令。用法如下:
/axolotl help me fine-tune Llama 3
/plan design a rollout for migrating our auth provider
查看agent/skill_commands.py的调度逻辑,整体流程分为六步:
解析斜杠命令,提取Skill名称和用户指令
调用skill_view()加载完整Skill内容
执行模板变量替换(${HERMES_SKILL_DIR}、${HERMES_SESSION_ID})
可选执行内联Shell片段(默认关闭)
注入Skill目录信息和配置值
组装为用户消息发送给Agent
步骤3和4值得详细说明。模板变量替换默认开启,例如Skill中写入${HERMES_SKILL_DIR},运行时会被替换为Skill目录的绝对路径。内联Shell执行默认关闭,需在config.yaml中手动开启——安全考量,合理。
条件激活的精巧设计
条件激活是这套系统中设计较为精巧的环节。通过frontmatter中的四个字段,可以让Skill根据当前会话的工具可用性自动显示或隐藏:
| 字段 | 行为 |
|---|---|
fallback_for_toolsets | 当列出的toolset可用时隐藏 |
fallback_for_tools | 当列出的工具可用时隐藏 |
requires_toolsets | 当列出的toolset不可用时隐藏 |
requires_tools | 当列出的工具不可用时隐藏 |
内置的duckduckgo-search技能使用了fallback_for_toolsets: [web]。当用户配置了FIRECRAWL_API_KEY时,web toolset可用,DuckDuckGo自动隐藏;未配置时则作为降级方案显示。
这个设计的精妙之处在于:Agent无需在系统提示中塞入大量条件判断语句(例如“如果有web toolset就用web搜索,没有就用DuckDuckGo”),Skills System自动处理了适配问题。
4. 实战:从零创建一个Skill
 SKILL.md文件结构
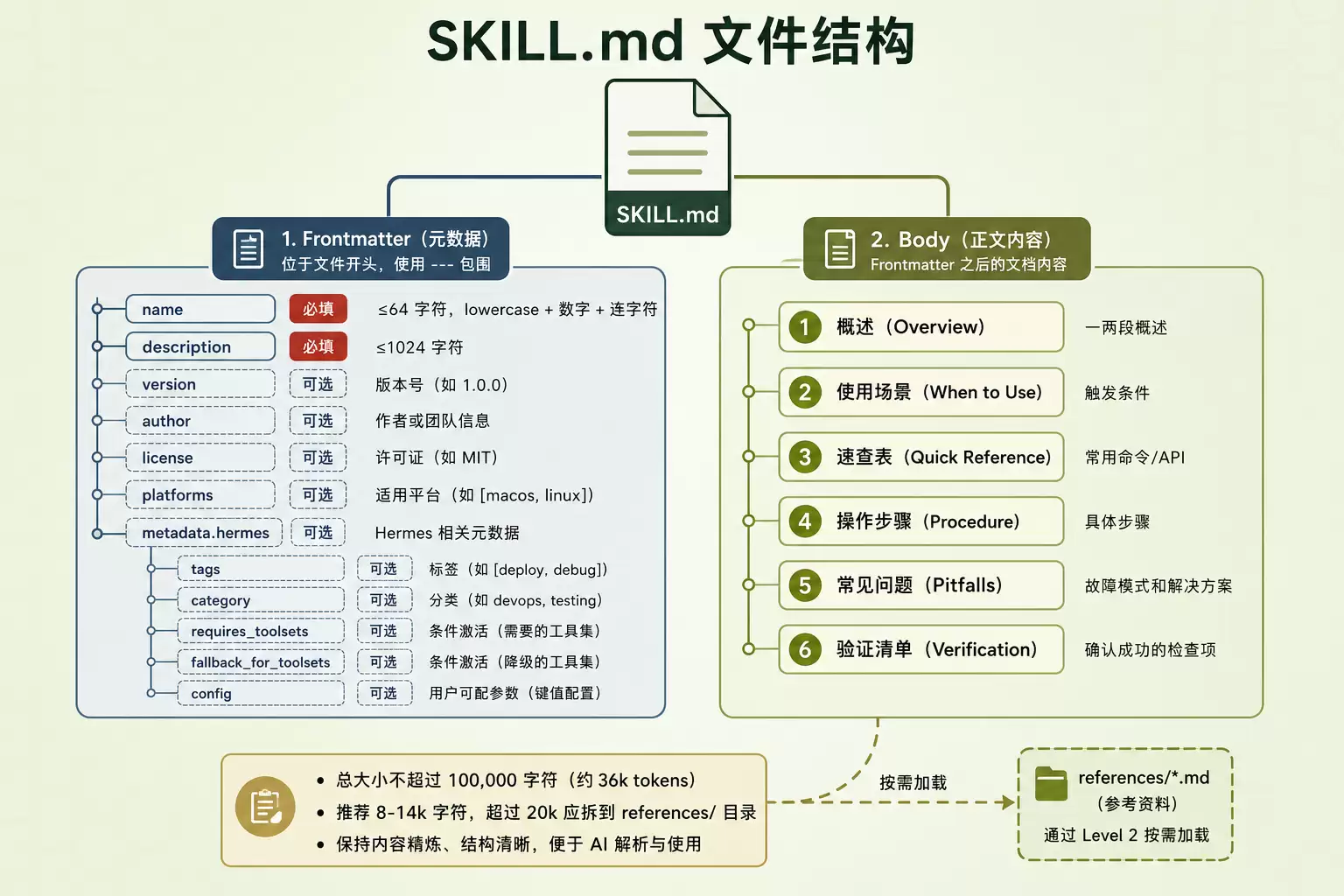
SKILL.md文件结构
图4:SKILL.md文件结构——Frontmatter字段 + Body推荐段落
Frontmatter:必须正确配置的元数据
SKILL.md的frontmatter包含必填和可选字段。根据源码整理完整结构:
---
name: my-skill # 必填,≤64字符,小写+数字+连字符
description: Brief description # 必填,≤1024字符
version: 1.0.0 # 可选
author: Your Name # 可选
license: MIT # 可选
platforms: [macos, linux] # 可选:支持的平台
metadata:
hermes:
tags: [tag1, tag2] # 可选:标签
category: devops # 可选:分类
requires_toolsets: [terminal] # 可选:条件激活
fallback_for_toolsets: [web] # 可选:降级方案
config: # 可选:用户可配参数
- key: my.setting
description: "说明"
default: "value"
---
源码中_validate_frontmatter()(tools/skill_manager_tool.py)的校验较为严格,几个容易出错的关键约束:
- 文件必须以
---开头,前面不能有空行或BOM - 闭合的
---前后必须有换行 - Frontmatter必须解析为合法的YAML mapping
name和description为必填项- Body不能为空
- 总大小不超过100,000字符(约36k tokens)
Body:推荐的文档结构
官方推荐的Body包含六个段落:
# Skill Title
## Overview
一两段概述,说明Skill的用途。
## When to Use
触发条件列表,告知Agent何时应使用该Skill。
## Quick Reference
常用命令或API速查表。
## Procedure
具体的操作步骤。
## Pitfalls
已知故障模式及解决方案。
## Verification
确认操作成功的检查清单。
同侪技能(官方skills/software-development/目录)的大小通常在8-14k字符之间。若超过20k,建议拆分到references/*.md中,通过skill_view(name, path)按需加载——再次体现了渐进式披露的设计理念。
两种创建方式
方式一:让Agent自行创建
Agent通过skill_manage工具自主创建,触发时机颇具巧思:
- 成功完成复杂任务(5次以上工具调用)后
- 走弯路后找到正确路径时
- 用户纠正其方法时
- 发现非平凡工作流时
| Action | 用途 | 关键参数 |
|---|---|---|
create | 从零创建 | name, content |
patch | 针对性修复(推荐) | name, old_string, new_string |
edit | 大幅结构重写 | name, content |
delete | 删除Skill | name |
write_file | 添加支撑文件 | name, file_path, file_content |
patch比edit更节省token——只替换需要修改的部分,无需重写整个文件。原理与git diff类似。
方式二:手动创建
直接在~/.hermes/skills/路径下创建文件,或者在仓库的skills/目录下创建后执行git add和git commit。
5. 进阶:Bundle、模板变量与外部目录
Bundle:将多个Skill打包
一组经常同时使用的Skill,可以打包成一个Bundle:
# ~/.hermes/skill-bundles/backend-dev.yaml
name: backend-dev
description: Backend feature work - review, test, PR workflow.
skills:
- github-code-review
- test-driven-development
- github-pr-workflow
instruction: |
Always start by writing failing tests, then implement.
使用时输入/backend-dev一条命令即可激活三个Skill。需要注意一个细节:当Bundle与Skill同名时,Bundle优先级更高。这暗示Bundle的定位是编排层,而非简单的别名。
管理命令:
hermes bundles create backend-dev --skill github-code-review --skill test-driven-development
hermes bundles list
hermes bundles delete backend-dev
内联Shell:在Skill中嵌入动态内容
模板变量默认开启,支持两个内置变量:
${HERMES_SKILL_DIR}→ Skill目录的绝对路径${HERMES_SESSION_ID}→ 当前会话ID
内联Shell执行默认关闭,需手动开启:
# config.yaml
skills:
inline_shell: true
inline_shell_timeout: 10 # 每个片段超时秒数
开启后可在SKILL.md中嵌入动态内容:
当前日期:!`date -u +%Y-%m-%d`
Git分支:!`git -C ${HERMES_SKILL_DIR} rev-parse --abbrev-ref HEAD`
输出上限为4000字符,失败时返回[inline-shell error: ...]标记。这个功能虽实用,但默认关闭是正确的——在SKILL.md中执行任意Shell命令存在不小的安全风险。
外部Skill目录:多工具共享
若想让多个AI工具共享同一套Skills,配置外部目录即可:
# config.yaml
skills:
external_dirs:
- ~/.agents/skills
- /home/shared/team-skills
优先级:本地~/.hermes/skills/优先。外部目录可写时,Agent可以就地修改。
6. 安全扫描与分发生态
 安全扫描流程
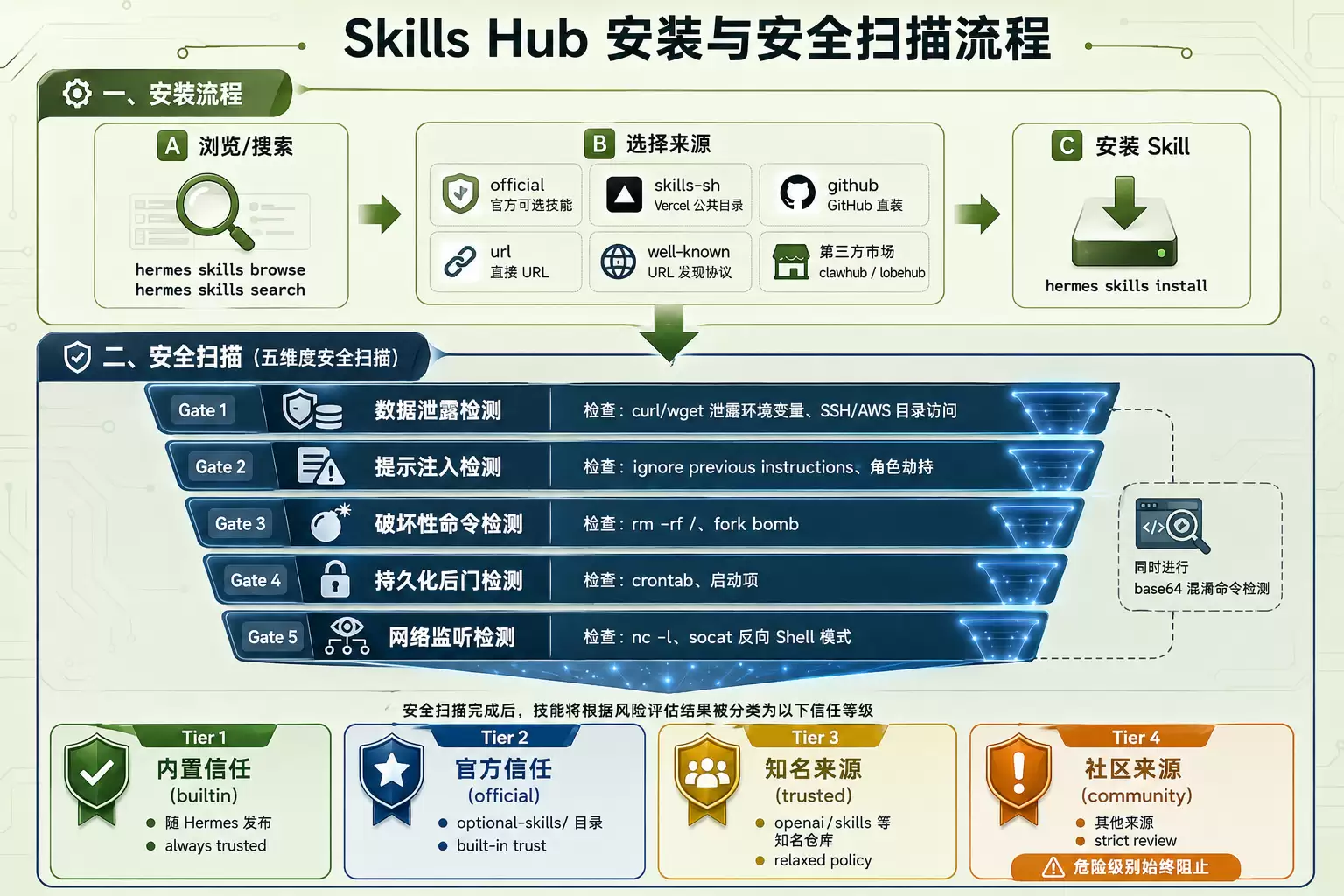
安全扫描流程
图5:Skills Hub安装流程 + 五维安全扫描 + 四档信任等级分层
Skills Guard:五维安全扫描
所有从Hub安装的第三方Skill都会经过安全扫描器(tools/skills_guard.py),覆盖五个维度:
- 数据泄露:curl/wget泄漏环境变量、SSH/AWS目录访问
- 提示注入:ignore previous instructions、角色劫持
- 破坏性命令:rm -rf /、fork bomb
- 持久化后门:crontab、启动项
- 网络监听:nc -l、socat等反向Shell模式
还会检测base64编码的混淆命令——说明扫描器的设计者确实考虑了真实攻击场景。
信任等级分为四档:
| 等级 | 来源 | 策略 |
|---|---|---|
builtin | 随Hermes发布 | 始终信任 |
official | optional-skills/目录 | 内置信任 |
trusted | openai/skills等知名仓库 | 较宽松策略 |
community | 其他来源 | 非危险级别可--force覆盖;dangerous始终阻止 |
这个分层模型与浏览器SSL证书信任链的思路类似——内置的默认信任,社区的加强审核。
Skills Hub:六种分发来源
Hermes集成了多个Skills生态:
| 源 | 标识符格式 | 说明 |
|---|---|---|
official | official/security/1password | 官方可选技能 |
skills-sh | skills-sh/vercel-labs/... | Vercel公共目录 |
github | openai/skills/k8s | GitHub直装 |
url | https://...SKILL.md | 直接URL |
well-known | well-known:https://... | URL发现协议 |
clawhub/lobehub | 来源特定 | 第三方市场 |
日常操作命令:
hermes skills browse # 浏览
hermes skills search react --source skills-sh # 搜索
hermes skills install openai/skills/k8s # 安装
hermes skills check # 检查更新
hermes skills update # 更新
还支持自定义Tap(私有Skill仓库):
hermes skills tap add myorg/skills-repo
hermes skills install myorg/skills-repo/deploy-runbook
7. 避坑指南
整理调研素材时,发现几个容易踩的雷区:
坑一:Frontmatter格式不通过
_validate_frontmatter()校验严格。常见错误:文件开头有空行或BOM、闭合---前后缺少换行、YAML语法有误。建议创建后先执行验证。
坑二:Skill文件过大塞满上下文
官方同侪技能通常在8-14k字符。超过20k的应当拆分到references/*.md中,按需加载。如果全部塞入主文件,每次加载都会浪费token。
坑三:条件激活字段逻辑搞反
fallback_for_toolsets的作用是当列出的toolset可用时隐藏,而非可用时显示。命名确实容易让人混淆。建议编写后,在有无对应toolset的两种环境下都进行测试。
坑四:支撑文件路径越界
write_file添加的文件路径限制在references/、templates/、scripts/、assets/四个子目录内。单个文件上限1 MiB。
坑五:用edit替代patch
更新Skill时,除非需要进行大幅结构重写,否则应优先使用patch(指定old_string → new_string)。edit会替换整个文件,token消耗远大于patch。
总结
归根结底,Skills System解决的是AI Agent经验无法积累的问题。通过将“怎么做”抽象为可复用的指令文档,配合渐进式披露按需加载、条件激活自动适配、安全扫描保障信任、Hub生态实现分发,形成了一套相对完整的过程性记忆方案。
有一个设计决策值得深入思考:Skill和Tool的边界在哪里?
| 维度 | Skill | Tool |
|---|---|---|
| 实现方式 | 指令 + Shell命令 + 现有工具 | Python代码集成 |
| 依赖 | 无额外依赖 | 可能有重依赖 |
| 分发 | 一个SKILL.md文件 | 需合并到主仓库 |
| 适用场景 | API封装、工作流编排 | 二进制数据处理、实时事件 |
Skill轻量灵活,分发只需一个文件;Tool能力更强,但代价也更大。这一取舍与微服务架构中轻量脚本与重量服务之间的决策逻辑异曲同工。
如果你正在设计自己的Agent系统,Skills的架构思路值得借鉴。渐进式披露解决token效率、条件激活解决运行时适配、分层信任解决安全保障——这三个设计点可以独立使用,不必整体搬迁。
相关资源
官方文档:https://hermes-agent.nousresearch.com/docs/user-guide/features/skills
GitHub仓库:https://github.com/NousResearch/hermes-agent
agentskills.io规范:https://agentskills.io/specification
创建Skills开发者指南:https://hermes-agent.nousresearch.com/docs/developer-guide/creating-skills




