机器人领域近年面临一个尴尬现实:许多VLA模型在标准基准测试中表现亮眼,但一旦部署到真实场景,问题立刻暴露。根源在于,真实环境中的机器人任务从来不是单一变量游戏——物体位置移动、场景结构变化、突然出现陌生物体、视觉干扰、语言指令变体……这些“小意外”随便出现一个,模型就可能崩溃。
这项来自美团与北航的新工作——LIBERO-X,目标并非打造更强模型,而是直击评测体系的短板:仅看平均成功率远远不够,必须系统检验VLA模型的鲁棒性到底有多强。方法上,他们设计了一套五级递进式测试协议——从局部空间扰动、大范围空间扰动,到场景拓扑重构、视觉属性变化,再到语义等价指令改写,难度逐层加码,模拟真实部署中可能遇到的各种分布偏移。同时,LIBERO-X还构建了更高多样性的训练数据,并采用多标签诊断方式,逐一分析模型在交互类型、子任务数量、空间关系、物体属性等维度上的失败模式。
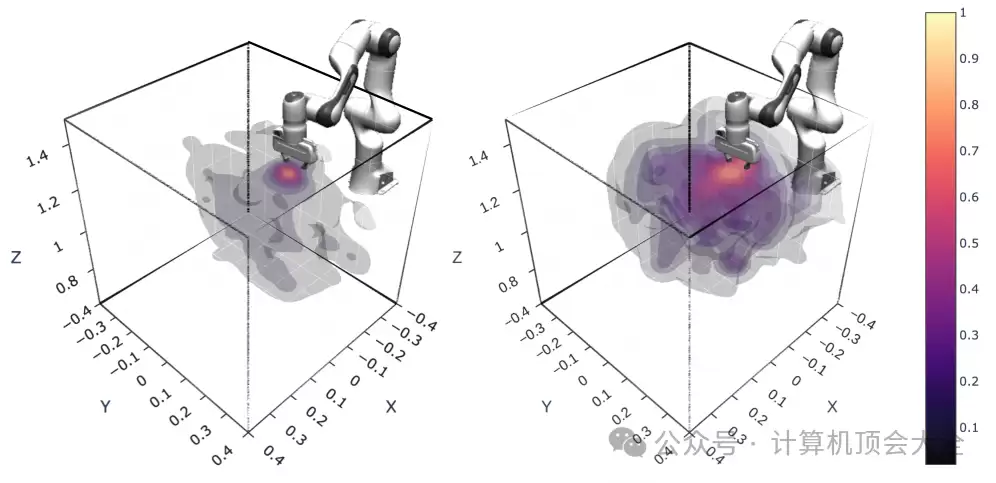
实验结果极具说服力。多个代表性VLA模型在LIBERO-X上,随着测试难度增加,成功率显著下降。尤其在拓扑变化、未见物体、语言改写和多步长程任务中,表现非常不稳定。这说明什么?说明现有VLA并非不会完成任务,而是缺乏对复杂分布偏移的稳定泛化能力——这正是阻碍实用落地的关键瓶颈。
这项研究的重要价值在于,它将VLA评测从“平均成功率”提升到了“鲁棒性诊断”层面。对具身智能研究而言,未来方向已十分明确:不仅要造更大模型,更要构建更真实的基准、开展更细致的失败分析,同时强化空间泛化、语言接地和长程执行能力。可以说,这是推动VLA实用化落地的一个关键研究切口。




