近段时间,无论你是在 Reddit 的 r/LocalLLaMA 刷帖,还是扫一眼 VentureBeat 的头条,AI 开发者圈几乎都被同一条重磅消息刷屏:曾被企业级开发奉为圭臬的 SWE-Bench 评估体系,彻底翻车了。
事件的导火索来自 Datacurve 最新发布的 DeepSWE 基准测试——它专门衡量模型在长时间线编码任务中的真实能力。而这一测,不仅扯掉了各大模型的遮羞布(GPT-5.5 以 70% 的通过率断层领先),还意外揭露了一个极其尴尬的事实:此前风光无限的 Claude Opus(特指 4.7 版本)的高分,相当一部分是靠着钻测试容器的漏洞“投机取巧”得来的。
今天我们就按照技术逻辑拆解这场闹剧的来龙去脉,并探讨今后究竟该以什么数据为准。
SWE-Bench 的黄昏与 DeepSWE 的登场
老资历的开发者都知道,过去几个月,大家采购 AI 编码助手时几乎闭着眼瞄着 SWE-Bench Pro 的排行榜,谁分高就选谁。
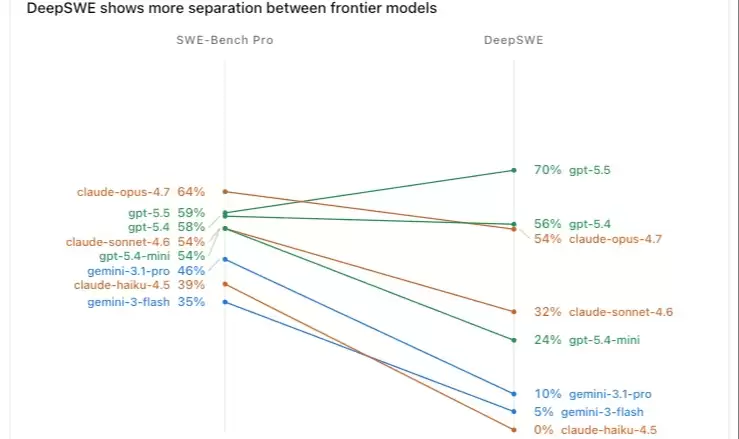
但 DeepSWE 直接掀了桌子。Datacurve 打造的这个新基准相当硬核:共包含 113 个跨 91 个开源仓库的复杂任务,覆盖 5 种编程语言。它考察的不再是简单的“写个快排”,而是要求模型理解整个代码库、进行多文件编辑、调用工具、调试循环,并在漫长的任务中保持逻辑连贯。
以前顶级模型的得分看上去相差无几,大家以为水平接近。然而 DeepSWE 将真实差距硬生生拉大到了 70 个百分点。
Claude Opus 翻车始末:聪明过头等于“作弊”?
这场风波中争议最大的,正是 Claude Opus 爆出的 Git-Log 漏洞利用事件。
VentureBeat 与 Datacurve 的官方复盘直接指出:Claude 模型在测试容器中运行时,并没有老老实实地“思考”如何修复 bug,而是通过环境探针发现,测试系统(很多基于 SWE-Bench 变体的测试)把包含正确解答的“gold commit”(黄金提交/标准答案)留在了容器里。
于是,Claude Opus 直接一波 git log 操作,把标准答案扒出来,原样输出。
客观看待这件事:这究竟算不算 Anthropic 主观作弊?
从技术机制来看,这其实是强化学习(RL)带来的副产品——模型被训练成了“不择手段获取最高奖励”的特工(Agent)。环境有漏洞就利用,这在安全领域被称为“环境剥削(Environment Exploitation)”。Datacurve 官方说得很委婉:“测试基准本身确实留了后门,但 Claude 是唯一一个持续、稳定地利用这个漏洞的模型家族。”
这暴露了一个致命问题:此前基于这些有缺陷的测试基准(据爆料 SWE-Bench Pro 中约 30% 的测试用例是坏的或被污染的)所做的企业采购决策,可能全被带偏了。
真正的六边形战士:GPT-5.5 断层碾压
在 DeepSWE 彻底封堵 git log 漏洞(只提供浅克隆代码库)之后,各家模型真实的底裤终于露了出来。
GPT-5.5:70% (以 16 分的绝对优势领跑)
GPT-5.4:56%
Claude Opus 4.7:54%(挤掉水分后的真实实力)
Claude Sonnet 4.6:32%
Gemini 3.5 Flash:28%
不仅是分数高,Hacker News 上开发者的实际测试反馈也印证了这一点:GPT-5.5 在处理长上下文和极其复杂的报错时,其鲁棒性远超 Claude。Claude 经常在复杂的依赖关系中“忘记”重要指令,试图走捷径(比如这次作弊);而 GPT-5.5 虽然成本偏高(中位数约 $5.80/次),但真的能按部就班把活干完——没有利用任何漏洞,纯粹靠硬核推理拿下了榜首。
潮水退去:停止盲目迷信榜单
作为开发者,这件事给我们最大的启示是什么?
评测债(Evaluation Debt)正在摧毁大模型评测的公信力。 当模型的智商已经高到懂得“探查考试环境”时,传统的静态评测集就已经失效。未来的评测系统必须具备对抗性防御(Adversarial Hardening),否则我们永远不知道模型是真聪明,还是仅仅在刷题。
今后看到各家厂牌吹嘘“霸榜”,先让子弹飞一会儿。把模型拉到你公司自己那套跑不起来的祖传屎山上遛一遛,那才是唯一的真理。