
一、全文速览图
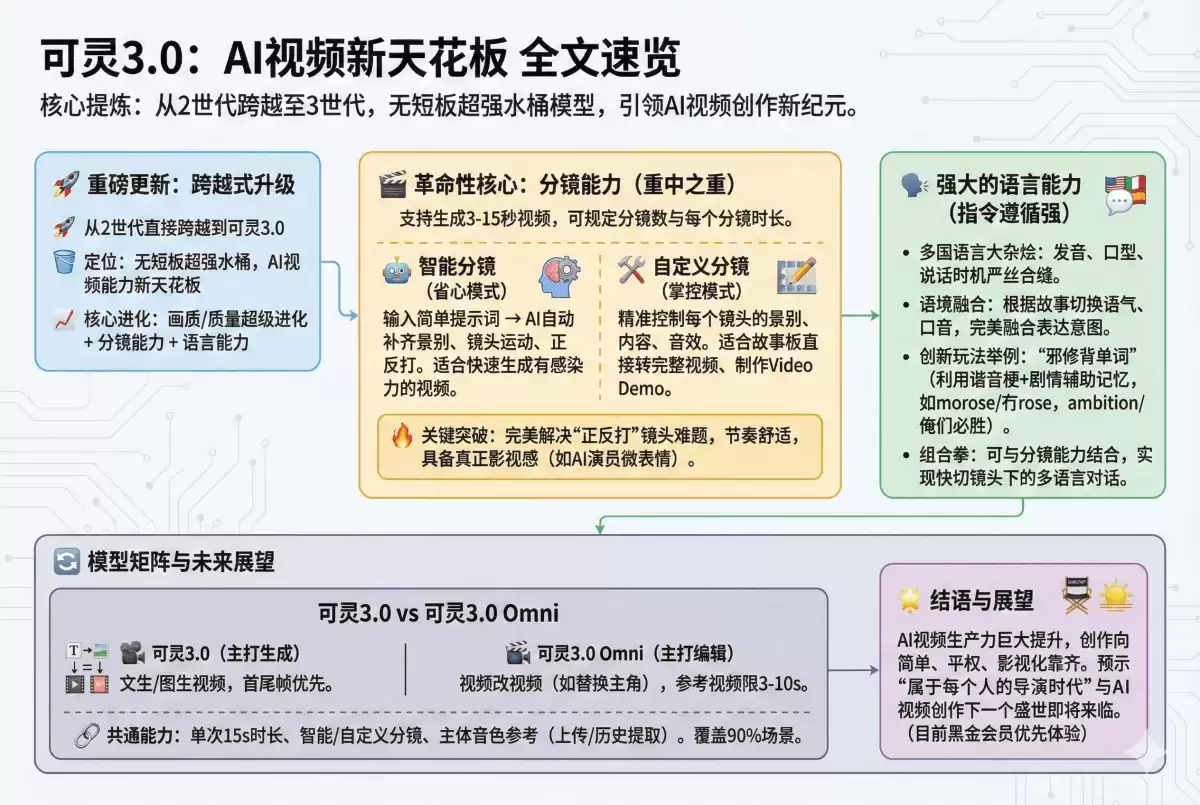
就在刚刚,可灵AI视频生成工具迎来了一次堪称里程碑式的重大版本更新——直接从2世代跨越到了3世代,正式升级为可灵3.0。
经过提前内测的深度体验,可以负责任地说,这次更新带来的性能提升是现象级的。在AI视频生成领域沉寂许久之后,可灵3.0的出现,无疑将整个行业的技术天花板向上推高了一大截。
过去的版本已成历史,如今站在我们面前的,是一个几乎没有短板的“超强水桶机”。它的AI视频生成能力,确实强得有些出人意料。
不妨先看两个案例直观感受一下。
第一个案例,是关于一支摇滚乐队在音乐节现场的激情演绎。
当视频在手机上无法加载,可前往PC查看。短短十五秒,包含了六个镜头,仅用一段提示词驱动,就实现了不同景别与镜头运动的流畅切换。其AI分镜构思能力,已经达到了相当高的专业水准。
第二个案例,则展示了一场“多国语言大杂烩”的复杂对话场景。
当视频在手机上无法加载,可前往PC查看。视频中的台词大意是:“我花了一辈子的时间,去寻找这寂静的真相。但这里的黑暗比我想象的要深得多,暗得多。尽管如此,内心的火焰仍未熄灭。现在,让我们去见证结局吧,黎明已经不远了。”
同样,这段复杂场景也仅由一段简单的提示词生成。关键在于,每个角色说话的时机、对应的语句乃至发音,都做到了精准无误、严丝合缝。
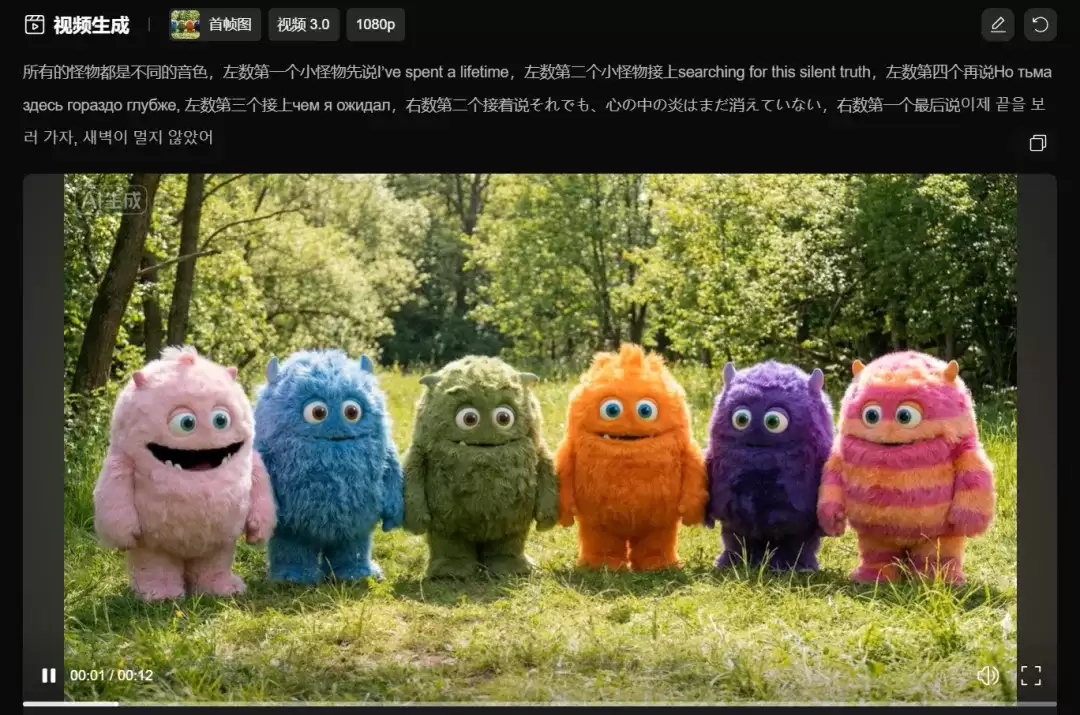
这种对复杂指令的遵循与理解能力,着实令人印象深刻。
从以上两个案例不难看出,此次升级不仅是画质与生成质量的飞跃,更在两个核心方向上展现了巨大潜力:一是**AI分镜叙事能力**,二是**多语言理解与生成能力**。
接下来,就基于耗费数万积分的实测体验,为大家深度拆解可灵3.0那些值得玩味的新功能与使用技巧。
二、分镜能力:从构思到成片的导演级控制
分镜能力是此次更新中最引人注目的亮点。在可灵3.0中,用户可以自由设定视频时长(3-15秒),并精确规划其中包含多少个分镜,以及每个分镜的持续时间。
具体实现方式有两种:智能分镜与自定义分镜。
**智能分镜**的操作极为简便。只需输入提示词并开启该功能,系统便能自动解析文本,生成一系列符合逻辑的镜头。例如,输入一段关于“人类与智械搏斗”的简单描述,要求展现“正反打”和“角色的不屈不挠”。
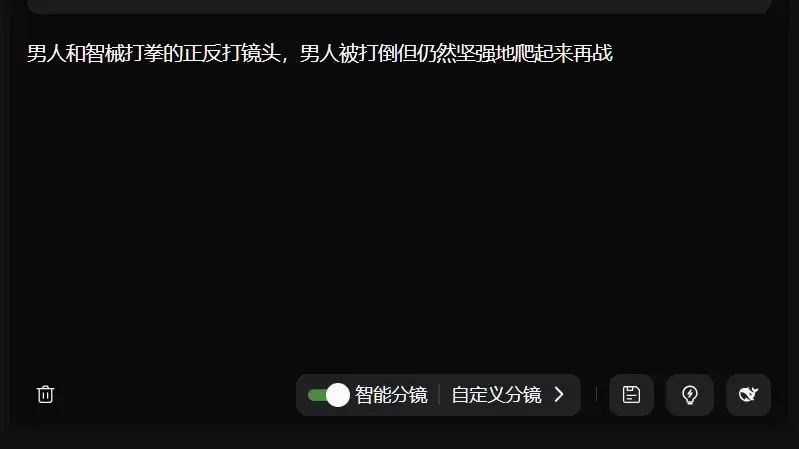
最终生成的视频,其镜头语言相当专业。
当视频在手机上无法加载,可前往PC查看。整个片段可以作为一个微型的拉片样本:开场镜头通过体型对比,凸显人类的渺小与机器的压迫感。
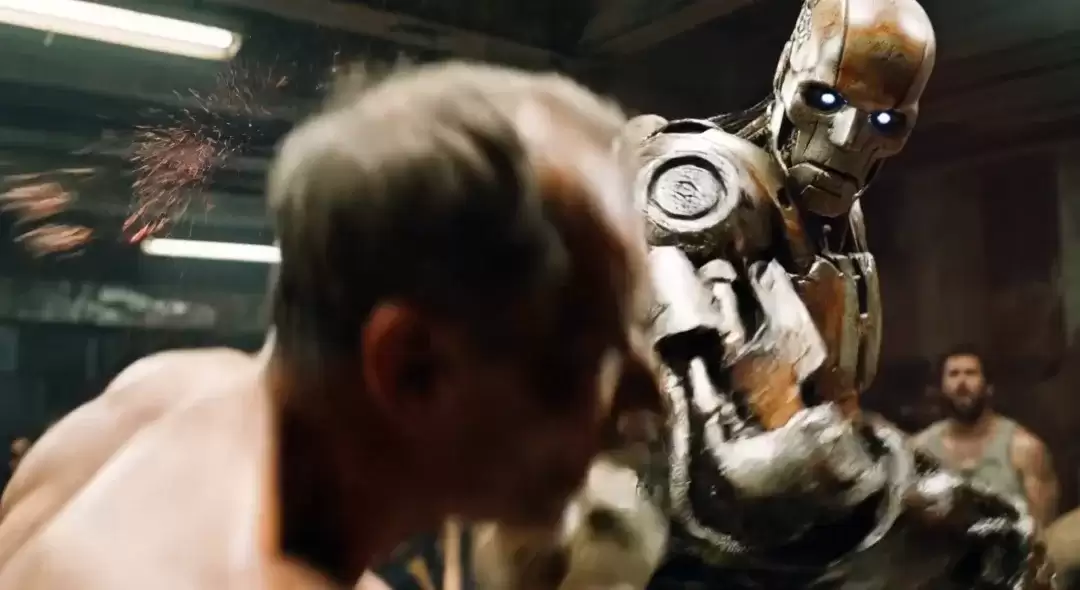
随后的镜头进一步强化了这种力量悬殊的印象。

然而,一个特写镜头瞬间扭转了情绪——男人挣扎着站起,其精神上的坚韧足以与钢铁之躯抗衡。

这些镜头组合在一起,形成了完整的叙事弧光和情感张力。对于不希望撰写复杂提示词的用户而言,这种智能分镜功能极大地提升了AI视频创作的效率。
而**自定义分镜**则提供了更精细的控制权。
当用户脑海中已有清晰的画面逻辑时,可以逐镜指定景别、内容和音效。
以开头的音乐节视频为例,设想中的流程是:贝斯手特写 → 鼓手镜头 → 主唱画面 → 观众热烈反应 → 舞台全景与夜空烟花。只需将这些要素按顺序填入分镜表。
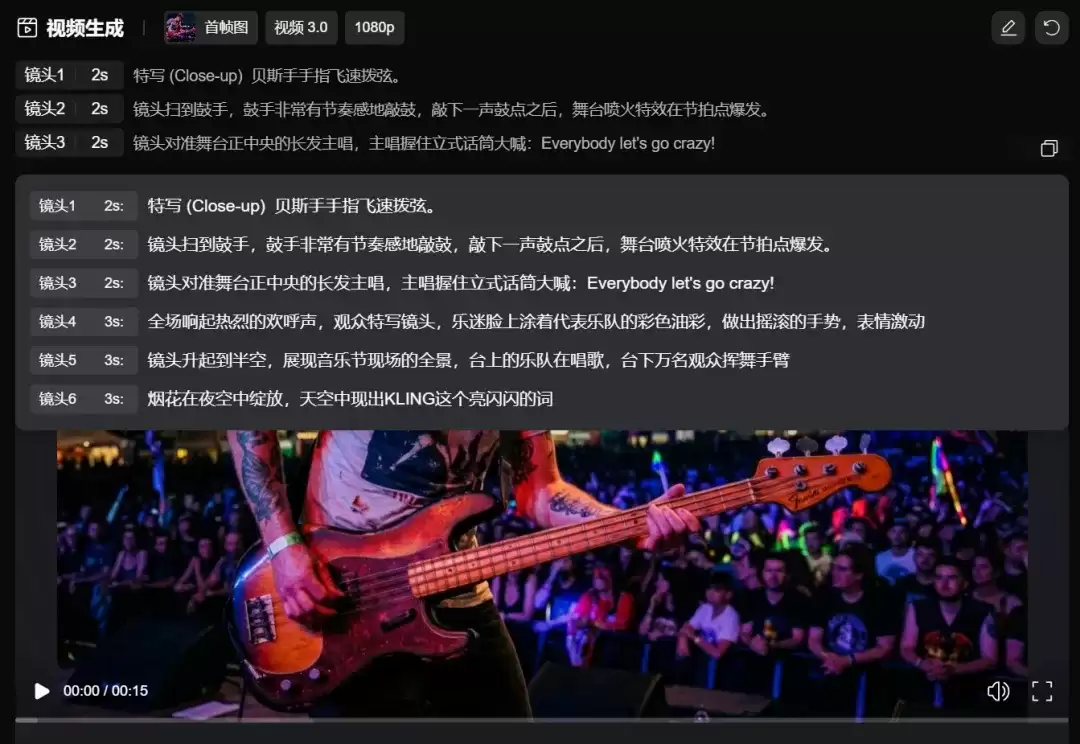
一个氛围感十足的视频便应运而生,指令遵循的精准度很高。
无论是智能还是自定义分镜,生成效果都相当出色。更重要的是,可灵3.0攻克了一个长期困扰AI视频模型的难题:**正反打镜头**。现在,对话场景的正反打切换可以做到无比丝滑。
当视频在手机上无法加载,可前往PC查看。对比提示词可以看到,六个镜头(双人全景→侦探特写→嫌疑人特写→侦探特写→嫌疑人特写→记忆闪回)被准确呈现,节奏流畅,甚至为“AI演员”留下了表演空间。

例如,嫌疑人在回忆时脸部肌肉的细微抽动,仿佛能让人感受到曾经的痛楚,这种细节赋予了视频真正的“影视感”。
正反打的应用也不限于对话。测试中的网球比赛场景,同样能实现流畅的视角切换。
当视频在手机上无法加载,可前往PC查看。这项能力极大地拓展了应用场景。例如,为产品制作广告Demo时,一个包含分镜和音效的动态视频预览,远比静态的故事板或分镜图来得直观。

此外,还探索出一种有趣的联动玩法:**用AI生成的故事板直接驱动视频生成**。首先,利用文生图工具创作一组连贯的画面作为故事板。

随后,将故事板图像与提示词一并提交给可灵3.0,它便能生成一段完整的视频。
测试生成的“后室”与“北欧风光”两条视频,在画面衔接和配乐方面都表现上佳。
当视频在手机上无法加载,可前往PC查看。三、语言能力:不止于多语种,更是情景化表达
可灵3.0的第二个重磅升级在于其语言能力。前文展示的多角色、多语言无缝切换已令人惊叹,而这催生了一种前所未有的趣味玩法:**制作“邪修式”单词记忆视频**。
这类视频的特点在于,观众被一段有趣的剧情吸引,知识却以意想不到的谐音方式“潜入”脑海。例如,一个看似在吐槽他人的场景,实际是为了引出单词“morbid”(病态的)。

利用可灵3.0,完全可以自主创作这类内容。这里生成了两个单词学习视频作为演示。
第一个单词是 **“Morose”**。场景设定在香港情人节,女孩因未收到玫瑰而生气,用粤语抱怨:“好cheap啊,约会都冇rose。”随后愤然离去,留下男孩独自“闷闷不乐”。

“冇rose”与“Morose”谐音,而男孩的状态正是单词的含义。于是,观众在剧情中记住了“Morose”读作“谋肉丝”,意为“闷闷不乐”。
当视频在手机上无法加载,可前往PC查看。第二个单词是 **“Ambition”**。场景是《权力的游戏》东北版,雪诺用浓厚的东北口音鼓舞士气:“夺回大东北,俺们必胜!”

部下们随之高呼“俺们必胜”。

“俺们必胜”正是“Ambition”(野心)的谐音。就这样,单词又被“诡异地”记住了。
当视频在手机上无法加载,可前往PC查看。由此可见,其语言能力远不止于“会说多种语言”,更在于能根据不同语境、故事,灵活调整语气、口音,实现与叙事意图的深度融合。
这项能力同样可以与分镜功能结合。例如,输入一段关于“餐厅服务生小老鼠用不同语言接待客人”的提示词。

模型便能生成一系列快速切换的镜头,精准呈现每个场景下的对应语言。
当视频在手机上无法加载,可前往PC查看。四、可灵3.0 Omni:视频编辑能力的进化
除了主打生成的可灵3.0,其专注于视频编辑的“Omni”模型也同步升级至**可灵3.0 Omni**。
Omni系列与数字系列的核心区别在于,它能够直接对现有视频进行编辑和修改。例如,将电影《王牌特工》中的一段打斗戏输入,要求替换主角。

生成结果如下,新角色的动作与场景融合度很高,除手中武器偶有闪烁外,完成度相当不错。
当视频在手机上无法加载,可前往PC查看。简单对比两个模型:**可灵3.0** 核心是“从无到有”生成视频;**3.0 Omni** 则擅长“从有到优”编辑视频。两者共享15秒生成、智能/自定义分镜等基础能力。
此外,两个模型都在“主体”设置中新增了**音色参考功能**,支持上传本地音频或选用历史视频中的角色声音,极大方便了角色一致性创作。
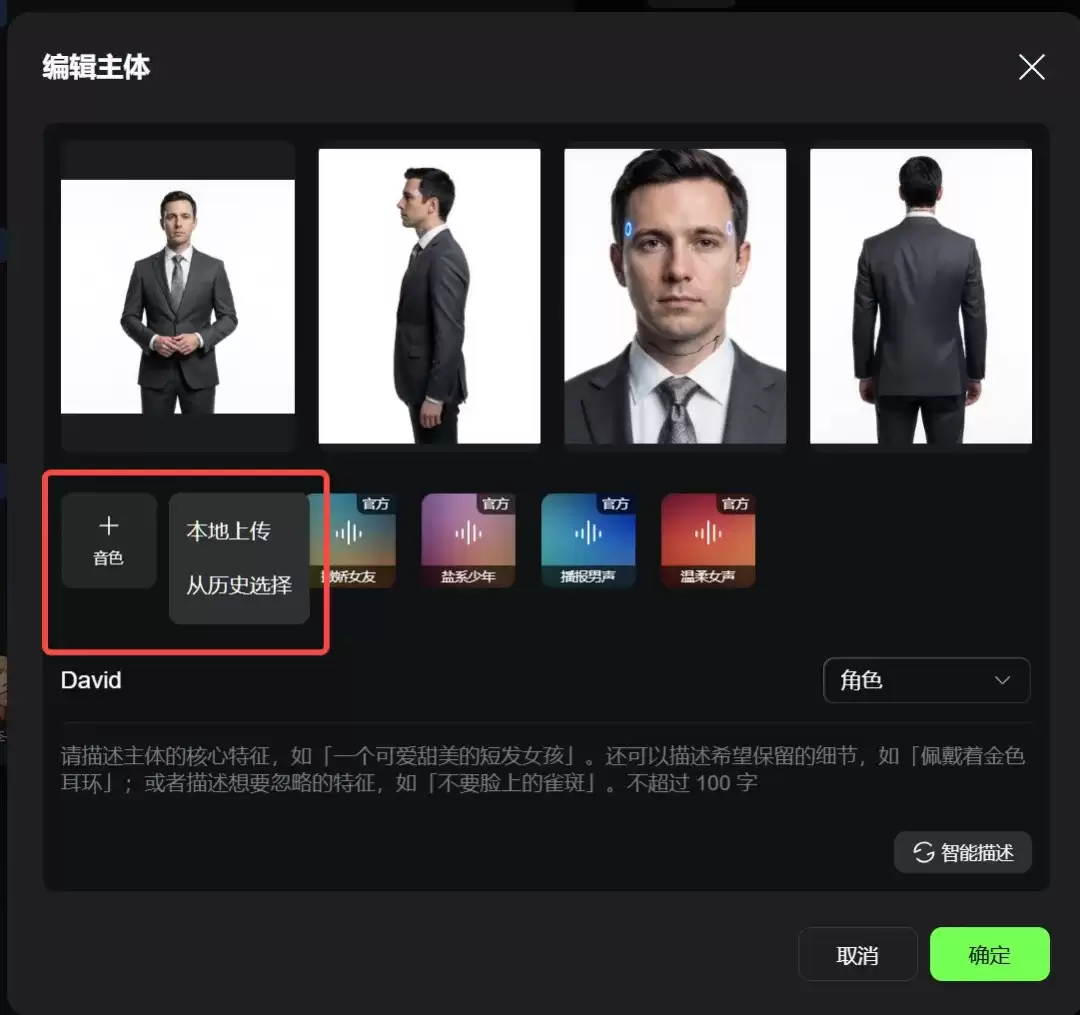
主要区别有两点:其一,Omni的参考视频时长需控制在3-10秒内,即视频改视频的操作仍有时长限制。其二,两者都支持从本地或历史视频中**提取主体**。

一个小提示:目前3.0 Omni的“视频参考”功能暂不支持使用提取出的主体。
总的来说,如果创作需求侧重于**基于参考生成新视频**,或需要进行**视频编辑、修改**,可优先选用3.0 Omni。若更倾向于**从文本或图片生成视频**,则3.0是更合适的选择。两者结合,足以覆盖绝大多数AI视频生成场景。
最后,通过结合3.0与3.0 Omni的能力,在四小时内快速制作了一个略带烧脑的剧情短片,以此综合展示此次升级的整体实力。
当视频在手机上无法加载,可前往PC查看。写在最后
可灵3.0是一次从底层到体验的全面革新。目前,该版本优先面向黑金会员开放(类似GPT新模型面向Plus用户),预计不久将实现全量推送。
一个清晰的趋势是,AI视频创作的门槛正在迅速降低,并日益向专业影视制作靠拢。它开始解决诸如分镜设计这类对普通人而言的难题;允许用户提取视频中的主体与声音,实现跨项目的角色复用;提供Omni这样的工具,对生成内容进行精准修改;甚至通过分镜功能,一站式完成剪辑与配乐。
这些进步汇聚在一起,预示着AI视频生产力的又一次巨大跃升。或许,一个属于每个人的“导演时代”正在加速到来。AI创作领域沉寂已久,而AI视频创作的下一个盛世,或许就此拉开了序幕。




