大模型API服务市场迎来新一轮价格调整,小米公司正式宣布其自研MiMo-V2.5系列大模型API接口实行永久性降价策略,部分版本最高降幅达到99%。此次价格调整显著降低了开发者集成先进AI能力的成本门槛。
对于广大开发者和企业用户而言,调用大模型能力的综合成本被进一步压缩。更值得关注的是,小米此次计价方案全面简化,不再依据上下文窗口长度进行区分,计费规则变得更加透明和易于预估。
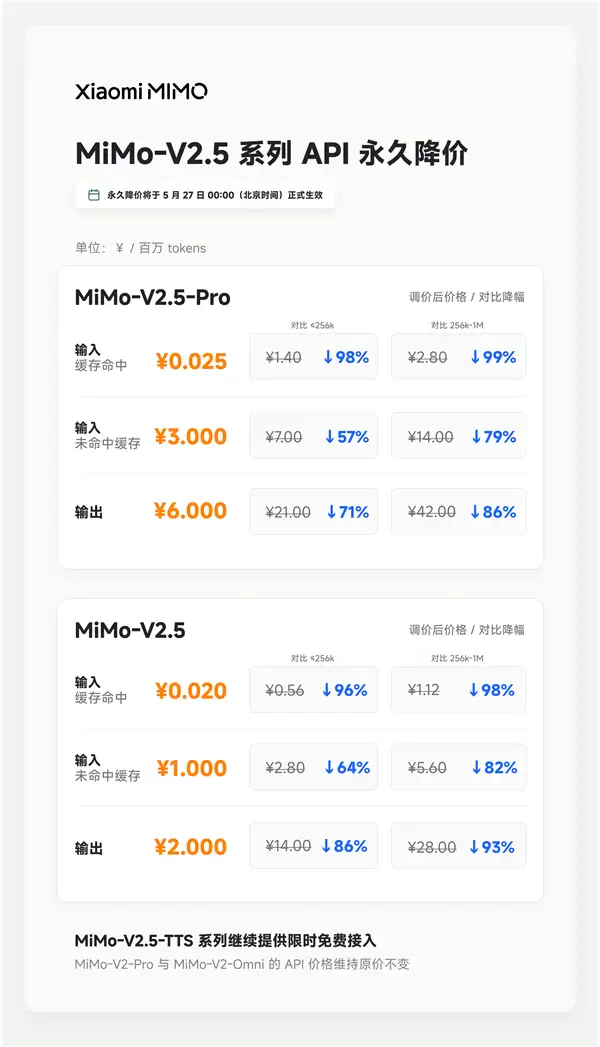
价格体系全面下调,最高降幅达99%
本次降价覆盖了MiMo-V2.5标准版和MiMo-V2.5 Pro专业版两个核心模型。价格调整幅度显著,堪称行业性价格重塑。
在输入成本方面,MiMo-V2.5 Pro版本的缓存命中价格调整为每百万tokens 0.025元,降幅高达99%;标准版MiMo-V2.5输入价格降至每百万tokens 0.02元,降幅为98%。输出成本也同步大幅下调:Pro版降至6元/百万tokens,降幅86%;标准版降至2元/百万tokens,降幅93%。
通过简单对比可知,若开发者原先调用Pro版API服务,现在完成同等规模任务的处理成本可能仅为原先的1%。这种量级的降幅预计将有效激发API调用量的增长,推动更多AI应用落地。
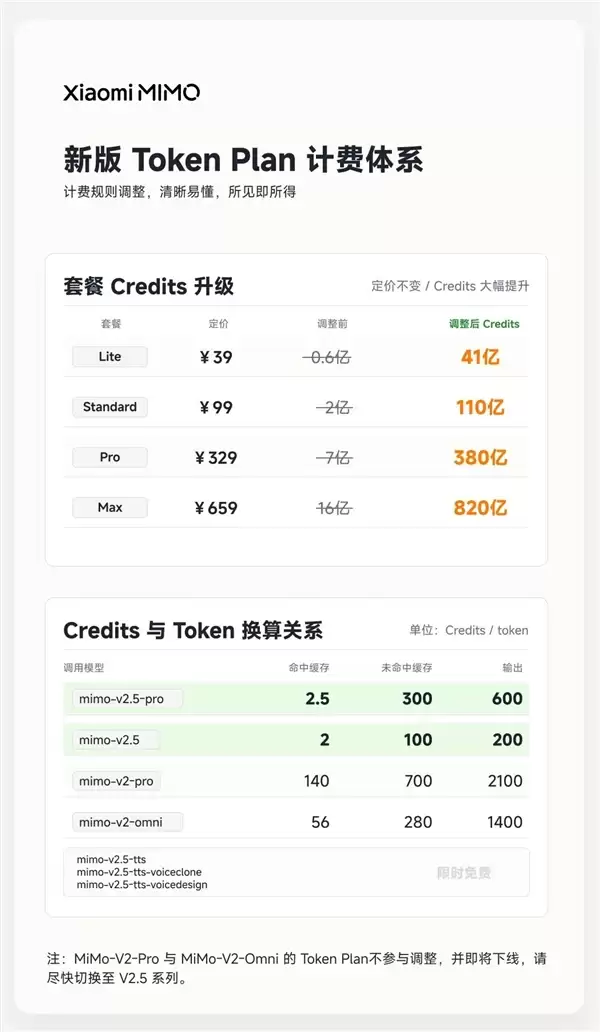
计费方案同步升级,更透明更灵活
除了直接降价,小米也对配套的Token Plan资源包体系进行了重要升级。新方案的核心优势在于“资源加量而价格不变”——用户获得的实际调用量提升至原先的5至8倍。
同时,平台引入了“Credits”积分计量概念,使得复杂的资源消耗换算过程变得更加清晰直观。这相当于将技术资源消耗透明化,让开发者能够更精准地理解、规划与管理自身的资源使用与成本支出,提升预算决策的科学性。
技术突破驱动成本优化,效率大幅提升
能够实现如此大幅度的服务降价,其根本动力源于持续的技术突破与系统优化。小米将成本下降归因于其推理系统的深度技术迭代。
据悉,技术团队基于SGLang HiCache框架完整支持了滑动窗口注意力机制,此项改进将KV Cache在GPU显存、CPU内存和SSD等多级存储间的数据调度量,降低至优化前的约七分之一。同时,可缓存的token数量提升至原先的近五倍。这两项关键指标优化直接提升了缓存命中率,从而显著提高了整体推理效率。
此外,通过优化专家并行方案与动态输入长度分桶策略,小米进一步提升了计算集群的输入吞吐性能。在确保服务响应质量与稳定性的基础上,单位token的综合服务成本得以持续降低。这正是支撑此次战略性价格调整的底层技术逻辑。

本次价格调整已于北京时间5月27日零时起在全球同步生效。可以预见,随着小米的深度参与,大模型API市场的竞争格局将更趋激烈。对于整个AI行业而言,由技术演进带来的成本红利正在加速转化为市场动能,最终将惠及广泛的开发者社区与AI应用生态的繁荣发展。




