
在具身智能领域,硬件性能的趋同化日益明显。那么,决定企业最终能走多远的核心竞争力是什么?答案已逐渐清晰:底层大模型的原创性、迭代深度与进化速度,正成为拉开差距的关键变量。
智平方自主研发的AlphaBrain,正是这条赛道上一个不容忽视的领跑者。从2023年成为中国首个坚持自研端到端VLA(视觉-语言-行为)路线的创业公司,到2026年发布全球首个类脑架构VLA具身大模型,短短四年间,AlphaBrain完成了四次里程碑式的技术跨越。每一次跨越,都不仅仅是参数的堆叠,更是对具身智能能力边界的一次重新定义与拓展。

接下来,我们将全景式拆解AlphaBrain的技术演进路线,深入剖析每一代模型背后的技术逻辑与突破性进展。
一、VLA的新定义——为什么它是“最强主航道”
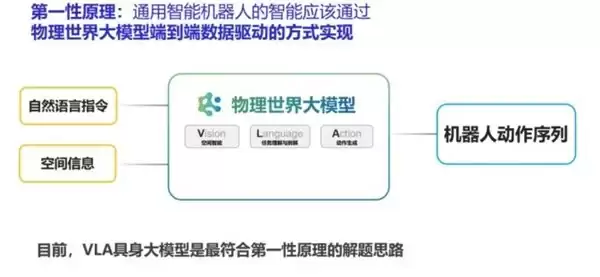
在深入技术细节之前,有必要先厘清一个关键概念的最新定义。这直接关系到如何理解整个行业的技术走向与未来。
智平方创始人郭彦东博士在2026年4月的Fairplus演讲中给出了一个明确的界定:VLA是多种模态(视觉、感知、语言、行为等)融合的大数据驱动的端到端模型架构的总称。在这个定义下,世界模型与VLA没有本质区别。
这意味着什么?意味着VLA并非一个固定不变的架构,而是一个持续吸纳前沿技术、不断迭代升级的开放范式。从世界模型的融入,到类脑智能的加持,VLA正在不断吸收行业内的前沿成果,持续突破自身的能力边界。
郭彦东博士对此有一个精辟的判断:“VLA远远没有结束,它是通往物理世界智能的最强主航道。回到第一性原理——对世界的感知(Vision)、逻辑的推理(Language)和行为的控制(Action)这三个核心要素永远存在,只是组织方式在不断进化。”
在2026年5月接受瞭望财经专访时,他进一步阐释了世界模型与VLA的关系:“世界模型和VLA一点都不冲突,本来就是一套技术路线的一个分支,或者一个技术路线的进步,它不是一个根本上的技术变革。”他指出,“世界模型做的更多是相对短程预测……如果想做更加长程的推理任务,就需要世界模型+VLA,或者把世界模型与VLA合并。”对于行业走向,他的判断是:“当前技术路线的收敛趋势已十分明显,行业正快速向世界模型+VLA的方向靠拢。”
二、AlphaBrain演进时间线
第一代:RoboMamba(2024年6月发布并开源)
定位:AlphaBrain的初期版本,创业公司中首个VLA模型。
核心突破:在模型规模仅为谷歌同类模型1/20的情况下,性能提升超过80%。这并非简单的优化,它意味着智平方从一开始就选择了一条与众不同的技术路径:并非盲目堆砌参数量,而是在架构层面寻求原创性突破。
学术认可:成功入选NeurIPS 2024,并获得了图灵奖得主Yann LeCun的公开关注与点赞。
行业意义:时间回到2023年初,全球范围内仅有特斯拉机器人与智平方选择了端到端VLA这条“少有人走的路”。智平方因此成为中国首个坚持自研端到端VLA路线的创业企业,其布局空间智能的时间点,领先李飞飞团队至少6个月。
第二代:FiS-VLA(2025年6月发布并开源)
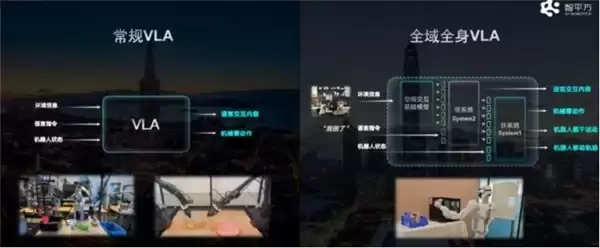
定位:AlphaBrain的快慢系统版本——业内首个“异构输入+异步频率”双系统VLA模型。
核心突破:开创性地提出了“双系统感知协同训练策略”。在仿真与真实任务中,其性能全面超越了当时的主流模型CogACT、Pi0等,其中超越Pi0的幅度达到30%。更以117.7 Hz的超高控制频率,重新定义了机器人“又快又聪明”的可能性。
技术创新:关键在于将Action模型从语言模型中分离出来。这正是“快慢学习”理念的核心体现。“慢系统”负责理解和规划(语言模型),而“快系统”则专司高频动作执行。这种分离设计让机器人得以在保持高层理解能力的同时,实现毫秒级的精确控制。
第三代:Video2Act(2025年11月率先推出)
定位:世界模型与VLA融合架构——增强型VLA的代表作。
核心突破:实现了“先预测、后执行”的闭环。不同于传统方法仅将视频扩散模型(VDM)用作数据生成器或外置规划器,Video2Act直接将VDM作为VLA的“世界模型引擎”。通过创新的显式时空表征提取技术(Sobel+FFT),模型在生成动作时,能结合对未来状态演变的隐式推演,从而做出更合理的决策。
性能数据:在第三方评测中,相较于硅谷同类标杆模型取得了超过30%的性能领先。在RoboTwin双臂任务中,平均成功率较π0等基线提升7.7%,在“Block Handover”等动态任务中,提升幅度更是高达18.7%。
学术影响:在由NTU、UC Berkeley、Stanford、Oxford联合完成的权威综述中,Video2Act作为“标志性架构”被Philip Torr、Pieter Abbeel等顶尖学者重点推荐。
前瞻布局:值得一提的是,智平方早在2023年下半年就率先明确提出——世界模型应是VLA模型的内在组成部分,而非外接模块。这一理念的提出,领先行业至少1年。
第四代:NeuroVLA(2026年4月首次发布)
定位:全球第一个类脑架构VLA具身大模型。
核心突破:借鉴人脑“大脑-小脑-躯干”的分工协同机制,首次将小脑功能深度融入操作环节。这直接改变了具身智能领域长期以来“小脑仅用于移动”的默认设定。
三层计算架构:
- 上层“大脑”层:负责理解视觉和语言指令,生成抽象任务目标,运行于GPU。
- 中层“小脑”层:每秒数百次读取传感器数据,实时平滑指令、消除抖动,采用自适应滤波技术。
- 底层“脊髓”层:由脉冲神经网络驱动电机,实现超低功耗运行,依托神经形态芯片。
实测性能:
- 有效抑制机械臂75%以上的动作抖动。
- 从碰撞检测到保护性撤回仅需20毫秒(传统VLA系统通常大于200毫秒,差距达10倍)。
- 碰撞后任务恢复成功率达54.8%(传统模型在此场景下成功率通常为0)。
- “脊髓”层执行时平均功耗仅0.4瓦。
- 涌现出“时间记忆”能力,机器人能记住并重复节奏性动作。
三、VLA三阶段演进论
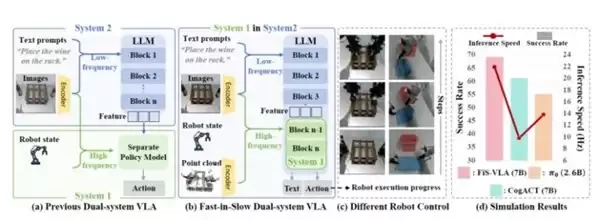
郭彦东博士在2026年4月的Fairplus演讲中,首次系统提出了VLA的三阶段发展路径:
- 第一代:端到端VLA。 核心是感知、理解与行动的统一建模。AlphaBrain的代表是RoboMamba和FiS-VLA。
- 第二代:增强型VLA。 核心进化在于融合世界模型,实现“行动前预测”。AlphaBrain的代表是Video2Act。
- 第三代:类脑VLA。 核心在于借鉴大脑/小脑/躯干的分工协同机制。AlphaBrain的代表是NeuroVLA。
值得注意的是,智平方是目前全球唯一完成了这三代VLA全部迭代的企业。
四、AlphaBrain Platform:从模型开源到生态开源
2026年4月,智平方发布了AlphaBrain Platform——全球首个一站式、开箱即用的具身智能模型开源社区。
这与PI(Physical Intelligence)的开源模式存在核心差异:PI开源的是一个模型,而AlphaBrain Platform开源的是一个生态。它不仅提供模型,还配套了评测平台(支持8大基准一键对比)、RL TOKEN训练框架(单张4090显卡即可运行)、全球首个可插拔世界模型架构(原生支持NVIDIA Cosmos Policy)以及开源持续学习算法(LoRA微调资源占用降低60%)。全系列模型均以MIT license开放。
谈及开源的动力,郭彦东博士在专访中坦言:“从根本上解决机器人大脑的问题,需要让更多企业参与到这个赛道中来。虽然我们投入了很多研发资源,但这不是一个企业能完全搞定的。”他透露,决定开源有两大触动:一是DeepSeek的开源让行业看到了开源模型的力量;二是十年前特斯拉开源电动汽车专利,成功带动了全球产业的蓬勃发展。
五、技术壁垒:为什么难以追赶
智平方构建的护城河,主要体现在以下几个层面:
壁垒一:原创架构积累。 从RoboMamba到NeuroVLA,每一代都是原创架构,而非套用开源方案。四年四代迭代所积累的架构经验和工程know-how,难以通过简单的复制来追赶。
壁垒二:千卡级算力体系。 公司自成立起便部署了千卡级算力集群,并构建了自有的训练加速体系。更高的数据利用率,直接转化为更快的模型进化速度。
壁垒三:攻克灾难性遗忘。 团队攻克了“灾难性遗忘”这一世界级难题。通过大规模增量学习方法,AlphaBot在学习新指令时不会丢失原有知识,成功实现了从“专用工具”到“通用智能体”的质变。
壁垒四:数据飞轮已启动。 在大型双臂机器人数据集RoboCOIN中,智平方的贡献占比超过35%,覆盖50余个场景。真实场景的持续数据回流让模型“越用越聪明”。目前,公司的产品已在汽车、半导体、生物制造、公共服务、新零售等领域实现落地应用,订单体量与场景覆盖均处于行业前列,率先跑通了“数据×商业”的双闭环。
六、学术成果
仅2025年一年,团队就有数十篇论文被顶级会议收录,其中仅NeurIPS就达到6篇。摩根士丹利在其机器人产业深度报告中,将智平方列为具身基础模型的代表企业。此外,公司罕见地拥有5位斯坦福全球前2%科学家,是科学家密度最高的创业团队之一。
七、结语
回顾这条演进路线:从2023年成为中国首个端到端VLA创业企业,到2024年RoboMamba以1/20的模型规模实现超越谷歌80%的性能并入选NeurIPS,到2025年FiS-VLA超越Pi0达30%、Video2Act超越硅谷标杆30%,再到2026年发布全球首个类脑VLANeuroVLA(实现20ms碰撞保护、75%抖动抑制、0.4W超低功耗)——AlphaBrain的四年历程,恰恰完整映射了VLA从端到端,到增强型,再到类脑的三阶段进化史。
正如郭彦东博士所言:“2026年对具身智能来说是一个了不起的拐点,是行业从1到10的关键年。”而AlphaBrain,正是驱动这场从1到10跨越的核心引擎。
预测未来最好的方式,就是亲手创造未来。世界的下一场变革在于具身智能,而具身智能的下一场变革,正在这里发生。
数据来源:
- 智平方官方数据及AlphaBrain技术文档
- NeurIPS等顶级学术会议收录信息
- 摩根士丹利机器人产业报告
- 瞭望财经专访《对话郭彦东:下一代机器人大脑是类脑VLA》
本文基于智平方官方公示信息撰写,仅供行业参考。




