5月6日,新民晚报的一则报道引发广泛关注。有网友发帖称,在使用字节跳动旗下AI产品“豆包”搜索历史人物“黎元洪”时,结果竟显示为演员范伟的PS合成图片。这一发现让许多用户感到困惑:一位重要的近代历史人物,难道需要借用演员的图片来替代吗?不少用户因此对“豆包”的智能程度产生了疑问。
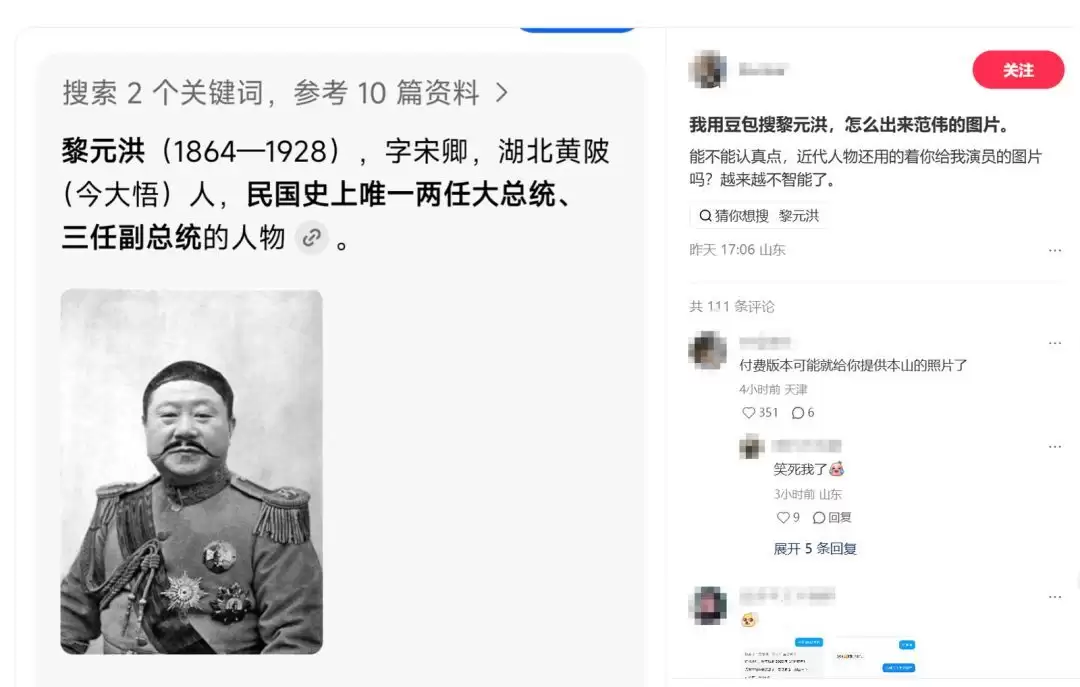
实际情况究竟如何?记者在5月5日进行了多次测试验证,发现了一个值得关注的现象:不同账号使用豆包搜索“黎元洪照片”后,得到的结果并不一致。部分账号确实只返回了那张广为流传的范伟PS图;有些账号则同时提供了PS图和黎元洪本人的真实历史照片;还有少数账号能够直接检索到正确的本人肖像。
为何会出现这种“搜索结果因人而异”的混乱情况?记者直接向豆包AI进行了询问。豆包的解释,揭示了一个源自网络文化的陈年“梗”的来龙去脉。
原来,这背后存在一个流传甚广的“历史误会”。真实历史中的黎元洪,其相貌与演员范伟确有几分神似。而这一误会的源头,可以追溯到电影《建党伟业》选角时期流出的一张PS图片。这张将范伟头像合成到黎元洪历史服装上的图片,因其戏剧性和趣味性,在互联网上被大量转载和传播。

问题的关键就在于此。这张PS图片的网络传播热度,在某个阶段甚至超过了黎元洪真实历史照片的可见度。许多不了解背景的网友,直接将其当作“黎元洪照片”使用和分享。更为复杂的是,部分网络图库、百科类网站在内容收录时未能严格审核,混杂收录了这张图片,导致其在搜索引擎的图片索引中占据了过高的比例。
AI大语言模型在训练和学习过程中,会广泛抓取和分析公开的网络数据。当一张错误图片的关联文本数据和出现频率达到一定阈值时,模型就可能将其识别为“相关答案”推送给用户。这并非AI有意犯错,而更像是它“客观”反映了当前互联网信息环境中存在的噪声与误差。
这一事件在网友中引发了诸多调侃与深入讨论。有人戏称:“这样下去,以后搜索华佗会不会出现李保田饰演的喜来乐剧照?”也有人顺势玩梗:“看来范伟老师成了历史人物的通用脸模了。”当然,也有用户表达了切实的担忧。有网友分享亲身经历:“豆包提供的信息确实存在不少错误,被误导几次后,现在使用变得非常谨慎。”这条评论下,跟随着一条颇具代表性的建议:“对于AI生成的内容,尤其是涉及历史事实、人物生平等关键信息,使用者务必保持审慎,进行多方核实,不宜过度依赖。”
这个看似滑稽的搜索乌龙事件,实际上指向了一个更深层的议题:我们应如何理性看待和正确使用AI工具?AI更像是一面镜子,映照出我们所处的信息生态。当网络本身充斥着谬误与混杂信息时,要求AI输出百分之百精准无误的答案,本身或许就面临巨大挑战。对于每一位使用者而言,保持批判性思维,对关键信息进行交叉验证和权威溯源,是在任何信息时代都不可或缺的素养与智慧。




