5月7日,AI算力基础设施领域迎来一项重大突破。OpenAI通过开放计算项目(OCP)正式发布了MRC(多路径可靠连接)协议,旨在解决大规模AI模型训练中一个长期存在的核心痛点:GPU集群的网络通信瓶颈。
这项协议由OpenAI联合AMD、NVIDIA、Intel、微软和博通等科技巨头,历时两年共同研发完成。目前,该协议已在搭载NVIDIA GB200芯片的超大规模计算集群中得到实际部署与应用,标志着其从技术标准正式迈入了工程实践阶段。

核心挑战:网络延迟如何制约万卡集群效率?
MRC协议致力于解决的,是一个随着算力规模扩大而日益严峻的问题。在训练参数量达万亿级别的大语言模型时,往往需要调动数万块GPU进行协同计算。在此过程中,任何微小的网络数据传输延迟或拥塞,都可能导致整个训练任务暂停——大量GPU被迫闲置,等待滞后的数据同步。集群规模越大,由网络波动、链路故障引发的此类问题就越频繁,造成的算力资源浪费与运营成本激增也越显著。
解决方案:基于多路径并行的网络架构革新
那么,MRC协议的核心思路是什么?答案是:化整为零,实现多路径并行传输。
与传统依赖单一高带宽链路(例如800Gb/s)的方案不同,MRC创新性地将一条“高速主干道”拆分为多条并行的“网络支线”。具体而言,它可以将一个800Gb/s的网络物理接口,逻辑上拆分为8条独立的100Gb/s链路,并连接至8台不同的网络交换机,从而构建一个并行的网络矩阵。数据流得以通过多条路径同时传输,而非依赖单一链路,极大提升了容错能力和有效带宽。
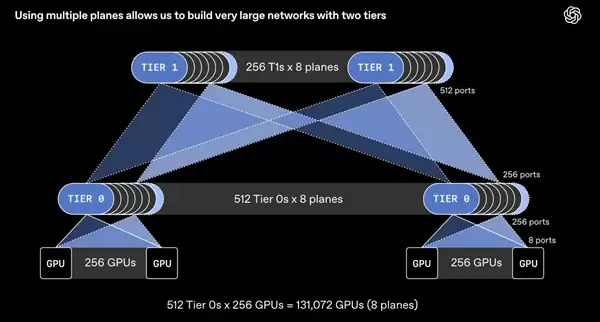
拓扑演进:从多层网络到高效两层互联
这一变革,对AI超算集群的网络拓扑设计产生了深远影响。举例来说,一台支持64个800 Gb/s端口的交换机,在MRC的拆分机制下,实际可连接多达512个100 Gb/s的端口。这种端口连接密度的数量级提升,使得仅需两层交换机网络,就能实现超过13万块GPU的全连接组网。
相比之下,采用传统800 Gb/s直连方案要达到同等规模,通常需要三到四层复杂的交换网络。减少的这一到两层网络层级,直接意味着数据传输跳数更少、延迟更低,同时整个系统架构中的潜在故障点也大幅减少,显著提升了集群的可靠性与整体效率。
技术基础与实际部署
在技术实现层面,MRC协议基于现有成熟的RDMA over RoCE(基于融合以太网的远程直接内存访问)协议进行扩展,继续支持GPU和CPU的硬件级远程内存直接访问,确保了高性能计算的底层能力。
目前,OpenAI已在Oracle Cloud Infrastructure(OCI)和微软的Fairwater超算平台上的GB200集群中成功部署了MRC网络,并将其用于训练最前沿的AI大模型。这充分证明了该协议已具备企业级生产环境的稳定性和可靠性。

未来展望:“星门”计划的基石与行业开源协作
MRC协议的意义不仅在于解决当前问题,更着眼于未来。它已被确定为OpenAI正在秘密推进的“星门”(Stargate)超级计算机项目的核心网络基础架构。这个雄心勃勃的项目计划在2029年前部署高达10GW的专用AI算力。据悉,仅在过去三个月内,其相关算力部署已超过3GW,进展速度惊人。
尤为重要的是,OpenAI此次选择通过OCP开源社区发布MRC协议规范,展现了其推动行业协同发展的开放态度。AI算力基础设施,特别是高速网络层的构建,所面临的挑战极其复杂,单靠任何一家公司都难以完美攻克。OpenAI表示,希望借此契机促进跨行业的深度合作,共同突破制约人工智能发展的核心基础设施瓶颈。





