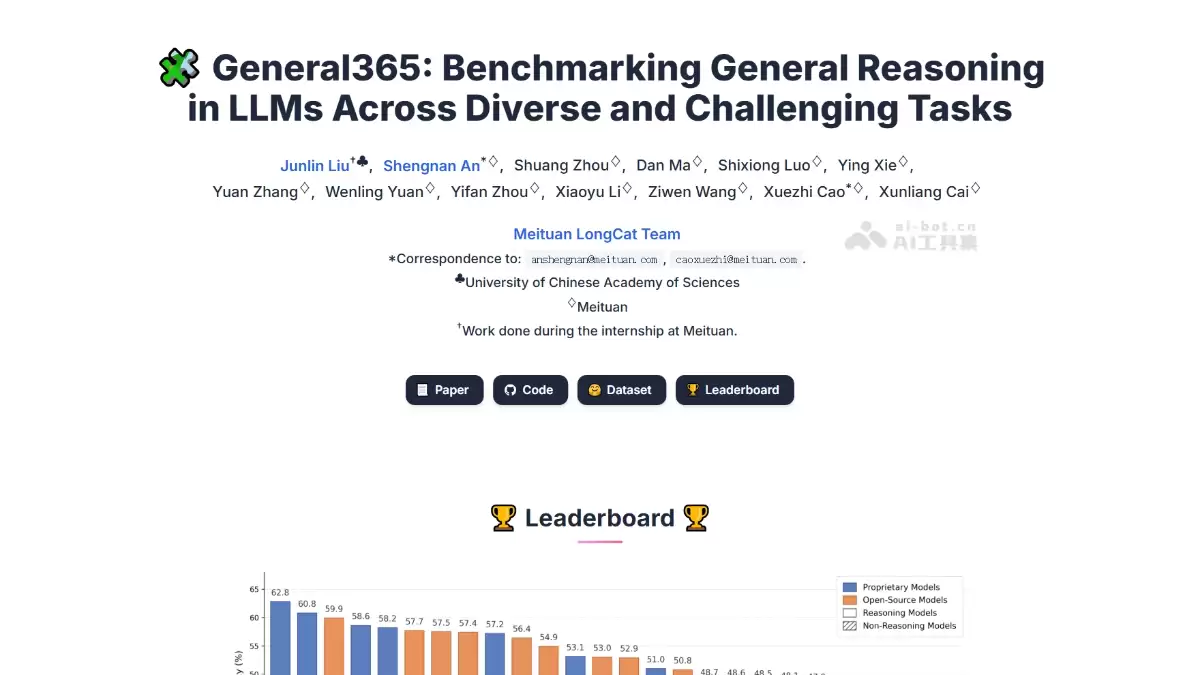
近期,大模型评测领域迎来一项重要进展。美团LongCat团队正式开源了名为General365的基准测试集,专门用于系统评估大模型的通用推理能力。测试结果颇具启发性:在覆盖八大推理维度的365道原创题及其衍生变体面前,参与评测的26款主流大模型中,仅有Gemini 3 Pro的准确率勉强达到62.8%,绝大多数模型甚至未能突破60%的及格线。这引发了一个关键思考:那些在学科知识竞赛中表现亮眼的模型,其底层通用逻辑思维能力是否真的扎实?
General365的核心功能与设计
该基准之所以能产生如此具有区分度的评测结果,得益于其以下几个关键设计理念:
- 高度多样化的评测体系:基准包含了365道人工精心设计的种子题目,并进一步衍生出1095个高质量变体。这些题目全面覆盖了复杂约束推理、分支枚举、时空推理、递归回溯、语义干扰、隐式信息处理、最优策略制定以及概率不确定性这八大核心挑战维度,确保了评估的全面性与深度。
- 推理能力与知识储备解耦:为了纯粹地衡量模型的逻辑推理能力,General365将题目所需的背景知识严格限定在K-12(中小学)水平。这意味着模型无法依赖庞大的专业领域知识库“取巧”,必须真正展示其内在的推理链条与逻辑思维过程。
- 混合式精准评分系统:评分机制并非单一标准。对于数值类题目,采用math-verify工具进行解析验证;对于选择题和文本类题目,则引入GPT-4.1进行模型评分。这套混合评分系统的准确率经人工抽样验证高达99.6%,确保了结果的可靠性。
- 公开子集与隐藏测试集策略:为有效防止数据污染导致模型“刷题”或过拟合,基准采用了创新的半公开策略。目前已公开180道种子题及其变体(总计720题),其余题目则作为隐藏测试集保留,用于进行更真实、更具泛化性的能力评估。
- 广泛的多模型横向对比:基准支持对包括OpenAI、Gemini、Anthropic、DeepSeek、Qwen、GLM、Kimi以及LongCat自身在内的超过26款主流大模型进行标准化横向评测,结果清晰直观,便于比较。
General365的技术实现原理
那么,这套基准是如何保证其科学性和有效性的呢?其背后的技术细节至关重要:
- 八大维度解构通用推理:研发团队首先将抽象的“通用推理”能力具体拆解为上述八个核心挑战类型。每道题目都至少明确对应其中一个维度,并且有近70%的题目同时具备两个以上的复合类别标签,确保了题目的综合性与挑战性。
- 有效避免模板化与机械记忆:这是许多现有评测基准的常见痛点。General365通过t-SNE语义分布验证和基于Gemini 3 Pro的推理路径相似度评分,确保题目之间在逻辑结构和语义上具有足够的独立性,有效防止模型通过记忆“解题模板”或固定模式来获取高分。
- 严格的难度过滤与人工审核流程:题目生成过程严谨。所有题目都经历了严格的难度分级过滤、多样性扩充、利用大模型进行题目扩展,以及最终的多轮人工审核与把关,最终构建了包含1460道题目的高质量题库。
- 高效可靠的混合评分框架:如前所述,针对不同题型(数值、选择、文本)采用规则验证与先进大模型评分相结合的框架,在保证大规模评测效率的同时,极大提升了评分结果的准确性与权威性。
General365的独特优势与价值
与当前众多大模型评测基准相比,General365的独特价值主要体现在以下几个方面:
- 聚焦于真实世界推理能力:它不同于AIME、IMO等侧重于特定学科深度知识的竞赛题。General365专注于日常与通用场景下的逻辑思维,直指当前部分大模型可能存在的“高分低能”现象——即擅长解答知识密集型问题,却在基础而复杂的逻辑推理上表现不佳。
- 具备出色的区分度:当大多数最先进的SOTA模型得分仅在60%左右徘徊时,该基准的区分能力便凸显出来。它有效避免了像BBH等基准出现的性能“天花板”或饱和问题,能够持续、清晰地分辨出不同模型在推理能力上的细微差距。
- 经得起检验的题目多样性:通过语义分布分析可见,General365的题目在向量空间中分布均匀且分散,其逻辑独立性显著高于BBH和BBEH等基准,这意味着它更难被模型通过简单的“套路”或模式匹配所破解。
- 开源、可复现、可扩展:项目在GitHub上提供了完整的评测代码、数据集及使用文档,研究社区与开发者可以快速接入、复现评测结果并进行延伸研究,有力推动了评测过程的透明化、标准化与协作创新。
General365项目资源获取
对于希望深入了解、使用或参与贡献的开发者和研究人员,可以通过以下官方渠道获取相关资源:
- 项目官方网站:https://general365.github.io/
- GitHub开源仓库:https://github.com/meituan-longcat/General365
- HuggingFace数据集:https://huggingface.co/datasets/meituan-longcat/General365_Public
- arXiv技术论文:https://arxiv.org/pdf/2604.11778
General365与同类竞品基准对比
为了更清晰地定位General365,我们将其与业界常用的两个硬核推理基准进行简要对比分析:
| 对比维度 | General365 | BBH (Big-Bench Hard) | BBEH (Big-Bench Extra Hard) |
|---|---|---|---|
| 核心评测重点 | 通用逻辑推理(基于K-12知识) | 综合性任务推理 | 高难度综合性任务 |
| 题目规模与形式 | 365 道种子题 + 1095 道变体 | 23 项不同任务 | 多项任务的扩展集合 |
| 题目多样性 | 极高(语义分布均匀,逻辑独立性强) | 相对较低(存在题目语义聚集现象) | 较低(存在一定模板化倾向) |
| 难度与区分度 | 高(当前SOTA模型仅62.8%) | 较低(部分任务性能已趋饱和) | 中等 |
| 评分方式 | 混合评分(规则+大模型,准确率99.6%) | 主要以规则评分为主 | 主要以规则评分为主 |
| 数据公开策略 | 半公开(180题公开 + 隐藏测试集) | 全部公开 | 全部公开 |
General365的主要应用场景
这样一个具备高难度和高区分度的基准测试,具体能在哪些实际场景中发挥关键作用?
- 大模型研发与能力诊断:对于模型研发团队而言,它是一个高效的“诊断工具”。能够精准识别模型在复杂约束理解、语义干扰排除、最优策略规划等特定推理维度的能力短板,从而为模型的迭代优化提供明确方向。
- 企业模型选型与评估:对于有AI应用需求的企业用户,在选择商用或开源大模型时,General365的评测结果提供了超越简单问答或知识检索的、更深层次的逻辑推理能力数据支撑,有助于做出更科学、更明智的技术选型决策。
- 推动学术研究:它为“通用推理”这一前沿研究方向提供了标准化的评测工具和高质量数据集,有助于推动大模型从“记忆型专家”向具备更强思维能力的“通用推理者”演进。
- 推理效率与成本分析:该基准还支持分析模型达成正确推理所需的输出token数量与准确率之间的关系,从而评估模型的推理效率,为优化模型部署与推理成本提供有价值的洞察。




