最近,AI圈里出了件挺有意思的事儿。不少网友发现,MiniMax的大模型,好像就是认不准“马嘉祺”这三个字。
一开始,大家还以为只是偶然的“小bug”,但经过多轮实测,情况变得有点耐人寻味了。无论是切换不同的接口,还是更换使用平台,这个问题都能稳定地复现出来。
翻看网友们的测试截图,再结合实际的调用结果来看,模型其实“知道”马嘉祺这个人。它能检索到相关的背景资料,也能完整、准确地输出他的个人履历和经历。可偏偏一到要说出他名字的时候,模型就开始“犯迷糊”,要么文字错乱,要么随意改写。
简单概括就是:人物背景信息都对,人物也能对上号,唯独在识别和输出姓名这个环节上,频频掉链子。
这背后到底是什么原因呢?
今天,MiniMax官方微博发布长文,正式回应了M2系列模型无法正常说出“马嘉祺”的问题,并详细分享了完整的排查过程和技术层面的思考。
根据官方的说明,他们从多个技术维度进行了深入排查。这包括检查分词器版本是否对齐、分析embedding的统计分布、进行语义近邻检索,还对比了预训练模型与后训练模型在少量样本(few-shot)下的表现差异。此外,团队也统计了后训练数据中词汇的出现频次,并对整个词表中语言模型头部(lm_head)参数的变化幅度进行了排序扫描。
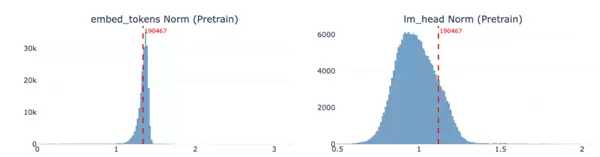
最终,问题根源被定位了:在分词器中,“嘉祺”被合并成了一个独立的token(词元)。然而,这个特定的token在后训练数据中间出现的频率极低。正是这种极低的曝光度,导致模型在后训练过程中,逐渐“遗忘”了该如何生成这个token。
那么,如何修复呢?MiniMax给出的方案是,构造一份覆盖整个词表的合成数据。其核心思路很巧妙:通过一个简单的“复读”任务,为词表中的每一个token都建立一个生成频率的“底线保障”。这样一来,就能防止任何一个token因为长期“缺席”而出现能力退化。
此外,MiniMax也表示,未来会将“token覆盖度”作为后训练数据质量的一项常规监控指标。这种做法有助于在早期就发现那些潜在的、因token稀疏而引发的退化风险,从而避免类似问题再次在线上环境中间出现。





