小米技术团队近日发布了一项重要成果,正式推出名为Xiaomi OneVL的一站式潜空间语言视觉推理框架。尤为关键的是,团队同步开源了完整的模型权重及全套训练与推理代码,向全球开发者与研究机构开放使用。这标志着小米在人工智能领域实现了又一关键技术突破,也延续了今年3月其XLA认知大模型架构所展现出的前沿技术布局。
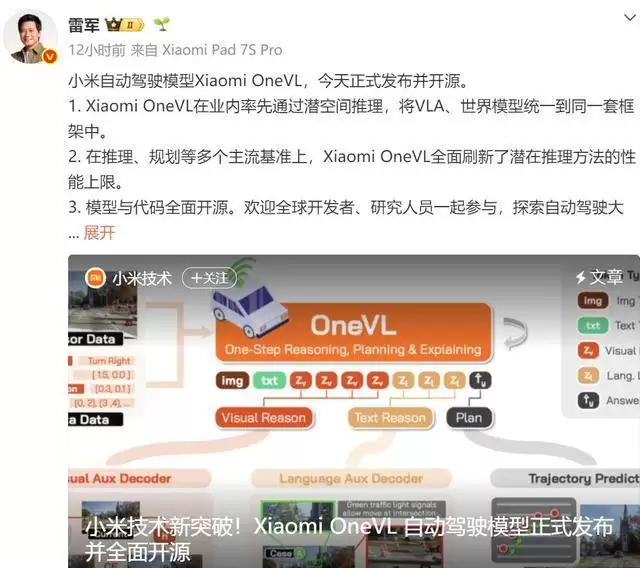
Xiaomi OneVL的创新点究竟在哪里?根据技术团队披露,其核心突破在于首次通过“潜空间推理”技术,将视觉语言动作理解、世界模型构建与潜空间推理这三条原本独立的技术路径,深度融合进一个统一的框架之中。这一设计思路精准应对了传统多模态模型在处理复杂、异构数据时面临的效率与一致性挑战,使得系统在面对真实世界复杂场景时,能够实现更高效、更连贯的推理决策与任务规划。从已公布的评测结果看,该框架在多项权威基准测试中均取得了当前最优性能,尤其在潜空间推理的关键指标上,提升幅度显著。
消息发布后,小米董事长雷军通过社交媒体进一步阐释了开源的战略考量。他强调,此举旨在促进自动驾驶领域的技术协作与共同进步。雷军指出,通过开放核心代码与模型参数,期望汇聚全球研发智慧,共同探索大模型在自动驾驶各类具体场景中的创新应用路径。目前,相关代码库已在主流开源平台正式发布,配套的技术文档体系完善,从模型架构设计到具体训练方法均有清晰阐述。
从行业发展趋势观察,Xiaomi OneVL的推出,表明小米在AI基础研究与底层框架构建方面已步入深入阶段。其融合多技术路线的统一框架设计,为破解自动驾驶系统中复杂的长尾难题提供了新的思路与工具。随着代码的全面开源,预计将在行业内引发新一轮的技术研讨与创新实践,进而推动智能驾驶系统整体技术栈的快速迭代与性能升级。




