你的语音助手又抢话了。
用户刚说“我想订那个……就是上次去过的那家……”,话还没说完,AI已经兴冲冲地回了一句“好的,请问您想订什么?”
“帮我查一下那个……”——话音未落,AI拿着半句话就开始生成回复了。
更让人哭笑不得的是:用户咳嗽一声,AI开始正经回答一个不存在的问题;用户清了清嗓子,AI说“好的,我来帮您处理”;旁边有人关门,AI又开口了。
这些问题的根源,往往不是背后的大语言模型不够聪明,而是系统根本不知道什么时候该接话——更准确地说,它分不清哪些声音是“有效语音”,哪些是“无效噪声”。
现有语音判停方案为什么不行
目前主流的语音助手,其判停逻辑大多基于VAD(语音活动检测)加一个固定的静音阈值——检测到N毫秒没声音,就认为用户说完了。但这个方案存在两个致命缺陷。
首先,它无法区分“思考中的停顿”和“真正的说完”。人在组织语言时会犹豫、会思考,1秒钟的沉默绝不代表一句话的结束。
其次,它分不清“人声”和“噪声”。VAD检测的是“有没有声音活动”,而不是“有没有语言意图”。咳嗽、叹气、清嗓子,甚至环境中的碰撞声,都可能被VAD标记为语音活动。这些声音经过语音识别(ASR)后,极易产生幻觉文本,从而触发大模型生成一个莫名其妙的回复。在真实部署环境中,特别是在车载、开放办公、户外等场景下,这类由噪声误触发的问题,其频率远超想象。
行业已经开始转向模型判停——用深度学习模型来判断用户是否说完。但现有的模型方案普遍面临一个三角困境:精度、成本和速度,三者难以兼得。
例如,7B参数量的方案精度不错、延迟也低,但需要GPU,部署成本高昂。850M参数的方案精度好,但推理延迟接近200ms,同样依赖GPU。而8M参数的轻量方案虽然能在CPU上运行,但F1分数只有70%出头,难以满足生产环境的要求。
更重要的是,这些方案几乎都只解决“说完vs没说完”的二分类问题,对于非语义声音(如咳嗽、叹气、噪声)没有专门的处理能力。它们要么将其误判为“说完了”从而触发回复,要么只能依赖前置的ASR转写结果进行间接判断,导致链路冗长且不可控。
可以说,如果你想要一个不依赖GPU、精度达标、同时能有效拦截噪声的语音判停方案,市场上几乎没有选择。

TurnSense:不用GPU也能打,噪声一条不漏
最近,百融Baiji Team开源了TurnSense——一个47M参数的语音判停模型。它直接以语音为输入,在纯CPU环境下跑出了与7B GPU方案持平甚至略超的精度。
这个模型核心回答一个问题:用户这段语音,是说完了、没说完,还是根本无需回复?
三种输出,对应三种截然不同的系统行为:
● Complete(说完) → 立即响应。用户表达了完整的意图。
● Incomplete(未说完) → 继续等待。用户还在组织语言,只是暂时停顿。
● Invalid(无效) → 静默忽略。咳嗽、叹气、清嗓子、打哈欠、环境碰撞声……一切不构成对话意图的声音,系统直接当它不存在。
这个三分类设计绝非锦上添花,而是解决了一个工程上的关键痛点。在传统方案中,非语义声音需要走完VAD → ASR → 文本判断的完整链路,才有可能被过滤(而且还不一定能过滤掉)。TurnSense则在语音层面就直接拦截,根本不给下游误触发的机会。整条链路的噪声抑制,从“末端补救”变成了“源头拦截”。
关于Invalid的边界,这里需要说明一下:如果用户只是发出一声“嗯”作为回应,TurnSense会怎么判?它的判断依据是这段语音是否携带需要AI响应的意图。纯粹的反馈性语气词(如单独的“嗯”、“啊”)会被归为Invalid,不会触发AI回复。但如果“嗯”后面紧跟着内容(例如“嗯,我想问一下……”),VAD会将其作为一整段语音送入,模型则会根据整段内容判断为Incomplete或Complete。
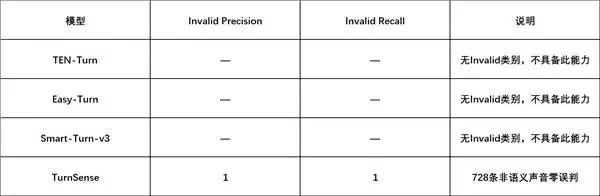
在包含728条非语义声音的测试集中,TurnSense在Invalid类别上做到了100%的精确率(Precision)——这意味着咳嗽声永远不会触发一次AI回复。一次都不会。

直接看数据
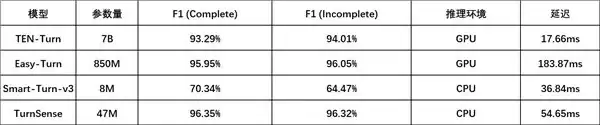
在300条真实中文对话数据(easyturn_real_test_ZH)上的语义判停能力对比如下:
在728条非语义声音测试(non_semantic_test)上的噪声拦截能力对比如下:
几个值得注意的点:
在语义判停方面,TurnSense的F1分数比Easy-Turn高了约0.3个百分点,比TEN-Turn高了约3个百分点。0.3个百分点的优势不算碾压,但关键在于,它是在CPU上跑出来的。Easy-Turn需要GPU,且延迟是TurnSense的3倍多。在达到同等精度的前提下,两者的部署成本差了一个数量级。
在噪声拦截方面,其他三个对比模型根本不具备这个能力——它们只做二分类(说完/没说完),遇到咳嗽声只能“硬猜”一个类别。TurnSense是目前唯一在模型层面具备非语义声音识别能力的判停方案。
TEN-Turn的延迟确实比TurnSense更低(17ms vs 54ms),但它需要一张GPU。如果你有充足的GPU预算且并发量不高,TEN-Turn是一个合理的选择。但如果你需要将模型部署在端侧、需要支撑高并发、或者不想为判停功能单独购买GPU——那么TurnSense是目前唯一精度达到生产标准的纯CPU方案。

为什么47M能打赢7B?
判停本身是一个极窄的任务——输入是一段几秒的语音,输出是三选一的分类。它不需要世界知识,不需要长链推理,也不需要理解复杂的上下文。用7B模型来做这件事,就像开卡车去送一封信,99%的运力都被浪费了。
但“用小模型做窄任务”并不是新思路,比如Smart-Turn也只有8M参数,为什么它的F1分数只有70%左右?差距到底在哪?
主要在于两个方面。
第一是训练数据。TurnSense使用了大规模中英文真实对话语音作为训练数据,覆盖了口语中大量的犹豫、停顿、重复、自我修正等现象。同时,训练集中包含了大量真实环境录制的非语义声音样本——各种咳嗽、叹气、环境噪声、设备杂音——这让模型学会了区分“人在说话”和“只是有声音”。相比之下,Smart-Turn的训练数据以朗读式语音为主,遇到真实口语场景和复杂噪声环境时,泛化能力就显得不足。
第二是模型容量的“甜点”。8M参数太小,无法充分编码语音中的韵律模式和语义完整性特征。7B参数又太大,大量参数被浪费在这个任务根本用不到的能力上。47M是团队经过多轮实验找到的平衡点——它足够大到覆盖判停所需的全部信号(包括区分语义内容和非语义噪声的能力),又足够小到让每个参数都在高效工作。
这个数字并非灵光一现的产物,而是几十次对照实验的结果。
快速使用
典型的接入路径是:VAD检测到语音段结束 → 提取音频特征 → 送入TurnSense → 根据结果决定响应、等待或忽略。
这里的关键区别在于:传统方案中,所有经过VAD的音频都会送入ASR,ASR产生的幻觉文本可能触发下游误响应。接入TurnSense后,被判定为Invalid的音频会直接被丢弃,根本不会进入ASR环节,从源头切断了噪声误触发的链路,同时也节省了ASR的算力开销。
由于TurnSense直接处理语音,它与ASR是并行关系。你可以在TurnSense进行判停的同时,让ASR开始转写,两者同时运行。当TurnSense返回“Complete”时,ASR大概率也已经出结果了,整体响应延迟取两者中的最大值,而非累加值。当TurnSense返回“Invalid”时,则直接丢弃ASR结果,不浪费下游任何算力。
模型以标准的ONNX格式提供(包含FP32和INT8版本),不绑定任何特定的训练框架。无论是Python、C++、Ja va还是Rust,你的技术栈是什么就用什么。INT8版本大小约50MB,一台普通云服务器就能跑生产流量,也能轻松打包进车机、手机或IoT设备。
从克隆代码到获得第一个推理结果,大概只需要3分钟:
git clone https://github.com/Bairong-Xdynamics/TurnSense.git
cd TurnSense
pip install -U numpy onnxruntime torch librosa soundfile pandas scikit-learn huggingface_hub
首次运行时会自动从Hugging Face下载模型。你也可以手动操作:
git lfs install
git clone https://huggingface.co/brgroup/TurnSense
运行推理:
python infer.py
实际效果
我们将TurnSense接入一个开源语音助手框架进行了内部初步测试(100轮对话,涵盖闲聊、任务指令、多轮问答三类场景,测试环境包含正常室内和模拟车载噪声):
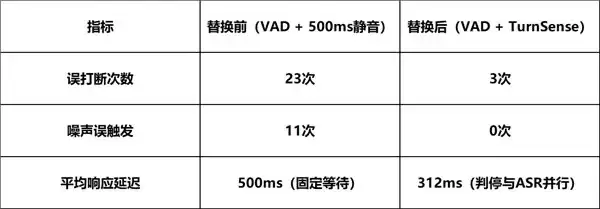
虽然样本量不大,结果仅供参考方向性趋势(后续会放出更大规模的评测报告),但三个方向性的结论应该是明确的:误打断现象大幅减少;噪声误触发从11次降到了0次,Invalid拦截能力在工程上验证了实验室指标;由于不再需要固定等待500ms的静音窗口,判停与ASR并行后,实际响应速度反而更快了。
噪声误触发归零这一点,对于特定场景的意义尤为突出:车载场景中路噪和乘客对话频繁;智能客服场景中用户的叹气和清嗓子是高频事件;智能音箱场景中电视声、孩子玩闹声随时存在。在这些场景下,一次误触发就可能彻底打断用户体验。
它不能做什么
需要明确的是,TurnSense也有其适用范围和局限性:
它不处理多轮上下文。TurnSense只看当前这一段语音,不参考对话历史。在大多数场景下,单段音频的韵律和内容信息已经足够判断,但确实存在一些边界情况需要结合上下文才能准确判断。
它以中英文为主。当前的训练数据和评测主要基于中英文,其他语种的效果尚未得到充分验证。
它不替代VAD。TurnSense是语义层的判停,仍然需要前置的VAD来完成语音端点检测。VAD告诉你“这段声音停了”,TurnSense则告诉你“这段话说完了没”以及“这段声音是不是话”。
它对音频质量有基本要求。在极端噪声环境或严重失真的音频下,判断可能会受到影响。但对于正常通话质量和设备录音,则没有问题。
关于百融Baiji Team
百融Baiji Team专注于语音交互基础设施,目标是让语音助手在真实环境中真正变得好用。团队核心成员来自国内头部语音AI公司,拥有多年对话系统工程与研究经验。TurnSense是团队的首个开源项目,后续还会在语音交互的其他关键模块持续输出。
链接
● 许可证:Apache License 2.0
● 评测框架和数据均随代码开源,支持一键复现所有指标
● 问题反馈和讨论:GitHub Issues / Discussions
项目采用Apache 2.0协议,商用免费。如果用了觉得好,欢迎在GitHub给个star;如果使用中遇到问题,也欢迎提个issue,团队会跟进处理。




