DeepSeek,这家中国AI领域的“异类”,最近似乎真的变了。
它曾像武侠小说里的“扫地僧”,凭借突然发布的DeepSeek R1大模型,一夜之间搅动了整个中国AI赛道的格局。其极低的成本和出色的性能,给全球同行实实在在地上了一课。
然而,这家公司的性格远不止于此。当整个行业都在狂热追逐风口,想方设法从市场中“掘金”时,DeepSeek却长期保持着一种特立独行的姿态——它曾是业内罕见的“拒绝融资派”。
这家一度站在中国AI赛道顶峰的公司,长期主要依靠创始人梁文锋及其背后的量化基金幻方量化支持。此前已有消息传出,DeepSeek曾婉拒中国头部风投和科技巨头的投资邀约。难怪路透社曾援引梁文锋的观点,认为DeepSeek“钱从来不是问题”。
但现在,情况似乎正在悄然改变。
当融资来敲门
变化早有端倪。今年2月19日,海外媒体The Information率先透露,一向坚持独立、拒绝外部资金的DeepSeek,正历史性地首次“考虑外部融资”。
报道称,在DeepSeek释放意向之后,迅速吸引了包括阿里巴巴和具有国资背景的基金在内的目光。不过,随后阿里高管公开否认,称相关消息不实,这轮融资传闻也就暂时沉寂。
真正再次点燃市场情绪的,是4月17日的后续报道。
The Information再次出手,这次的信息显然更为具体:DeepSeek正在洽谈融资,计划至少募资3亿美元,目标估值指向100亿美元。
这则报道在国内科技和财经媒体中引发了广泛转载。由于给出了明确数字,且未见相关方迅速否认,其可信度似乎大增。
紧接着,4月22日的报道,让“DeepSeek融资”这件事看起来不再像是“狼来了”。
依旧是The Information的消息,报道称中国科技巨头中的腾讯和阿里巴巴,均已与DeepSeek接触,商讨投资事宜。更引人注目的是,这轮融资的规模预期大幅提升——DeepSeek正寻求以超过200亿美元的估值筹集资金,较之前传闻的100亿美元翻了一番。
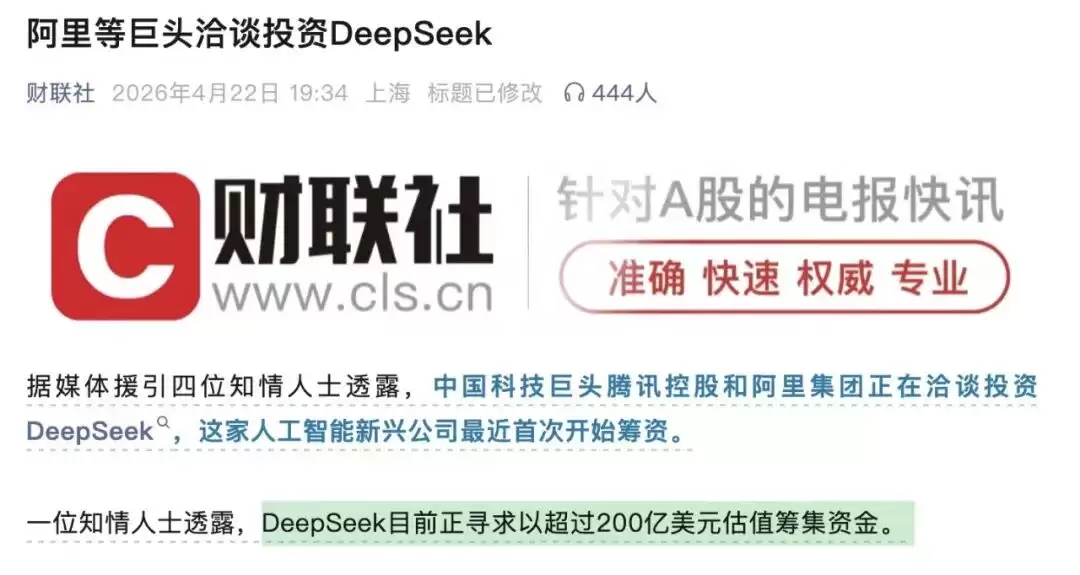
此外,包括《华尔街日报》在内的媒体也报道称,雷军旗下的顺为资本也参与了相关讨论。市场对DeepSeek的初步估值判断区间,大致落在100亿至300亿美元。
尽管谈判仍在进行中,融资规模和估值都可能变动,但至少说明,这次DeepSeek寻求首次外部融资的消息,其真实性远超前次。
不过,即便以当前市场主流的200亿美元估值来看,对比一年前那个炙手可热、地位卓然的AI“老大哥”,这个数字似乎并不算高。
回想一年前,智谱在行业中尚属“小透明”,Minimax在用户群体中近乎“查无此人”,而Kimi的标签,还是“被DeepSeek击败的旧时代公司”。
然而时过境迁。如今,Kimi的估值已攀升至180亿美元左右,与DeepSeek处于同一梯队。智谱和MiniMax更早一步登陆港股,若按最新股价计算,智谱市值约570亿美元,MiniMax约335亿美元,均已远超DeepSeek当前的估值预期。
不得不感慨,AI赛道风云变幻,短短一年已是沧海桑田。
从过去坚持不依赖外部输血,到如今疑似松口寻求首次融资,一个核心问题浮出水面:DeepSeek真的缺钱了吗?如果融资成功,这笔钱又将用在何处?
钱还是成了问题
事实上,此前不少人相信梁文锋“DeepSeek钱不是问题”的说法并非虚言。
毕竟有媒体报道称,DeepSeek的母公司幻方量化,2025年收益率约56.6%,年收入可达“50亿软妹币/7亿美元”量级。这个数字,显然已远超DeepSeek首次被曝寻求融资的3亿美元目标。
但问题在于,幻方量化很能赚钱,并不直接等同于DeepSeek不缺钱。
母公司赚取的利润,不可能毫无保留地全部注入子公司。而大模型行业本身,恰恰是一个有多少钱都能迅速烧光的“吞金兽”赛道。
看看全球头部玩家的做法就知道了:OpenAI预计到2030年,其累计算力支出可能达到惊人的6000亿美元;Anthropic则被曝与亚马逊达成协议,未来十年将在云基础设施上投入超过1000亿美元。
OpenAI与Anthropic的巨额投入计划,清晰地勾勒出这个行业的资金门槛。
因此,即便背后站着幻方量化,DeepSeek也未必能独自扛过这场漫长的军备竞赛。即便现阶段它真的感到资金压力,也完全在情理之中。
那么,“钱要怎么花”?从AI行业的普遍规律来看,答案其实并不难猜。
研究机构Epoch AI的数据显示,在对前沿模型训练成本的拆分中,硬件成本占47%–67%,研发人员成本占29%–49%,能源成本占2%–6%。其他多家媒体和机构的分析也指向类似的结论:算力/硬件支出和研发人才成本,是当前所有AI公司必须面对的“两座大山”。
也就是说,一家AI公司如果要大规模投入资金,基本绕不开两个方向:要么砸钱购置硬件(主要是算力芯片),要么烧钱争夺顶尖人才。
DeepSeek融资是为了买“卡”(算力芯片)吗?
先说结论:有这种可能,但这未必是核心答案。
从目前公开的信息判断,DeepSeek似乎并不像那种“突然断粮、急需补货”的硬件买家。
诚然,早期DeepSeek对英伟达计算卡的依赖度较高。路透社2月24日曾援引美国官员的说法称,DeepSeek某个新模型的训练,用到了本应禁售中国的英伟达最先进Blackwell芯片。
但几乎在同一时间,DeepSeek也在全力拥抱国产算力生态。
就在一天后的2月25日,路透社报道称,DeepSeek没有遵循行业惯例,将即将发布的旗舰模型提前交给英伟达、AMD等美国芯片厂商做性能优化,而是将这个“提前窗口”给到了包括华&为在内的国内供应商。
到了4月3日,路透社转述The Information的报道进一步指出,DeepSeek-V4将完全适配华&为的昇腾950PR芯片。为此,DeepSeek过去几个月一直在与华&为、寒武纪等合作伙伴重写部分底层代码,进行适配和测试,同时还在推进两个专门面向国产芯片的V4变体模型。

值得注意的是,昇腾950PR相比上一代产品,一个重要的改进就是对英伟达CUDA生态的兼容性更好,这能大幅降低中国科技公司将原有模型从英伟达体系迁移过来的成本。
由此可见,DeepSeek未必是单纯地“缺卡”,似乎也没有充足的理由,专门为了购买硬件而启动一轮大规模融资。
因此,另一种更现实的推测浮出水面:这次融资,或许是为了“人”。
DeepSeek,不能忍了
在今天的AI行业,硬件固然昂贵,但顶尖人才的价值更高。
全球AI头部公司的人才争夺战,已经激烈到令人咋舌的程度:
OpenAI的顶级研究员,年薪包常常超过1000万美元;为了留住核心员工,OpenAI曾向部分研究员提供200万美元的留任奖金,外加超过2000万美元的额外股权;Google DeepMind则为顶尖研究员开出了高达一年2000万美元的薪酬包。
再到2026年2月,路透社转述The Information报道称,OpenAI从Meta挖走了原苹果高管Ruoming Pang(庞若鸣),而Pang当初加入Meta时的薪酬包,据称价值超过2亿美元。
显然,AI顶尖人才身上,真的藏着“黄金屋”。
然而,从DeepSeek目前公开的信息来看,“出手阔绰”似乎还不是它的标签。
即便在有限的媒体报道中,例如路透社2月25日采访两位前员工的描述,提到在DeepSeek工作的特点是通常实行八小时工作制,氛围协作、扁平,创始人梁文锋甚至会与年轻研究员一起抠技术细节。
这样的工作环境,无疑是许多职场人梦寐以求的“象牙塔”,但对于当前身处风口浪尖的AI顶尖人才而言,可能并非最具吸引力的选项。
这些从业人员多是来自各领域的顶尖天才,自幼怀揣远大抱负,渴望成为像马斯克那样改变世界的人物。如今他们身处全球最炙手可热的赛道,面前摆着触及打工人财富天花板的机会。如果奋力一搏就有可能实现普通人一生难以企及的财富自由,那么“朝九晚六”的安稳,吸引力自然就大打折扣了。
因此,如果DeepSeek此番融资是为了打响“人才保卫战”,在逻辑上完全说得通。更何况,现实情况是DeepSeek的人才确实在不断流失。
今年3月19日,多家媒体报道小米未来三年将至少投入600亿元软妹币用于AI研发。而其刚发布的大模型MiMo-V2-Pro的团队负责人罗福莉,正是前DeepSeek研究员,据传被小米以千万级别的年薪挖走。
同样在今年3月,前DeepSeek核心研究员郭达雅转投字节跳动的Seed团队,专注于Agent方向。市场一度传闻,这次“人才流动”涉及的薪酬包接近亿元级别。
如果成功获得融资,DeepSeek在“保住人才”方面能做的事情就多了。
首先是“留人”。面对已被市场明码标价的顶尖研究员,DeepSeek过去“公司技术强,但股权未定价、外部资本未进入”的状态,在竞争中天然处于劣势。融资后,公司便有能力为这些核心人才提供具有市场竞争力的激励方案。
其次是“奖励”。公司从默默无闻到名满天下,一路并肩作战的“老兄弟们”理应获得丰厚的回报。融资可以为此提供充足的资金池。
最后是“招人”。下一代模型、智能体(Agent)、多模态技术、国产芯片适配……每一项都不是靠一两个天才就能单打独斗完成的。一旦现金流更加充沛,DeepSeek就不仅能抵御外部“挖角”,也能主动出击,在全球范围内招募顶尖人才。
当然,融资的真实用途,外界终究只能猜测。甚至这笔融资是否确有其事,也只有谈判桌前的参与者心知肚明。
但一个不争的事实是:算力需要钱,人才需要钱,而且需要的数额远超以往任何科技浪潮。强如DeepSeek,恐怕也无法一直扮演那位不食人间烟火的“扫地僧”了。




