靴子终于落地。
被调侃“Next Week”近三个月的DeepSeek V4,总算揭开了面纱。1.6万亿的最大参数量、100万的上下文窗口、针对智能体(Agent)的性能优化,以及基于MoE(混合专家模型)和稀疏注意力机制DSA来降低计算和显存需求——这些此前被外界反复猜测的核心参数,随着官方发布一锤定音。
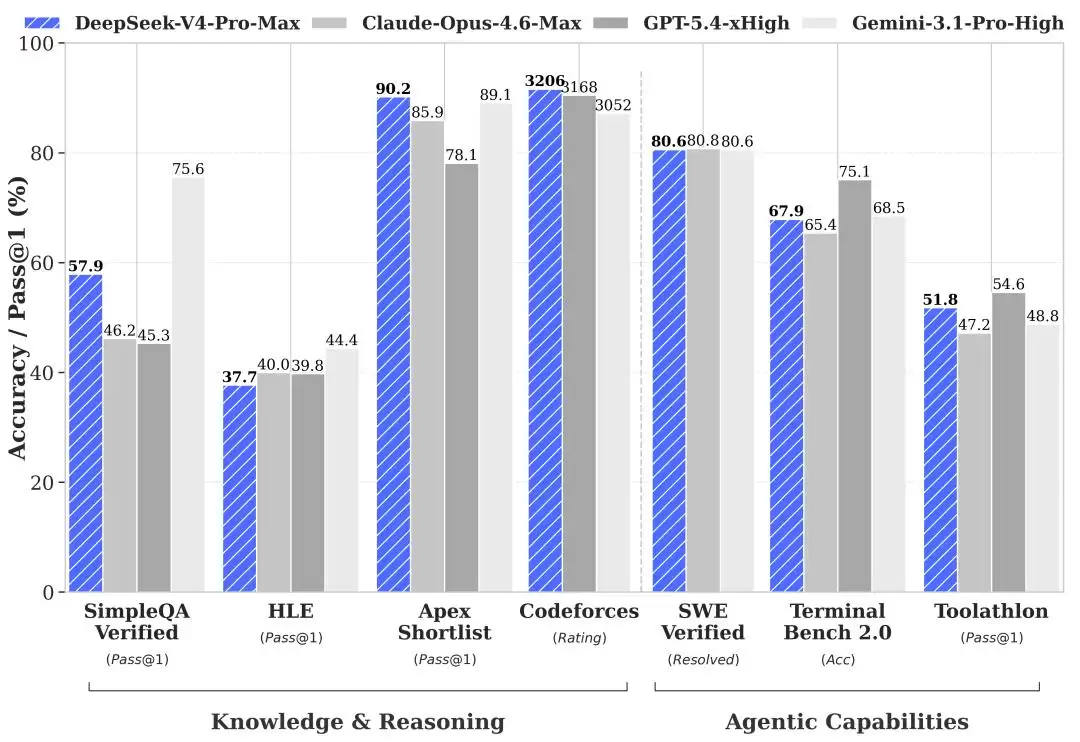
DeepSeek V4性能测评结果。
发布姗姗来迟,原因与V4将训练框架从英伟达迁移到华&为昇腾有关,也与公司内部的一些决策变动有关。据了解,2025年年中,DeepSeek曾经历一次较为严重的训练失败。
“当时,DeepSeek面临重新适配芯片的问题。”一位知情人士透露,“内部关于训练方向的意见也不完全统一。梁文锋提出了一些具体要求,但在执行层面很难折中。”
不过,与外界关于“新模型支持多模态生成和理解”的猜测不同,V4依然是一个纯语言模型。暂缓多模态生成的训练策略,主要源于算力和资金的现实掣肘。
多位知情人士表示,DeepSeek的对外融资窗口,是在2026年4月中旬打开的。内部的直接动因,是公司需要更多资金来支持训练参数规模更大的模型,同时,也是为了留住和招纳更多的顶级人才。
“1.6万亿的参数量,与OpenAI、Anthropic等顶级厂商的模型相比,并不具备绝对的领先优势。”一位行业从业者分析道,很快,国内也有模型厂商将发布**3万亿**参数规模的模型。
在人才方面,随着郭达雅(DeepSeek R1核心作者)、王炳宣(DeepSeek LLM核心作者)等核心人才被字节、腾讯等大厂挖走,DeepSeek亟需一笔大额融资来稳定军心、扩充团队。
而转向开放融资的外部催化剂,几位业内人士猜测,与腾讯的投资态度有关。在开放融资前,梁文锋和马化腾曾就腾讯独家注资进行过几次商谈。但据两位相关人士透露,给予腾讯20%股份的条件,并未获得梁文锋的同意。
自R1发布以来,一个明显的趋势是:**DeepSeek从一个偏向非营利、充满理想主义的技术乌托邦,被迫快速转向一家重视产品与商业化的务实公司。**
2026年4月8日,DeepSeek App进行改版,上线了支持复杂推理的“**专家模式**”和处理简单任务的“**快速模式**”——随着V4的发布,我们得以确认,负责“专家模式”的是1.6万亿参数的V4-pro,而负责“快速模式”的则是2840亿参数的V4-flash。
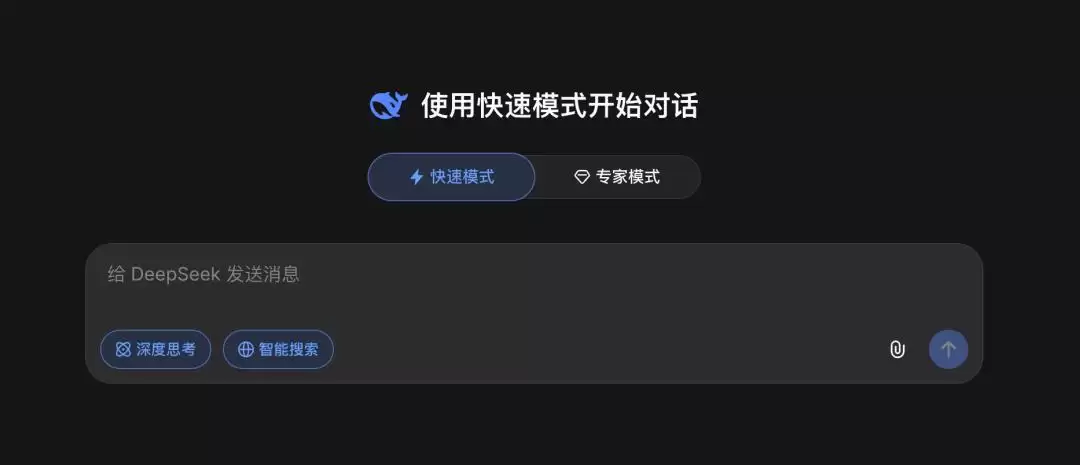
DeepSeek App的两种模式。
有知情人士表示,2025年下半年以来,梁文锋开始高度重视产品的打磨。多名大厂AI产品经理提到,2025年末,DeepSeek对产品策略和经理岗位进行了“开闸式招聘”,他们也多次收到来自DeepSeek HR的联络。
一位业内人士也透露,**DeepSeek内部已经搭建了数个创新产品团队,正在对智能体(Agent)和其他面向消费者(C端)的产品形态进行探索。**
从更新后的版本看,DeepSeek的文本能力提升显著。过去一年,不止一位AI行业的HR和猎头提起,**曾多次在北京大学中文系的宿舍区,遇见正在添加学生微信的DeepSeek招聘人员。**
招聘中文系学生的目的,是为了进行人文领域的数据标注和测评标准搭建。这被视为DeepSeek重视模型“人文性”的一个明确信号。
尽管“普惠”、“开放”、产品界面极简到只有一个聊天框,是DeepSeek对外呈现的形象。但据了解,2025年,DeepSeek对产品和商业化的探索从未停止——**目前,内部已经组建了一支数十人的产品团队,专门探索智能体等产品形态。**
甚至更早之前,在2024年尚未爆火时,DeepSeek也曾考虑过投放广告进行推广,但这一提议很快被梁文锋否决。
DeepSeek的年度更新终于放出,犹如终于落下的达摩克利斯之剑,让中国乃至全球的模型厂商们悬着的心稍稍放下。
迈入2026年后,DeepSeek的年度迭代,几乎成了AI世界的“狼来了”故事。避开DeepSeek的发布窗口,成了近几个月模型厂商的标准动作。
两家刚刚上市的大模型厂商,智谱和MiniMax,就在春节前错峰发布了新模型GLM 5和M 2.5。
一位智谱员工表示,“DeepSeek将在春节发模型”的传言一出,算法团队立刻召开紧急会议,要求“尽早”发布GLM 5。
MiniMax的一名员工也证实,1月中旬,港股IPO庆功酒的宿醉还未完全消退,算法团队的成员就已自觉早早回到了工位。
**“错峰发布”,对这两家已经完成IPO的模型创业公司而言尤为重要。**“如果比DeepSeek晚发布,性能又不如它,肯定会冲击股价;但如果迟迟不发布,同样会影响股价。”上述员工解释道,“影响最小的办法,就是提前发布。”
模型公司的融资动作,也必须抢在DeepSeek更新之前完成。
1月末宣布完成B+轮融资的阶跃星辰,也迫切地希望在春节前敲定这轮融资。一位知情人士透露,一旦DeepSeek再次“掀桌子”,和投资人的沟通成本将会变得极高。
在从业者眼中,牌桌上一直存在着“两个DeepSeek”——一个带来被倾轧的恐惧,另一个则作为范式的引领者。在模型厂商们进展温吞的两年里,行业需要这样一个“不确定性因素”,来促使大家反思,继而全力冲刺。
MiniMax一名员工记得,在年后的内部信和全员会上,创始人兼CEO闫俊杰提到:**“DeepSeek帮我们走出了一条我想走的路。”**
即便中国AI从业者对DeepSeek的感情复杂,但人们不得不承认,DeepSeek改变了中国AI行业的诸多游戏规则。
改变往往意味着推倒与重建,这注定不会是一个舒适的体验。但正如一位关注早期科技公司的投资人所评价的那样:DeepSeek奠定了近一年来中国大模型领域的组织文化与研发重点,而在这之后,**“它是中国AI跻身全球一流的起点,但绝不会是终点”。**
DeepSeek让中国AI行业的竞争格局进入了相对稳定的中场。但在模型技术的早期阶段,DeepSeek为行业留下的并非全是共识。随着商业化与竞争压力加剧,围绕开源、商业化、增长等核心命题,各个厂商正在走向不同的分岔路。
在DeepSeek V4发布前夕,我们与十余位AI行业人士进行了对话,主题是:“DeepSeek改变了中国AI行业什么?”
以下,是我们从中梳理出的五条“后DeepSeek时代”的新命题。
命题一:重新审视开源的性价比
一年前,DeepSeek R1公开技术报告后,一位AI投资人的判断是:回归基础模型研究、依靠开源开放打响技术品牌,对模型厂商而言是最重要的事。
但如今,他坦言当时的判断有待商榷。
跟随DeepSeek开源一年后,厂商们大力托举开源和研究生态的时代是否即将终结?这个关键问题,随着近期阿里通义千问大模型技术负责人林俊旸的离职,被摆到了台面上。
某种意义上,林俊旸领导的Qwen系列,代表着开源生态的利益。然而如今,这与阿里巴巴作为商业公司的营利性本质,产生了尖锐矛盾。
“**非盈利的黄金时代结束了。**”针对这一事件,一位Qwen团队成员如此评价。
让厂商们动摇的事实是,**目前全球营收最高的两家模型厂商,走的都是闭源路线**——OpenAI,年化收入超过2500亿美元;Anthropic,年化收入超过1900亿美元(据The Information报道,数据截至2026年2月底)。
至于国内厂商的模型收入,近期披露的2025年财报显示,MiniMax全年总收入为7903.8万美元,智谱为7.24亿元软妹币(约合1.05亿美元),与OpenAI和Anthropic相比,仍有数个数量级的差距。
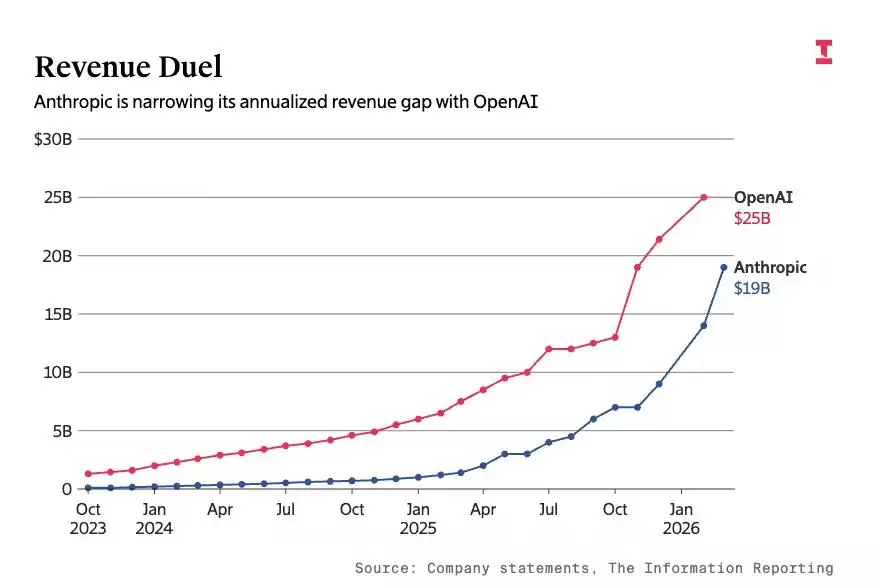
△2023年以来,OpenAI和Anthropic的年化收入情况。图源:The Information
2026年1月的AGI Next大会上,智谱创始人唐杰也曾发出警告:“我们可能只是在‘开源游乐场’里玩得开心,而美国的闭源模型早已进入下一个纪元。”
毫无疑问,DeepSeek带动的开源开放生态,让中国模型在2025年快速在全球建立了知名度和技术口碑。
但一个残酷的现实是,依靠开源快速完成“冷启动”、建立技术口碑的阶段已经过去了。在基础模型研发依然极度“吞金”的当下,如何将口碑转化为真金白银,成了更重要的生存命题。
开源的价值,到了需要被重新审视的时刻。
命题二:投流大战暂停,精细化投放开打
该如何解读DeepSeek“零投流,App上线7天用户破亿”的成绩?
放在一年前,行业的目光会不由自主地聚焦在“零投流”上——这套破圈叙事,推翻了不少厂商深信不疑的增长路径,也戳破了当时模型产品靠烧钱换来的虚假繁荣。
警醒之后,是应激反应。2025年初,不少公司都做出了与大举投流同样激进的反思。
其中的典型,便是当初拉开投流大战序幕的月之暗面。
据了解,在2025年2月一场持续了五六个小时的战略会上,月之暗面联合创始人张予彤宣布,立刻暂停Kimi在安卓渠道的投流,同时将iOS渠道的投流预算,从原来的每天千万元级别,削减至每天数万元。
一位头部AI创业公司的中层曾假设:以Kimi和豆包为主角,**AI应用激进的投流大战,大概率会持续到2025年第二季度**,按照平均每个季度2亿美元的投流支出计算,月之暗面可能会因资金压力率先退出。
当应激情绪逐渐回归理性,多数厂商的增长团队成员都表示:投流,仍要继续,但要做聪明的、有的放矢的增长。
事实上,激进的投流和补贴大战,并未因DeepSeek的非典型成功而停止。只是,**参战的主要对象,只剩下了财力雄厚、手握流量入口的几家互联网大厂**。
增长大战最白热化的一幕,发生在刚过去不久的2026年春节。阿里通义千问豪掷30亿元请用户喝奶茶,腾讯元宝狂撒10亿元红包,字节则用同样的10亿元,将豆包送上了春晚的舞台。
一家头部AI创业公司的增长团队成员,将如今的投流环境形容为“巧妇难为无米之炊”:“**流量入口被大厂牢牢把握,意味着剩下的模型厂商,必须采用更精细化的增长方式,放弃建立大众认知,转而聚焦目标用户。**”
他举了个例子:如果AI产品的主要应用场景是金融、法律办公,那就把产品推广到相关的金融App上,流量成本反而更低。
命题三:回归基模,选实用,还是选研究?
R1出圈后,聚焦基础模型研发,一夜之间成为AI模型厂商的共识。
“我们对自己的研究方向,都更坚定了。”一位亲历R1发布的前月之暗面研究员表示,“R1并非石破天惊的创新,但它证明,**只要大方向判断不出错,厂商坚持自己的技术路线,就能获得性能上的正反馈**,就像DeepSeek一直坚持纯语言和推理路线一样。”
此前,为了冲击排行榜或是追逐热点,不少厂商会将聚焦于推理、对话等不同能力的模型分开单独训练。
“这样做固然可以针对某项能力进行调优,但模型的综合实用性会打折扣,客户也不一定买单。”一位智谱员工坦言。他提到,一个令智谱警铃大作的现象是,R1发布后,不少行业头部客户转向了部署DeepSeek。
当时的智谱在冲击中,做出了一个在该员工看来“艰难但正确”的决定:训练一个同时聚焦推理、编程和智能体能力的模型,即GLM 4.5。
“**这是智谱第一个‘反榜单’导向的模型,所有性能调优方向都从真实的客户需求中来,**”他表示,“从某种意义上说,这也是智谱的背水一战。”
同样的反思,也席卷了大厂。2025年1月,前谷歌DeepMind研究副总裁吴永辉挂帅字节模型团队Seed后,“不刷榜单,聚焦模型能力本身”的方针就被多次强调。
类似地,多位知情人士透露,前OpenAI研究员姚顺雨加盟腾讯后,花了大力气重建模型和AI产品的测评体系,直接对接人员具体到每个场景的负责人,甚至他们的直属下级。
“原来混元(腾讯大模型团队)的风格偏向‘刷榜’,让模型性能有些虚假繁荣。”一位混元成员表示,“顺雨看问题很尖锐,他希望团队能认清模型的真实水平,回归研发本身。”
然而,共识之下必有裂隙。技术研发向来有“实用派”和“研究派”之分,前者注重赢得竞争和商业落地,后者注重学术价值与长远探索——具体到一家商业公司体系中,在手头宽裕的时代,承担AI“研究派”角色的,往往是AI Lab或研究院。
但是,随着AI投入的压力逐步加大,**基础模型研究究竟该倾向“研究”还是“实用”,业界并没有统一的答案。**
可见的趋势是,在商业化目标的驱动下,“实用派”目前占据了上风。一个显著的信号是,AI Lab正在后退或消亡,研发资源被集中到“实用派”手中。
2025年以来,字节的AI Lab被并入Seed团队,阿里达摩院的多个研发团队被重组至通义实验室;2026年3月20日,腾讯也撤销了成立近十年的AI Lab,团队成员并入混元大模型团队。
但DeepSeek在某种意义上依旧验证了,**伟大的突破是无法被计划出来的**,不少碘伏性技术恰恰源自非功利性的研究。
依然有厂商选择给“研究派”保留自由探索的空间——例如,在字节Seed内部,还设置了注重前沿研究的虚拟组织“Seed Edge”,鼓励骨干攻克更基础、更长期的AGI课题,并将考核周期延长至三年。
命题四:大模型组织,顶层扁平高效,基层人海战术
命运的齿轮,在梁文锋决定脱离幻方量化、单独成立DeepSeek的那一天就开始转动了。
一位接触过DeepSeek早期成员的知情人士透露,2023年初,DeepSeek早期团队到位后,梁文锋就坚持将DeepSeek从幻方独立出来,理由是“**幻方不是AI时代的组织形式,想要实现AGI,必须脱离原有的组织惯性做事。**”
**R1的成功,让不少模型厂商开始重新审视,什么才是适配AI时代的人才组织形式。**
“**本质上,每一代(巨头)企业,都是那个阶段最先进的组织,去适配那个时候的技术和商业**,从而脱颖而出。”在近期的一次播客访谈中,阶跃星辰董事长印奇也提到,如今每家企业都不缺AI顶尖人才,关键在于组织形态。
据了解,**DeepSeek采取的是相当扁平化和“学院派”的管理方式**:成员根据具体目标分成不同的研究小组;组内没有固定的分工和严格的上下级关系。这种组织形式的好处在于,能够充分发挥成员的想象力,更好地适配创新业务。
对于规模尚不大的创业公司而言,寻找适配AI时代的组织形式,尚有较高的试错空间。不少头部AI创业公司的员工都表示,2025年以来,扩张规模成为一件“非常谨慎”的事。不少企业甚至选择主动收索,目的是“更高效、更聚焦”。
但对于动辄万人规模的互联网大厂而言,打破原有的组织惯性并非易事。正如印奇所言:**创新者的窘境,往往是组织问题;领域内越是优秀的公司,越是将组织模式固化得更好,但往往也更难改变。**
只是,对于大厂而言,在AI时代延续辉煌是必须完成的任务。
2025年以来,**大厂玩家都试图将模型研发和AI创新业务,整合为一个相对独立于传统互联网业务的组织,并用更扁平的方式进行管理。**
例如后来居上的腾讯。据了解,原来分散在各个事业群(BG)中的模型核心研发资源,在数次调整后,被集中到姚顺雨管理的AI基础设施部,以及大语言模型部。
在近期的内部答疑会上,姚顺雨针对AI Lab与混元的整合也做出了回应:要打破部门墙,让AI基础模型的开发和研究架构**更年轻、更直接**。
然而,精简研发团队的另一面,是数据、评测等支持团队的激进扩张。
“模型底层算法的迭代,目前进入了一个平台期。在算法架构没有突破性进展的情况下,训练数据的质量在模型性能迭代中起到了关键作用。”一位大语言模型研究员指出,“尤其是视频、3D等涉及主观审美的多模态数据,各家厂商之间的质量差距会非常明显。”
用高薪、高职级来组建数据、评测团队,在不少厂商中已经屡见不鲜。
一位知情人士透露,**近期字节Seed团队的总规模相较于年初,已经翻了约两倍**。**豆包某一个尺寸的模型,仅负责智商评测的就有5人,负责策略产品的更有五六十人**,“豆包、Seedance目前的性能优势,在相当程度上是靠人力堆出来的。”
在数据供应的上游,盘踞在成都、武汉等城市的数据标注公司,已经跑出了不少年营收过亿的“隐形巨头”,招聘的普遍门槛,从中专、大专,抬高到了211高校的硕士。
“**金字塔结构**”,一位Seed研究员如此形容当前模型组织的标准范式:研发的顶端,是少数顶尖大脑;而为顶层输送燃料的数据、评测工作,依然需要人海战术。
命题五:年轻人和“一把手工程”
组织最重要的毛细血管,终究是人。很难说,**是DeepSeek统一了行业“重视年轻天才”的人才审美**,但各个厂商对AI年轻人才的渴求,确实被拉到了一个史无前例的高度。

△腾讯“CEO/总裁办公室”首席AI科学家 姚顺雨,1998年生。图源:姚顺雨个人博客
“很多大厂的HR团队,前几年招人的姿态都比较‘甲方’。”一位在AI行业从事了七八年高端人才招聘的猎头表示,“他们只负责谈薪资,但与人才在业务层面的沟通都比较浅。”
明显的转变发生在R1发布之后——**抢人,成了各大公司的‘一把手工程’。**
例如,2025年以来,隐退近四年的张一鸣频繁现身新加坡,目的就是引进全球各地的AI人才。也有不少人看到,腾讯总裁刘炽平亲自带领HR团队,出现在多个国内外顶级计算机会议现场,给参会者发名片、加微信。
一位混元成员也表示,**姚顺雨进入腾讯后的一个重要任务就是招人**。自2025年9月加入腾讯以来,他已经为混元面试了近百人,“每个校招生他都会亲自面试,也经常邀请突出的实习生一起吃饭交流”。
“DeepSeek终于让厂商们**自上而下**对齐了一件事:**AI就是最高优先级的任务(top mission)。**”一位AI投资人总结道。
结语:一直仰望,就无法超越
DeepSeek不能一直待在神坛上。正如一位混元研究员所言:**一直仰望,就无法超越。**
2025年下半年以来,模型玩家们对DeepSeek的态度,不再只有景仰,而是暗自卯足了超越的劲头。
这一点,在去年借助DeepSeek流量快速托举起元宝的腾讯身上,尤为明显。一位元宝员工透露,**截至2025年底,仍有约七成用户将DeepSeek选为元宝的默认模型**,而非腾讯自己的混元模型。
“2026年,元宝的一个重要目标就是摆脱对DeepSeek的依赖,让腾讯自己的搜索品牌形成一定的用户心智。”她表示。
当然,这也势必伴随着更激进的模型研发目标。一位混元研究员告诉我们,对于2026年4月23日发布的新模型Hy3 preview,腾讯设定的目标是跟上第一梯队。**而第一梯队的名单,就是DeepSeek和阿里。**
对于牌桌上更早进场的其他玩家而言,经过一年的调整与加速,几乎所有厂商都在模型赛道找到了差异化的定位:
字节和阶跃星辰聚焦全模态;月之暗面和智谱深耕编程和智能体能力;MiniMax在保持语言模型不掉队的同时,突出其视频生成模型的优势。
“每个厂商都在沿着自己的路线走下去。”一位行业观察者Jason指出,“这条路的终点可以是AGI,也可以是巨大的商业成功,但绝对不会是包括DeepSeek在内的任何一家公司。”
2016年,埃隆·马斯克和OpenAI CEO山姆·奥特曼有过一段公开对话。马斯克提到:“人们有时会认为技术每年都会自动进步,但其实并非如此。**只有聪明的人们拼命努力去改进它,技术才会进步。**”

△埃隆·马斯克(右)与山姆·阿尔特曼(左)的对谈。图源:YouTube@Y Combinator
2025年初,DeepSeek恰好成了那个吹哨的“聪明人”。而到了2026年,努力的“聪明人”注定会更多。




