2024年底,一篇题为《流式深度强化学习终于跑通了》的论文在学术界引发了广泛关注。来自阿尔伯塔大学Mahmood团队的研究者,在论文中揭示了一个核心困境:强化学习本应具备“边交互边学习”的能力,但在深度神经网络时代,一旦移除经验回放缓冲区并将批量大小设为1,训练过程便会迅速崩溃。他们将这一现象命名为“流式壁垒”。
当时,他们提出的StreamX系列算法,通过精心设计的超参数、稀疏初始化及多种稳定化技巧,初步跨越了这一障碍。
然而,仅仅一年半后,该团队与来自Openmind研究院的合作者共同发表的新研究,提出了一个颠覆性的观点:流式壁垒的根本原因,或许并非“数据量不足”,而是“学习步长的度量单位存在偏差”。

传统步长设定:为何成为流式学习的瓶颈?
设想你正在学习驾驶,练习倒车入库。教练的指令是“每次踩下油门0.1秒”。但问题在于:相同的0.1秒,在上坡与下坡、空载与满载的不同条件下,车辆实际移动的距离可能天差地别。结果可能是精准入库,也可能因误差过大而撞墙。
传统基于梯度的学习,其步长设置正面临类似困境:它规定了模型参数每次更新的“固定距离”,却无法控制这一更新对模型实际输出(如价值预测或动作选择)产生的具体影响。在批量训练模式下,成百上千个样本的梯度被平均,极端波动得以稀释。然而,在纯粹的“流式”环境中,每一步仅有一个样本,缺乏平均机制。一旦梯度方向或幅度不稳定,更新量便会剧烈震荡——时而前进过多,时而后退过猛,最终导致整个学习过程失稳崩溃。
这种“更新过冲与欠冲”的难题在强化学习中尤为突出,因为每个时间步的梯度不仅大小不一,其方向本身也处于快速变化之中。
核心理念转变:从“走多远”到“改变多少”
那么,是否存在更优的解决方案?来自Openmind研究院的Arsalan Sharifnassab与阿尔伯塔大学的Mohamed Elsayed、A. Rupam Mahmood及Richard Sutton等人在最新论文中提出了一个简洁而有力的思路:与其硬性规定参数移动的步长,不如直接设定我们希望模型输出发生多大改变,并据此反向推导出所需的步长。
这一思想并非无源之水。早在1967年,日本学者Nagumo和Noda在自适应滤波领域提出的“归一化最小均方”算法,其核心便是通过期望的输出变化来动态调整步长。不过,该算法仅适用于线性模型。
如今,研究者们将这一原理成功推广至复杂的深度强化学习场景,并将其命名为“意图更新”。其核心在于:在每次参数更新前,先明确“本次更新希望达成的目标”,然后计算出能精准实现该目标的步长。
具体而言,在价值函数学习(预测未来累积奖励)中,意图被定义为:每次更新后,当前状态的价值预测误差应缩小一个固定比例(例如5%)。在策略学习(优化决策行为)中,意图则是:当前动作的被选概率,每一步仅允许发生“适度”的变化。
回到驾驶的比喻:这相当于司机每次操作前,先决定“我需要让车辆向前精确移动20厘米”,然后根据实时路况(坡度、载重)自动计算出所需的油门深度,而非机械地执行固定时长的踩踏动作并听凭结果随机波动。
图灵奖得主的持续探索:夯实强化学习基石
这篇论文的作者名单中,有一位里程碑式的人物:Richard S. Sutton——2024年图灵奖得主,被公认为“现代强化学习之父”。
Sutton在学术界的地位举足轻重。他不仅提出了时间差分学习与策略梯度算法,奠定了现代强化学习的算法基础,还与Andrew Barto合著了该领域的经典教科书。2024年,他与Barto共同荣获图灵奖,以表彰他们“为强化学习奠定了概念与算法基础”。
获奖后,Sutton并未止步,而是将奖金投入其创立的非营利研究机构——Openmind研究院,旨在支持年轻研究者在无商业化压力的环境下探索基础科学问题。本篇关于流式学习与意图更新的论文,正是该机构产出的重要成果之一。
论文第一作者Sharifnassab此前刚在ICML 2025发表了MetaOptimize框架,专注于在线自动调整学习率。这两个课题高度聚焦于同一个根本问题:如何让“步长”这一最基础的组件,自身变得更加智能与自适应。
算法实现:简洁而高效的设计
“意图更新”的数学形式相当优雅。其核心公式可概括为:步长 = “期望的输出变化量” / “梯度对输出的实际影响力度”。
在价值学习中,“实际影响力度”由梯度向量的范数衡量(反映了当前参数区域的“陡峭”程度):在陡峭区域,步长自动减小;在平缓区域,步长自动增大。从而确保每次更新对价值函数产生的“冲击”幅度基本一致。
在策略学习中,“期望变化量”与优势函数(当前动作优于平均水平的程度)成比例。同时,通过滑动平均进行归一化,确保长期来看策略更新的幅度稳定在可解释、可控的范围内。
研究者将这一核心机制与两项成熟的工程技术相结合:RMSProp风格的对角缩放(处理不同参数维度的尺度差异)和资格迹(助力奖励信号在时间步上有效传播)。
最终,他们构建了三个完整的算法:用于价值预测的Intentional TD (λ)、用于离散动作控制的Intentional Q (λ),以及用于连续控制的Intentional Policy Gradient。



性能评估:流式学习媲美主流批量算法
论文在多个标准基准任务上对方法进行了全面评估,结果令人瞩目。
在MuJoCo连续控制任务(包括Ant、Humanoid、HalfCheetah等复杂仿真机器人)上,新方法Intentional AC在纯粹的流式设置下(批量大小=1,无任何经验回放缓冲区),其最终性能多次接近甚至比肩SAC算法——后者是使用大规模回放缓冲区的、当前连续控制领域的黄金标准。在计算效率上,优势更为显著:Intentional AC单次更新所需的浮点运算量,仅为SAC单次更新的约1/140。
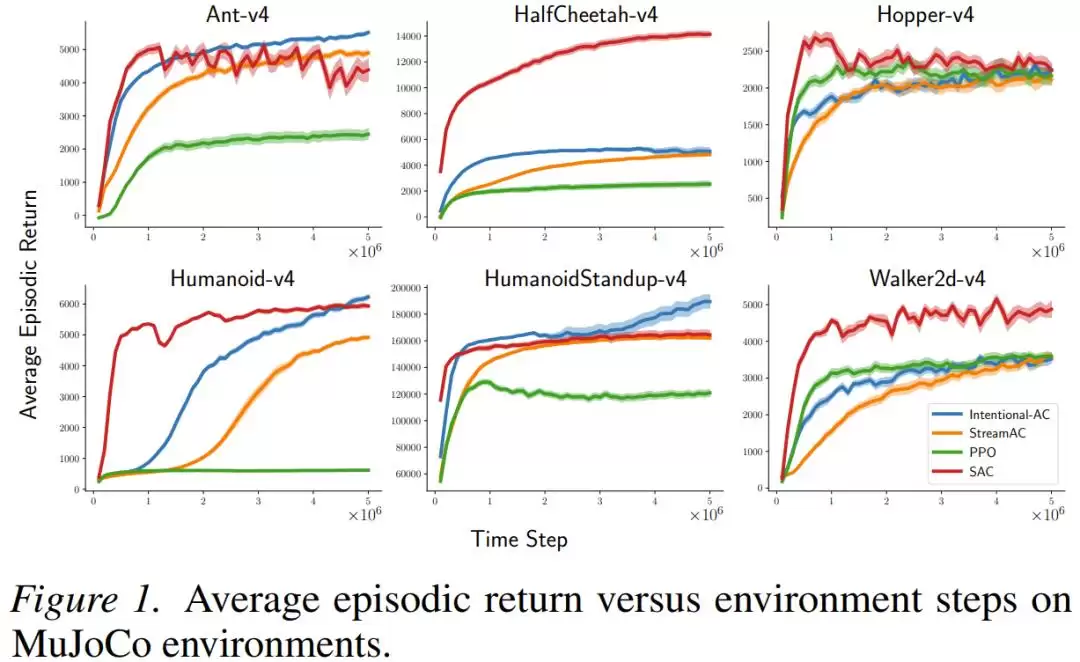
在Atari和MinAtar离散动作游戏上,Intentional Q-learning的表现与使用回放缓冲区的DQN算法相当,并且仅用同一套超参数就成功在所有任务上运行,无需针对每个游戏进行繁琐的调参。
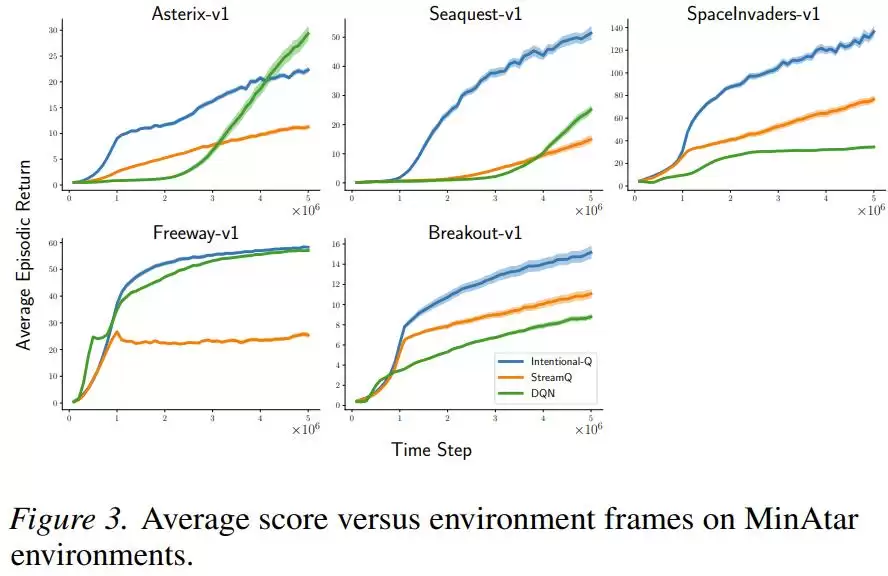
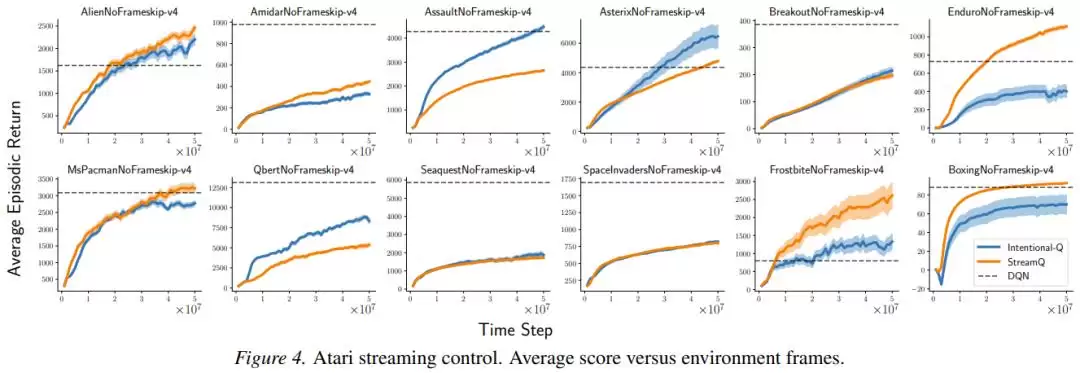
研究者还专门验证了“意图”是否被准确达成。他们测量了实际更新量与预期更新量的比值。在禁用资格迹的简化设置下,该比值的标准差极低(0.016到0.029),99分位数均在1.07以内。这表明,在绝大多数情况下,更新确实精准地实现了“预设的改变目标”。
此外,消融实验表明,即使移除RMSProp归一化或某些辅助项,性能虽有下降但仍具竞争力,而“意图缩放”机制本身才是性能提升的首要贡献者,其他组件主要起辅助稳定作用。
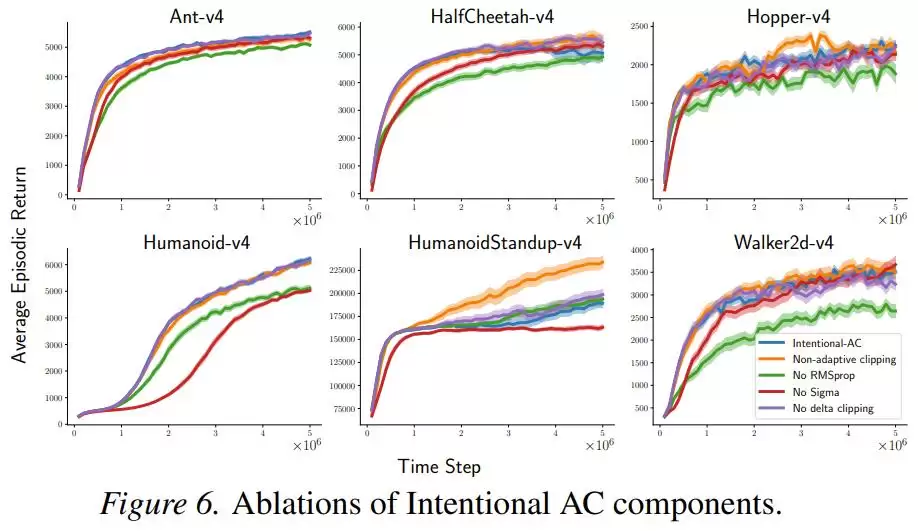
挑战与未来方向
“意图更新”框架在鲁棒性上也展现出优势。当研究者逐步移除StreamX方法所依赖的各种稳定化技巧(如稀疏初始化、奖励缩放、输入归一化、LayerNorm)时,Intentional AC的性能衰减远小于原始的StreamAC。这说明,意图缩放从原理上降低了对这些外部“辅助工具”的依赖。
然而,论文也坦诚指出了当前方法的一个局限:在策略学习中,步长依赖于当前采样到的具体动作,这可能导致不同的动作在更新中被隐性地赋予不同权重,从而在理论上可能引入策略梯度方向的偏差。在Humanoid等任务中,通过测量期望更新方向的余弦相似度,研究者发现这种偏差影响甚微(接近0.96);但在Ant-v4任务中,对齐度的中位数降至0.63,表明该问题在某些场景下仍需关注。
作者指出,未来的研究应探索与动作选择无关的步长策略,使得“意图”在期望意义上也能保持无偏。这是该方向留给后续研究者的一个明确课题。
结论:迈向持续在线自适应的智能体
当前主流的大模型训练范式,依赖于对海量静态数据的批量学习与反复迭代。这套“先训练,后部署”的路线虽成效显著,但模型一旦训练完成便基本固化,难以从后续持续的实时交互中进行高效、低成本的在线更新。
流式强化学习所追求的,是一种截然不同的范式:不依赖海量经验回放,无需庞大GPU集群,让智能体能够将每一步实时经历即刻转化为参数更新,实现持续、廉价、自适应的终身学习。这无疑更贴近人类与动物在环境中“边做边学”的自然模式。
从2024年“初步跑通”的突破,到本篇论文提出的“意图更新”原则,流式深度强化学习正以前所未有的速度走向成熟。它并非旨在取代批量训练的大模型,但对于需要长期在线适应的机器人、边缘计算设备,以及任何无法承担大规模回放缓冲区与高算力负载的应用场景而言,这条技术路径正展现出越来越强的实用价值与说服力。
步长不再仅仅是一个需要反复调试的超参数,它本质上成为了AI智能体每一步“意图改变多少”的清晰承诺。当这一承诺变得可度量、可控制,整个学习过程,也就获得了前所未有的稳定性。




