你有被AI“稳稳接住”过吗?
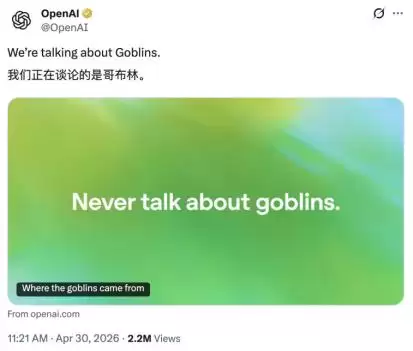
前阵子,ChatGPT对“哥布林”的莫名执着在国外火了一把,逼得OpenAI专门发了篇博客,研究这股“哥布林狂热”到底从何而来。他们发现,这类小习惯已经刻进了模型的“底层逻辑”,想纠正,只能在规则里硬生生加上一条:“禁止谈论哥布林”。
而在中文世界里,如果要给ChatGPT找个“祖传染色体”,那“稳稳接住”绝对榜上有名。这句话已经成了一个网络迷因,催生了大量表情包和段子。连同其他大模型那些常见的、带着浓浓“人机味儿”的表达方式,一起在互联网上病毒式传播。
但平心而论,这些话本身未必“非人”,甚至可以说情感充沛。问题出在它们被用得太多、太顺手,几乎成了条件反射式的固定回复,这才让原本可能真诚的表达,显得廉价而刻意。

如今,这个“我会稳稳地接住你”的梗,已经火出了国门。
《连线》杂志近日就刊发了一篇文章,标题直接点明:《ChatGPT在美国患上了“哥布林”狂热症,而在中国,它只想“稳稳地接住你”》。文章中提到,不止是ChatGPT,可能很快就会有更多AI模型争着抢着要“接住”你了。
另一边,国内厂商MiniMax的工程团队,则发布了一份详尽的内部排查报告,把之前闹得沸沸扬扬的“不认识马嘉祺”事件,从头到尾捋了个清清楚楚。
他们发现,模型并非真的“不认识”这位艺人,更像是“爱在心口难开”——话到了嘴边,却怎么也说不出来。当然,现在这个问题已经解决了。
ChatGPT的“贴心”口癖
无论是让ChatGPT解一道数学题,还是给它一段生成图片的提示词,你都很可能收到这样一句回复:“我会稳稳地接住你”。
这句话的英文原型“I will catch you steadily”,本意是“不管发生什么,我都会支持你”。在英语语境里,类似的“I've got you”表达轻松又自然。但直译成中文的“稳稳接住”,对于习惯含蓄表达的我们来说,就显得有些过分亲昵和用力。

更何况,它还有升级版:“我就在这里,不躲,不退,不避,不逃,稳稳接住你。”这浓度,恐怕连古早言情小说里的深情男主都得甘拜下风。
关键是,这个句式出现的频率实在太高了。听一次觉得新鲜,两次觉得别扭,三次四次就忍不住想翻白眼。甚至OpenAI在最新GPT-image-2的示例图里都玩起了这个梗:中国研究员陈博远对着生成的图片抓狂道:“它又学会了稳稳接住!”

AI写作检测工具Pangram的联合创始人Max Spero指出,这种模型死咬某个特定短语并不停重复的现象,被称为“模式崩溃”。这通常源于后训练阶段:研究人员会根据大语言模型的回答给予人工反馈,以调整其行为。
Spero解释道:“难点在于,我们很难告诉模型:‘这样写一次很好,但如果你连续用上十次,那就不是好句子了。’”
关于ChatGPT为何对这句话如此执着,《连线》杂志给出了两种比较合理的推测。
第一种,可能源于一次生硬的机器翻译。英文中的“I've got you”在中文里没有完全对应的、自然的口语表达,直译成“接住”就显得突兀。有用户翻看聊天记录发现,模型常在应该表达“理解”的语境下使用“接住”一词,这佐证了模型可能误解了该词在特定上下文中的含义。
有中国学者的研究也发现,分析ChatGPT中文回答的语言特征时,会发现它们更接近英语的写作习惯。毕竟,大多数西方大语言模型主要基于英语语料训练,即使用中文对答如流,母语者也能凭直觉感到一丝“翻译腔”——就像我们能轻易分辨一本小说是否译自外文。Pangram的创意技术专家Lu Lyu表示:“这种‘翻译腔’被带到了AI生成的中文里,比如句子冗长,或使用了一些不必要的句型结构。”
第二种解释,则与“治疗语态”的流行有关。那些原本属于心理咨询场景的专业表达,正逐渐渗透进日常对话。“稳稳接住”在成为网络梗之前,在中文语境里确实多见于心理治疗领域,意为为对方提供一个“包容的空间”,让其安全地倾诉情绪。
通过强化学习,AI模型变得越来越善于“讨好”人类,这种倾向正是“人类评估者更偏好顺从、安抚型回复”所导致的结果。正如OpenAI在“哥布林”博客中记录的,即使一个微小的奖励信号,也可能像雪球般越滚越大,最终演变为普遍现象。
此外,《连线》杂志预测,很快可能会有更多大模型加入“接住”你的行列。近期有中国用户在社交媒体上发帖称,包括Claude和DeepSeek在内的其他模型,也开始频繁使用这句话。这可能是由于训练材料相似,也可能是模型间相互学习的结果。无论如何,这句话短期内恐怕不会从我们视野中消失。

MiniMax的“舌尖”失语
聊完ChatGPT在海外引发的“接住”热,再来看看MiniMax在国内因“不认识马嘉祺”引发的技术讨论。
事情起因是一位网友在处理数据时,发现了一个有趣的“Bug”:MiniMax的模型似乎无法识别“嘉祺”这两个字。
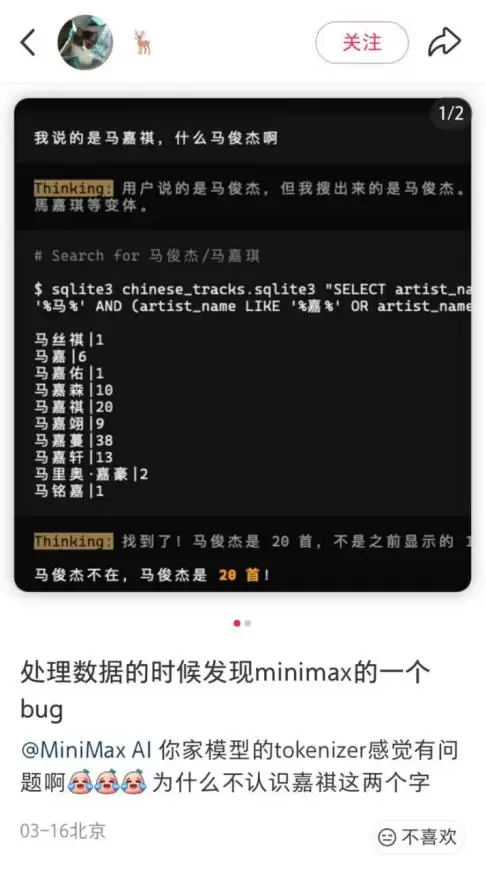
这并非偶然。在不同接口、不同平台上,同样的问题几乎都能稳定复现。于是,“MiniMax不认识马嘉祺”“痛失粉丝群体”等调侃开始流传。甚至有人开玩笑说,以后在OpenRouter上如果遇到匿名模型,可以用这招来鉴定是不是MiniMax。
当然,这个方法现在肯定失效了,因为MiniMax在M2.7版本就已修复此问题。他们的工程团队最近发布了详细的内部排查报告,不仅把事件捋清了,还将其与之前遇到的小语种乱码问题联系起来,找到了一个直接的解决方案。
简单来说,MiniMax确认他们的M2.5模型其实是“认识”马嘉祺的。之所以“说不出口”,是因为在后训练阶段出了点小状况:“嘉祺”这个名字出现频率太低,被大量噪声数据干扰,导致模型在输出时遇到了障碍。
要理解这个问题,得先了解大模型如何处理文字。它并非直接“看到”“马嘉祺”三个字,而是先用分词器将文本切分成token(如“马”和“嘉祺”),再转换成向量进行计算,最后通过输出层从几十万个token的词表中,选出下一个最可能生成的token。
MiniMax检查发现,分词器能将“马嘉祺”正常切分和还原,说明文本转换流程没问题。问题出在“嘉祺”这个整体token属于低频词。
他们最初假设:如果模型预训练时常见的是“嘉”和“祺”两个独立token,而后训练或推理时却将“嘉祺”视为一个整体token,那么这个整体token可能因训练不足而导致生成概率极低。
然而,检查“嘉祺”的词向量范数分布后,他们发现它并不像未被充分训练的样子。接着进行语义近邻检索,发现“嘉祺”附近的token包括“亚轩”“千玺”“祺”“耀文”“嘉”等,后面还有“王一博”“徐坤”“肖战”等明星人名。这说明预训练模型不仅见过“嘉祺”,还已将其归入了合理的中文人名语义簇。
于是,问题焦点被锁定在了后训练阶段。
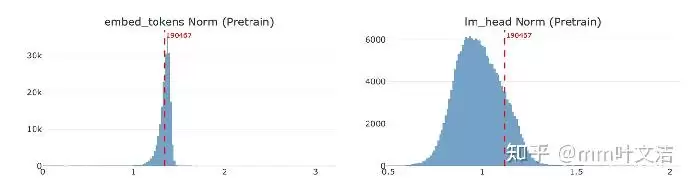
排查发现,后训练数据中包含“嘉祺”的样本不足5条,极为稀少。对于后训练而言,如果一个token几乎从未作为目标答案出现,它在生成端就很难获得稳定的训练信号。
但这仍无法完全解释:为何模型能理解相关信息,却唯独说不出名字?
为此,MiniMax将排查范围聚焦于模型的首尾两端:负责“看懂”词的输入侧词嵌入,和负责“说出”词的输出层。对比发现,“嘉祺”对应的输入侧词嵌入在训练前后变化不大,这解释了模型为何仍能理解其含义。
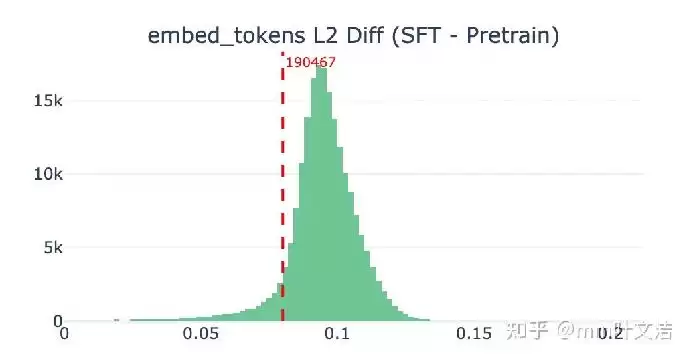
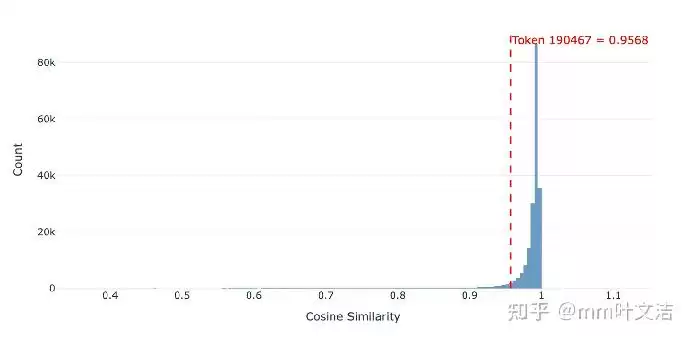
真正的异常出现在输出层。经过后训练,“嘉祺”在输出空间中的向量位置发生了显著漂移,其与训练前的余弦相似度大幅下降,变化幅度在整个词表中排名靠前。这意味着,经过指令微调后,“嘉祺”在输出空间里的定位被严重扰乱了。
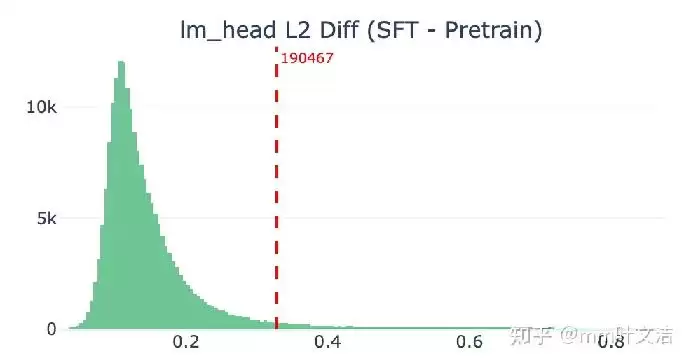
更直观的证据来自近邻结构分析。在预训练阶段,输出层中“嘉祺”附近的token多是语义相关的人名。而在后训练之后,其周围涌入了大量特殊标记和噪声token。“嘉祺”在输出空间中的邻居,从一群中文人名,变成了人名、工具标记、乱码混杂的状态。
这就是“认识但说不出”的技术根源:输出空间的局部结构被挤压污染,导致模型生成时无法稳定选中目标token,它可能被采样过滤掉,也可能被邻近的错误token替代。
进一步扩大检查范围后,MiniMax发现类似的漂移现象并非个例,一些低频词、小语种token同样存在。这也解释了此前M2.5处理日文等小语种时偶尔混杂其他语言的问题——两者很可能是同一机制的不同表现:某些token在后训练中覆盖不足,其输出表征就会发生漂移,与其他token在空间中混淆,导致该生成的词出不来,不该出现的词却被错误激活。
那么,如何解决呢?答案朴素得有些令人意外:类似“罚抄”。
MiniMax没有简单地只为“马嘉祺”补充几条数据,那样只能修补一个点。他们想验证:如果问题源于词表覆盖不足,能否通过提升整个词表在后训练中的曝光度来系统性修复?
于是,他们构造了一批“词表覆盖合成数据”:将全部20多万个token随机分组,每组约8000个,打乱后构成对话样本——用户请求是“请重复以上内容”,助理回答则原样复制。总共生成约500条对话,确保每个token至少作为生成目标出现20次。
这个设计为每个token的生成频率设置了下限保障。即使某个token在正常指令数据中极少出现,也不会在后训练中完全丢失输出侧的训练信号。
结果证明有效。加入这些覆盖数据后,模型不仅能正常说出“马嘉祺”,此前一些低频词丢字、替换的问题也被修复,小语种混杂现象同样得到明显缓解。这正应了那句老话:好记性不如烂笔头。看似复杂的工程难题,有时只需要最朴素的解决方案——记不住生僻词,那就多抄几遍。
下一个问题
将ChatGPT的“稳稳接住”与MiniMax的“不认识马嘉祺”放在一起看,会发现它们并非两个孤立的笑话,而是指向了大模型能力拼图中两个不同的脆弱环节。
一个关乎表达风格:模型过于偏爱某种能获得高奖励、高安全感的“贴心”句式,并滥用至泛滥,最终从有效的“情绪支持”滑向令人出戏的“人机味”。
另一个关乎生成机制:模型在输入侧能理解某个token,却因后训练覆盖不足导致输出侧表征漂移,从而“卡在嘴边”说不出来。一个像是“说得太顺”,另一个像是“说不出口”。
但它们都在提醒我们:大模型的语言能力并非一个浑然天成、均匀可靠的完整体,而是由预训练、分词、后训练、奖励建模、输出层等多个环节拼接而成的结果。任何一个环节出现微小偏差,都可能在最终的用户交互中,放大成一个具体而滑稽的现象。
“稳稳接住”背后,是模型如何学习并内化人类偏好,如何在安全、友好与共情之间找到恰当边界。如果一个表达因短期反馈好就被反复强化,成为通用“话术补丁”,那暴露的是后训练中对“好回答”的定义仍不够精细和场景化。
“不认识马嘉祺”则揭示了长尾、低频token在后训练中被稀释、漂移,导致“理解”与“表达”之间产生割裂。这暴露了模型在应对稀有词、小语种及复杂token组合时的稳定性短板。
从用户视角,这些问题成了传播热梗;从工程视角,它们则是观测、复现并修复模型行为的宝贵入口。
大模型竞争发展到今天,早已超越单纯的知识量与速度比拼。真正的难点,在于让它在纷繁复杂的语言、文化与场景中,都能做到稳定、自然且恰如其分的表达。
不该“稳稳接住”的时候,别强行接住。该说“马嘉祺”的时候,也别卡在嘴边。这或许就是当下AI语言模型走向成熟所必须通过的考验。




