数据库与数据仓库,两者作为数据领域的基础概念,几乎每天都会出现在技术讨论中,但真正能厘清它们差异的人并不多。不少人认为数据仓库不过是"大一点的数据库",或者觉得有了数据湖就不再需要数据仓库。这些理解其实都偏离了它们的本质。本文将从定义、核心区别、关联关系以及常见认知误区入手,系统性地为你拆解清楚,一次讲透。
一、两者各自的含义
数据库(DB),本质上是用来存储业务系统实时数据的技术,支持增、删、改、查(CRUD)操作,主要服务于各类应用程序——例如你在电商平台下单、支付时,后台的数据库必须立即响应。它的核心指标是速度快、数据准确、实时性强。
数据仓库(DW),则是一个面向分析的数据环境,专门存储经过清洗与整合的历史汇总数据。它的使用对象不是程序,而是人——数据分析师、运营人员、管理决策者,用于统计、报表、大屏展示和BI辅助决策。数据仓库更看重数据的完整性、历史可追溯性以及灵活的聚合能力。
二、核心区别
1. 用途不同
数据库的使命是支撑业务系统正常运转:订单处理、支付、库存管理、ERP、MES等,要求响应快、数据准、实时性强。而数据仓库专为统计、分析、报表、大屏和BI决策而设计,它更关注数据的全貌、历史深度和聚合能力。
2. 数据特征不同
数据库中存储的是最新、最细粒度的实时数据,且经常发生增删改操作。数据仓库中存储的是历史全量数据,按时间维度归档,通常只追加不修改——意味着你看到的数据是"过去某个时刻的定格快照"。
3. 结构设计不同
为了保证数据一致性,数据库通常采用三范式(3NF)设计,表拆分细致,冗余极少。数据仓库则相反,偏好星型或雪花模型,宽表较多,适度引入冗余——一切为了查询更快,而不是为了避免写入冲突。
4. 操作方式不同
数据库每天面对大量INSERT、UPDATE、DELETE操作,查询通常较为简单。数据仓库几乎没有删除和修改操作,取而代之的是大量复杂查询、多表关联和聚合统计——一份报表可能扫描几十亿行数据。
5. 使用人群不同
数据库的使用者主要是程序、系统接口。数据仓库的使用者是人——分析师、运营人员、管理者,他们借助BI工具或SQL客户端来获取业务洞察。
6. 数据量与时间跨度不同
数据库通常只保留近期数据(几个月到一年),因为业务系统不需要太老旧的数据。数据仓库则长期保留多年历史,三年、五年甚至全量——时间跨度越长,分析价值越大。
7. 对比表
三、关联关系
数据通常从数据库流向数据仓库,中间通过ETL(Extract, Transform, Load)作为桥梁。ETL具体包含三个环节:Extract——从多个OLTP数据库抽取原始数据;Transform——清洗、整合、计算指标(例如"年销售额");Load——将处理后的数据加载到数据仓库的维度模型中。
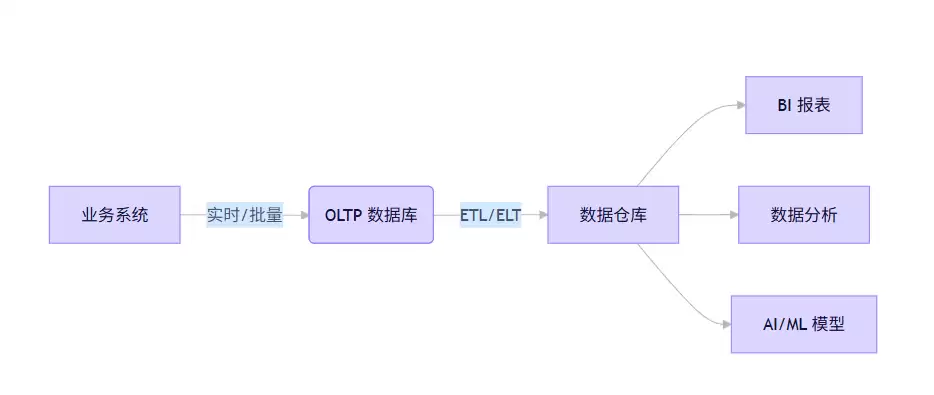
四、常见误区
❌ 误区1:"数据仓库就是大一点的数据库"
这个说法完全偏离了本质。两者的设计哲学截然不同:数据库是写优化(Write-Optimized),而数据仓库是读优化(Read-Optimized)。简单来说,一个只管高效写入、避免冲突;一个只管快速读取、支持复杂分析。拿跑车的引擎去拉货,结果只能是两败俱伤。
❌ 误区2:"有了数据湖就不需要数据仓库了"
并不准确。数据湖擅长存储原始数据(包括结构化与非结构化),适合探索性分析;数据仓库则存储经过清洗的结构化数据,适合固定报表和日常运营分析。两者各有所长,因此如今越来越多的企业采用Lakehouse架构,将湖和仓融合使用,实现优势互补。
❌ 误区3:"直接在业务库上跑报表没问题"
这种做法风险极高。复杂报表容易引发锁表、拖慢核心业务,而且历史数据可能已被业务库归档或删除。必须将OLTP(在线事务处理)与OLAP(在线分析处理)分离开来,让专业系统干专业的事。




