本文大纲
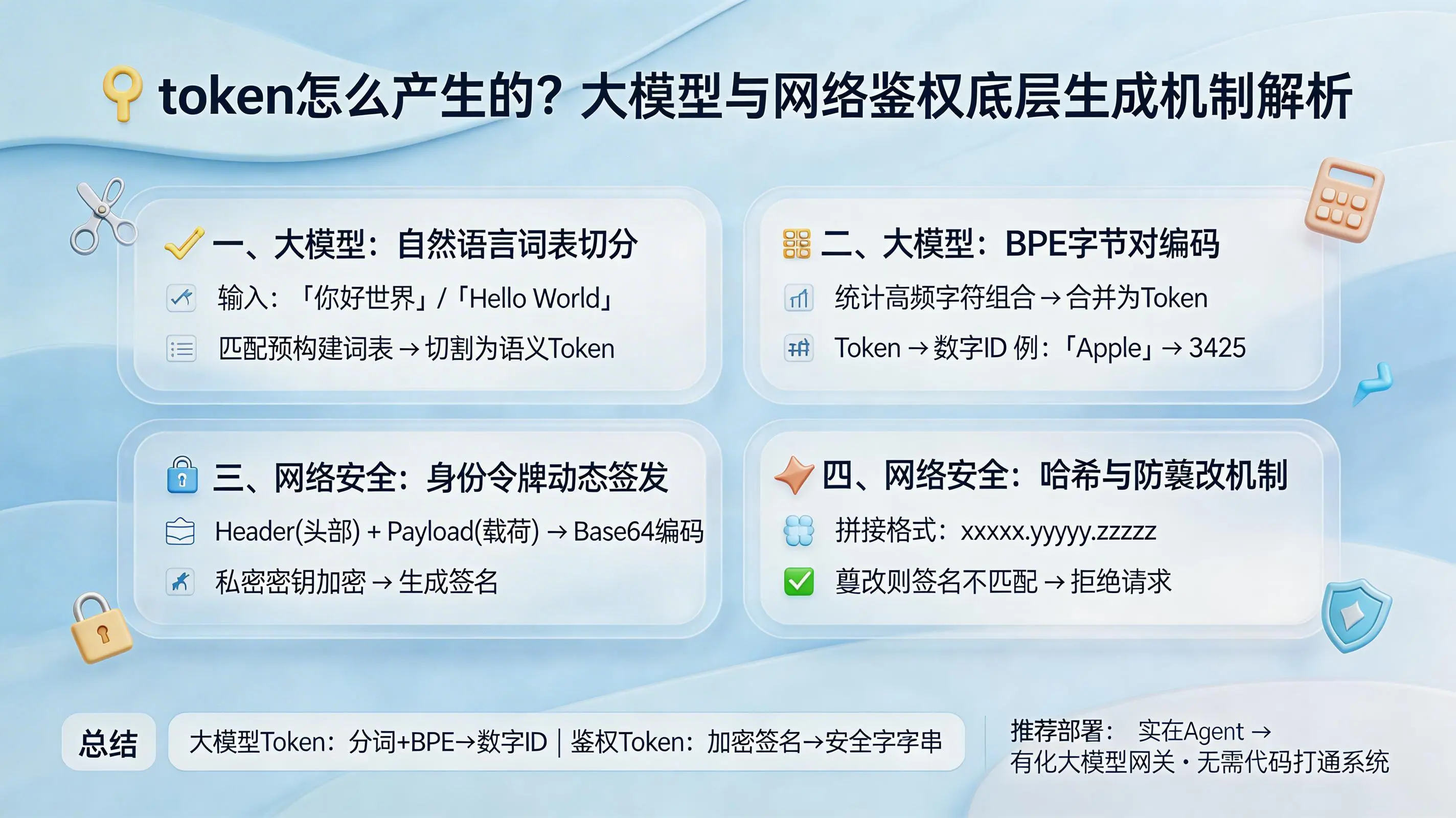
一、大模型领域:自然语言的词表切分(Tokenization):如何将句子变成可计算模型?
二、大模型领域:BPE算法与字节对编码:统计学视角的切词与数字映射
三、网络安全领域:身份令牌的动态签发(Sign):如何将用户信息加密成凭证?
四、网络安全领域:哈希与防篡改机制:保障服务端信任的底层组装原理

图源:AI生成示意图
一、大模型领域:自然语言的词表切分(Tokenization)
当人工智能需要“理解”一句话时,第一步就是如何将流畅的人类语言,转换成机器能直接处理的“原料”。这个过程,靠的就是一个叫做“分词器”的专门程序。
流程并不复杂:你向模型输入一段文字,无论是“Hello World”还是“你好世界”,分词器就开始工作了。它手里有一份模型训练前就准备好的、庞大的“词典”。接着,它会将你输入的字符序列与这本词典进行比对,把整个句子切割成一个个带有具体语义的“数据切片”。这就是Token最初始的形态。

图源:AI生成示意图
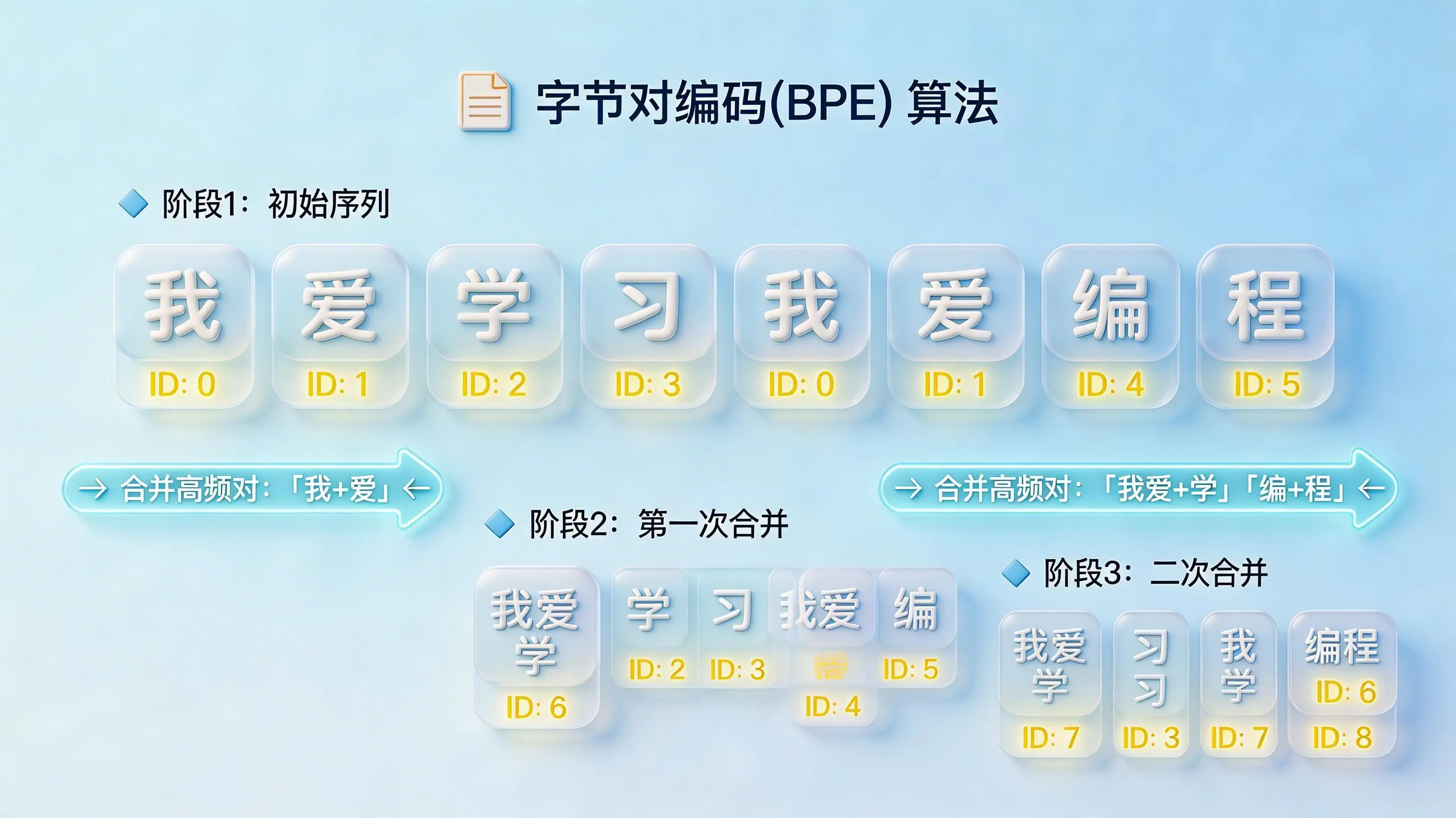
二、大模型领域:BPE算法与字节对编码
那么,具体怎么切才算合理?这就轮到算法登场了。目前,绝大多数主流大模型采用的是一种名为BPE的算法。它的原理颇具智慧。
简单来说,BPE算法就像一位语言统计学家。它会先分析海量的文本语料,统计出哪些字符组合出现的频率最高。频率越高的组合,比如常见的单词或中文词汇,就越容易被定义为一个独立的Token单元。完成切分后,分词器便会将每一个Token映射到词典中对应的、唯一的整数ID上。于是,“苹果”可能就变成了3425这个数字。
这才是关键所在:大模型底层的神经网络,实际上并不认识文字,它们只认识这些数字ID。后续所有的复杂计算与推理,都是基于这些数字进行的矩阵运算。理解这个过程,不妨打个比方:人类输入拼音字母,分词器负责把字母组合成正确的音节(词语),并从一本大字典里查出每个音节对应的页码(数字ID),最后把这些页码打包,发送给模型进行“阅读”。
图源:AI生成示意图
三、网络安全领域:身份令牌的动态签发(Sign)
说完了大模型里的“语义切片”,我们再把视线转向另一个重要场景:网络身份鉴权。这里的Token,比如最常见的JWT,其诞生过程充满了动态与安全的考量。
它并非预先存在,而是由服务器在验证用户身份后,通过加密算法实时生成。过程可以分为两步:首先是“组装”。服务器会把声明加密类型的“头部”,以及包含用户ID、有效期等信息的“载荷”,分别转换成一种标准的Base64编码格式。接下来,才是赋予其灵魂的一步——加密签名运算。
四、网络安全领域:哈希与防篡改机制
安全Token的生成,远不止是编码那么简单,其核心价值在于构建一道可靠的“防伪护城河”。
服务器会使用一个只有自己知道的密钥,配合特定的哈希算法,对前面组装好的编码内容进行一次性、不可逆的加密运算,生成一段独一无二的“数字签名”。最终,服务器将编码后的头部、载荷和这个签名,用英文句点.拼接起来,就形成了我们熟悉的那串xxxxx.yyyyy.zzzzz样式的Token字符串。
需要警惕的是,这串Token下发后,任何人如果试图私自篡改其中的用户信息,都会在验证时立刻暴露。因为服务器在下次收到Token时,会用相同的密钥重新计算一次签名。一旦发现计算出的签名与Token中携带的签名对不上,就会在物理层面果断拒绝这次请求。这就从根本上杜绝了越权操作的可能。
总结
可以看到,Token在不同领域扮演着截然不同却同样关键的角色。在人工智能的大模型里,它是由分词器通过BPE算法精心切割、并映射为数字ID的“语义单元”,是模型理解世界的基石。而在网络安全的疆域,它则是服务器通过组合信息、加密签名动态生成的“安全凭证”,是守护数字身份与权限的钥匙。
理解这两套底层的产生逻辑,不仅能让我们更清晰地透视系统间通信的脉络,也能更深刻地把握大模型算力流转的起点。对于希望将底层算力与复杂接口直接转化为业务生产力的企业而言,选择一款能够原生融合主流大模型、并提供安全私有化部署的智能平台,无疑是构建下一代数字劳动力的高效路径。
图源:AI生成示意图




