商汤科技刚刚正式发布并开源日日新SenseNova U1 系列原生理解生成统一模型

商汤科技这次的动作,可以说是为多模态AI领域投下了一枚“深水冲击波”。他们正式开源了日日新SenseNova U1系列模型,而它的核心,在于一个根本性的架构革新。
这个模型基于商汤今年三月自主研发的NEO-unify架构。关键在于,它彻底摒弃了当前主流的“拼接式”思路,拿掉了视觉编码器和变分自编码器这些传统组件,转而重新构建了一个统一的表征空间。这个空间不是简单的模块拼接,而是深入融入了模型的每一层计算之中。这意味着什么?意味着多模态AI从过去的“模态集成”范式,真正迈向了“原生统一”的新阶段。
业内首创连续性图文创作输出
凭借NEO-Unify架构的先天优势,SenseNova U1实现了一项业内首创的能力:连续性的图文创作输出。更关键的是,它只需要单次调用一个模型,就能输出质量更高的作品。相比过去那种需要多个模型接力协作的传统范式,效率的提升可不是一星半点。
这种原生统一的图文理解生成能力,其精髓在于能将图像和文本的底层融合信号,完整地保留在上下文之中。这与过去那种靠多模型串联、勉强实现功能的方式有本质区别。带来的直接好处就是,它生成的图像之间,风格具备极高的连贯性。因为所有的“思考”都在同一个表征空间里高效、连贯地进行。
举个例子,如果你让它分步骤讲解五分熟牛排的做法并配图,SenseNova U1能够自己进行思考和规划,生成分步的过程,并为每一步输出对应的图像。你会发现,各个步骤的图示在风格、细节处理上表现出惊人的一致性。

再比如,让它从一张钢铁侠的草稿出发进行绘制:它能逐步进行连续创作,最终输出完成度很高的图像。每一步创作都精准地保持了前一步的结构与细节——这其中,统一表征所共享的上下文发挥了关键作用。
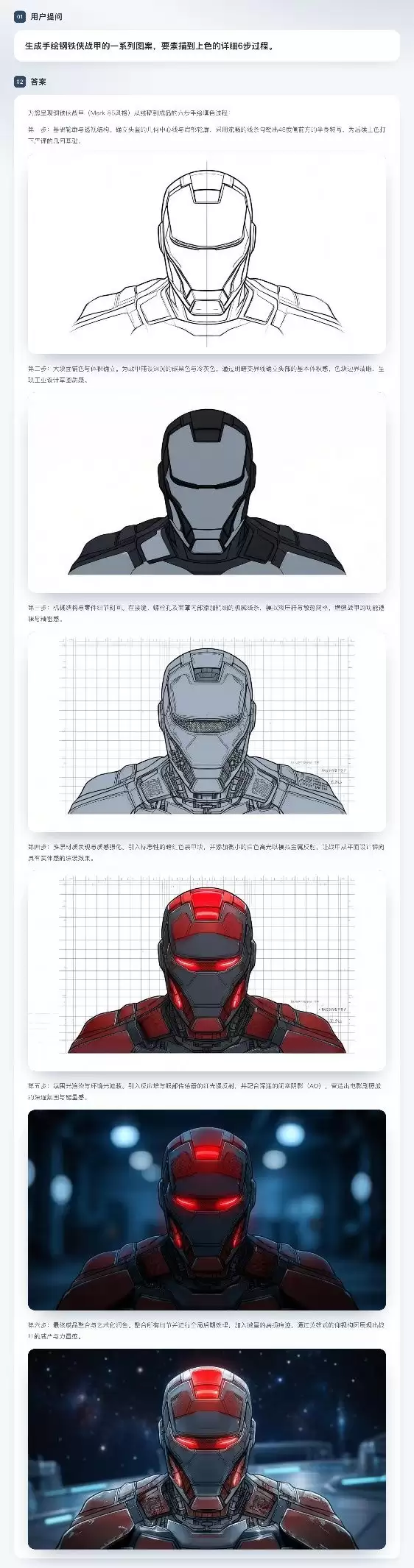
本质上,SenseNova U1系列模型是将语言与视觉信息作为一个统一的复合体直接进行建模。这种高效协同,让模型的理解与生成能力同步增强,在保留丰富语义的同时,还能维持像素级的视觉保真度。
在逻辑推理与空间智能等需要深度理解物理世界复杂布局与精细关系的方向上,它展现出了巨大潜力。展望未来,这类模型甚至能为机器人提供“具身大脑”,实现在单一模型闭环内,完成从复杂环境感知、逻辑推演到精准任务执行的全过程。这无疑是为推动相关技术与产业发展,提供了重要的基础与关键引擎。
极致高效,以小搏大
本次开源发布的是SenseNova U1的轻量版系列——SenseNova U1 Lite。它包含两个不同规格的模型:
• SenseNova-U1-8B-MoT:基于稠密骨干网络
• SenseNova-U1-A3B-MoT:基于混合专家(MoE)骨干网络
效率,是这种统一模型架构最核心的技术优势。我们可以打个比方来理解其中的差异。
传统的多模态模型,就像把视觉编码器和语言骨干通过适配器“拼接”在一起。这好比一个“说不同语言的人组成的工作组”:有人专门看图,把图像翻译成语言;有人专门理解文字,进行推理;还有人把结果再翻译成设计指令,把图画出来。每完成一次任务,信息都要在不同成员之间来回传递、转译。这个过程虽然能走通,但难免存在等待、误解和信息损耗。为了弥补这些损耗,模型往往需要做得更大、参数更多,才能达到理想效果。
而SenseNova U1基于统一表征空间构建,更像是一个从一开始就同时掌握多项技能的“全能大脑”。它不是先看懂图像、再翻译成文字、再交给另一个系统理解,而是在同一套“思维体系”里直接处理图像、文字等所有信息。图像和语言不再是两套系统之间的接力赛,而是在同一个大脑中自然融合、协同思考。
这样带来的好处显而易见:信息流转路径极短,理解更直接,生成更高效。模型不再需要依赖单纯堆叠参数来弥补中间转换的损耗,而是通过统一的内部表征,把不同模态的信息以更紧凑、更高密度的方式组织起来。简单说,传统架构是“多人协作、层层转述”;SenseNova U1则是“一个全能大脑,直接理解,直接表达”。少了中间转译环节,信息损耗自然更低,也就能在相对更精简的模型规模下,实现更强的多模态理解与生成能力。
事实也证明了这一点。在涵盖图像理解、图像生成与编辑、空间智能和视觉推理的多项基准测试中,SenseNova U1 Lite均达到了同量级开源模型的SOTA(顶尖)水平,为统一多模态理解与生成树立了新标杆。甚至仅凭8B-MoT的较小规格,其性能就能达到甚至超越部分大型商业闭源模型,展现出全维度、多领域的强大竞争力。
下面的实际例子,就直观展现了SenseNova U1 Lite的商业级复杂信息图生成能力。
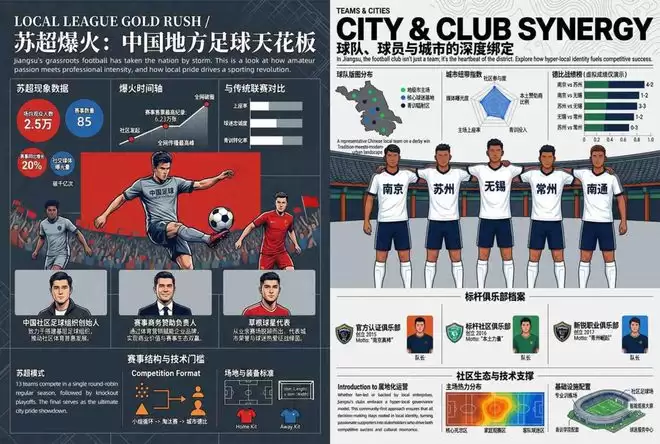

商汤正沿着这条技术路径继续推进模型规模化(Scale),计划在未来推出体量更大的模型。他们的信心在于,基于这种高效的原生统一架构,完全有可能以低得多的计算成本,达到国际顶尖模型的性能水平。
全网开源,即刻可用
目前,模型已全面开源,开发者可以立即上手体验:
开源部署
• GitHub:https://github.com/OpenSenseNova/SenseNova-U1
• Hugging Face:https://huggingface.co/collections/sensenova/sensenova-u1
同时,欢迎调用SenseNova U1 Skill(https://github.com/OpenSenseNova/SenseNova-Skills),浏览海量样例库并获取Prompt编写指南。这能帮助你化繁为简,轻松将复杂的文本描述转化为精美的信息图表,让你的智能体(Agent)快速成为信息图生成高手。




