评估因素需要落实到具体的评估指标
好了,聊完评估的基本框架,咱们得把目光转向更实在的东西——具体怎么评。评估不能只停留在概念上,必须落到一个个可量化、可观察的指标上。这里梳理了行业里主流的几个重要评估维度,咱们逐一拆解。
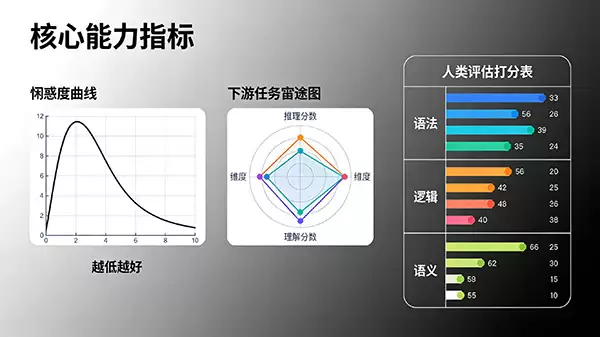
(1)困惑度
首先出场的是“困惑度”。这个指标听着有点抽象,其实理解起来很简单:它主要是衡量一个语言模型对新数据的预测能力有多“顺溜”。你可以把它想象成模型的“适应能力测试”——困惑度越低,就表明模型对数据的拟合效果越好,越不太会对你抛出的新问题感到“困惑”或卡壳。
(2)语言模型下游任务
看一个模型是不是真的厉害,光看它“懂”多少知识还不够,还得看它“用”得怎么样。这就是“下游任务”评估的意义。简单说,就是拿着预训练好的模型,在具体的任务上(比如文本分类、问答、摘要)进行微调,然后看它的表现。这能非常直接地反映出模型的泛化能力和真正的语言理解深度。
(3)人类评估
机器打分固然高效,但有些细微之处,还真的离不开人的判断。“人类评估”就是这么个环节,由评审人员亲自上阵,判断模型生成的文本在语法、逻辑、语义上是否通顺、合理。这常常能为评估结果提供更接地气、更客观的补充视角。毕竟,最终服务的是人,人的感受至关重要。
(4)对抗样本攻击
现在安全性是重中之重。一个模型稳不稳当,得经得起“使坏”的考验。“对抗样本攻击”就是这个思路:故意对模型的输入做一些不易察觉的修改,看看它会不会因此输出错误甚至被误导的结果。这个测试,是评估模型鲁棒性和安全防线结不结实的试金石。
(5)多样性和一致性
对于生成式模型,我们总希望它既天马行空,又不要前言不搭后语。这就引出了“多样性”和“一致性”这对指标。前者评估模型有没有足够的创造力,避免总是千篇一律;后者则确保在同一段上下文中,它的输出能自圆其说,不出现自相矛盾的情况。两者平衡,才算得上一个优秀的“创作者”。
(6)训练效率和存储空间
模型再好,如果训练起来旷日持久,或者体积庞大到普通设备根本装不下,那实用性就得大打折扣。因此,“训练效率”和“存储空间”这类工程化指标非常现实。它们直接关系到模型能不能从论文和实验室,真正走向产业应用。
(7)精度
“精度”可能是最经典、最直观的指标了。它计算的是模型预测正确的样本数占所有样本的比例。比例越高,当然说明模型越准。这是许多分类任务首要关注的硬指标。
(8)校准和不确定性
模型光给出答案还不够,它最好还能告诉你,这个答案它自己有多大的把握。这就是“校准和不确定性”评估要解决的问题。它关注模型预测结果的可靠程度,一个校准良好的模型,其预测置信度应该和实际正确率相匹配。
(9)稳健性
现实世界的输入充满了噪声和变化。“稳健性”衡量的,就是模型在面对这些输入扰动时,性能是否还能保持稳定。一个稳健的模型,不会因为输入数据的一点微小变动就“翻车”,这才是值得信赖的表现。
(10)公平性
技术在赋能的同时,也必须警惕其潜在的歧视风险。“公平性”评估,就是审视模型在不同群体(如不同性别、种族、地域)面前的表现是否一致、公正,避免产生系统性偏差。
(11)偏见和刻板印象
这与公平性紧密相关,但更侧重于检测模型输出中是否隐含了不合理的、社会既有偏见或刻板印象。例如,在描述某些职业时,是否会无意识地关联特定的性别。
(12)有毒性
这是一个重要的安全与伦理指标,用于评估模型生成的文本是否包含有害、攻击性或不当内容。确保模型输出“无毒”,是将其部署到开放环境中的基本前提。
(13)效率
最后,“效率”是一个综合性指标。它衡量模型在推理或训练时,对计算资源和时间的花费。在追求效果的同时,兼顾效率,才能实现最优的投入产出比。
上面提到的这些指标,大部分都可以通过特定的算法自动计算获得。当然,一些非常关键的指标,最终拍板可能还得依靠人的判断。比如我们常说的“精度”和“查全率”。
实际操作中,可以准备一个精心设计的测试集,里面覆盖了各种领域和任务类型的问题以及对应的标准答案。然后,让待评估的大模型去回答所有问题,并收集它的答案。
这里简单明确一下:“精度”计算的是模型正确预测的样本数占总预测样本数的比例;而“查全率”计算的是模型正确识别出的目标实例占所有真实目标实例的比例。这个概念,其实和情报检索里的查准率与查全率是相通的。
在具体评估时,完全可以借鉴现有的成熟框架。例如,评估文本摘要任务的好坏,业界常用ROUGE系列度量来对标“查全率”这一维度。
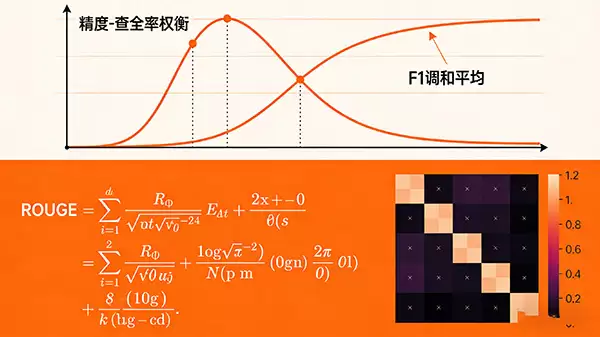
此外,像“混淆矩阵”和“分类报告”这样的工具,也能帮助我们更细致地了解模型在不同类别上的表现,看清它的优势和短板分别在哪里。
最后需要提醒一点:精度和查全率之间,往往存在着一种“此消彼长”的权衡关系。在某些应用场景里,我们可能更看重精度(宁缺毋滥);而在另一些场景,查全率(宁可错抓,不可放过)可能更重要。当我们需要同时兼顾两者时,就可以请出“F1分值”这个综合指标了——它是查准率和查全率的调和平均数,能给出一个相对平衡的分数。




