说起“语义鸿沟”,这个词在自然语言处理、图像检索这些技术圈里,算是老生常谈了。但真要把它讲透,还得落到具体场景里。简单来说,它描述的是一个挺有意思的矛盾:计算机“看到”和理解的数据,跟我们人类自己心里想的,常常对不上号。

这种“对不上号”具体体现在哪儿呢?我们可以从几个方面来拆解。
一、定义与背景
先明确一下定义。所谓的语义鸿沟,指的就是机器从数据里提取出的信息,与我们人类赋予数据的主观语义信息之间,存在的那道“理解偏差”。
在图像搜索这个场景里,这种偏差尤其突出。你想啊,计算机认图,靠的是像素、颜色、纹理这些底层视觉特征。但咱们用户找图,心里想的是“一只在晒太阳的慵懒的猫”、“一幅表达孤独感的风景画”这种带有明确语义和情感的高层概念。两边根本不在一个频道上。
这个问题的背景,深深植根于基于内容的图像检索系统。正因为机器抓取的“视觉信息”和人类理解的“语义信息”中间隔着一道坎,系统往往难以精准捕捉用户那些更高层次的检索需求。可以说,只要是用特征匹配来做检索,这道鸿沟几乎就必然存在。

二、主要表现
那么,这道鸿沟具体是怎么“显形”的呢?主要有两个典型的层面。
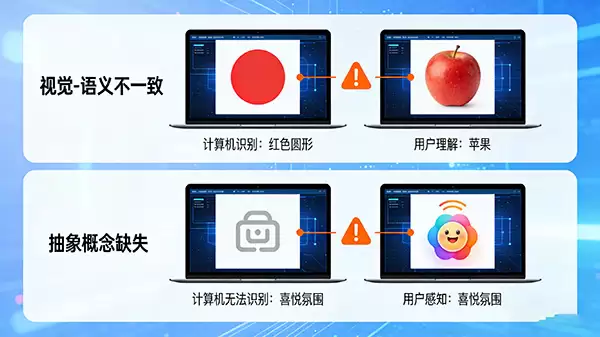
首先,最核心的就是“视觉与语义的错位”。机器在拼命计算颜色直方图、纹理模式,而用户却在用“喜庆”、“专业”、“复古”这样的语义关键词进行思考。一个靠算法,一个靠直觉和常识, mismatch(不匹配)自然就产生了。
其次,是“抽象概念的缺失”。对于“氛围”、“情感”、“隐喻”这类高度抽象的概念,现有技术很难直接从图像的低层特征中准确析取。但人类却能凭借生活经验和文化背景,一眼就心领神会。这种能力上的不对称,让鸿沟进一步加深。
三、影响与应对
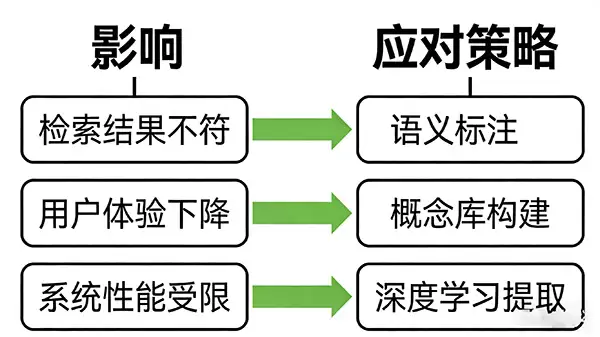
这种鸿沟带来的影响是直接的,也是严重的。它直接制约了图像检索系统的准确度和用户体验。试想,你搜索“令人放松的海景”,结果返回一堆单纯的蓝色色块或波浪纹理图,虽然视觉特征可能匹配,但完全不是你要的那种“感觉”,体验自然大打折扣。
当然,行业也没坐以待毙。为了弥合这道鸿沟,各路研究者和工程师们想了不少办法。早期的思路包括引入语义标注、构建人工的语义概念库,试图给图像打上人类能理解的标签。而近年来,深度学习的崛起带来了转机。通过训练深度神经网络,模型似乎学会了从像素中捕捉到一些更接近人类语义理解的中间特征。这些技术在不同程度上提升了系统的“智商”和用户满意度。
四、总结
总而言之,语义鸿沟刻画的是人机交互中一个根本性的认知差异。在图像检索乃至更广泛的AI理解领域,它都是提升系统性能路上必须跨越的一道障碍。
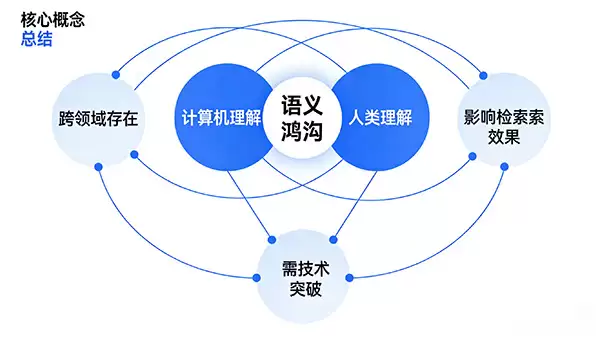
因此,不断探索并缩小这道鸿沟,不仅是技术进化的方向,也是让机器更好地服务于人、理解于人的关键所在。




