一、定义与原理
开门见山地讲,多模态识别听着复杂,其实内核很直观。它本质上是一种“感官集成”的识别策略——通过整合来自图像、语音、文本乃至触感等不同来源的数据,让机器能像人类一样,综合多种线索去做判断和分类。这不仅是为了更准确,更是为了更全面地理解我们身处的这个复杂世界。
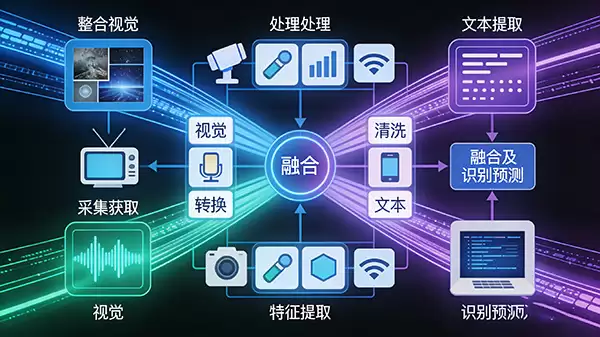
那么,这套技术是如何运作的呢?其骨架建立在数据融合与机器学习之上。简单来说,过程分三步走:首先,通过各种传感器或数据通道获取原始的多维信息;接着,用算法对这些信息进行清洗、提炼特征,并将它们巧妙地融合起来;最后,交由分类或预测模型进行最终的识别决策。这就好比一位经验丰富的侦探,不会只听片面之词,而是综合所有现场证据,再做出最可靠的推断。
二、应用领域
理论听上去不错,那它具体能用在哪儿?答案几乎无处不在。
先说生物识别。单靠指纹或人脸,在极端环境下都可能“失灵”。而多模态识别将指纹、人脸、虹膜、声纹等特征组合起来,安全性立刻上了一个台阶。你手机上的面部解锁加指纹支付,就是这套思路最贴近生活的体现。

在人机交互领域,它的作用更是革命性的。计算机不再只是呆板地接收指令。语音助手能听懂你的话并作出回应;摄像头能识别你的手势和姿态,让你“隔空”操控设备。交互方式从此变得自然又丰富。
医学诊断同样受益良多。面对复杂的疾病,单一检查报告往往有局限。多模态识别可以把CT、MRI影像,与血液检测等生化数据、临床观察结合起来,为医生提供一个立体的“病情拼图”。尤其在肿瘤诊断中,这种综合视角的价值不言而喻。
而在自动驾驶这个风口上,多模态识别堪称系统的“眼睛”和“耳朵”。车辆通过融合摄像头、雷达、激光雷达的数据,能构建出对周围环境360度无死角的精确感知。这是确保行车安全、实现可靠自动驾驶的基石。
三、优势与挑战
优势显而易见:准确性更高,系统更稳健,交互方式也更多元。通过整合多源信息,系统能更好地应对单一信息缺失或被干扰的窘境,理解能力也更为全面。
然而,真正的挑战往往与机遇并存。如何高效地整合格式迥异、质量不一的数据,本身就是一个难题。随之而来的模型复杂度的飙升,对算力提出了苛刻要求。更别提在自动驾驶这类场景中,还得保证所有处理都能实时完成。这些都是摆在业界面前,需要持续攻坚的堡垒。

四、发展趋势
展望未来,多模态识别的发展轨迹与人工智能、大数据、云计算等技术的进步深度绑定。可以预见,更智能、更高效、更“润物细无声”的应用将渗透到生活与工作的方方面面。
但同时,也需要清醒地认识到,前方那些关于数据融合、模型优化与实时性的挑战不会自动消失。行业的持续健康发展,恰恰依赖于对这些核心问题的不断探索和攻克。唯有如此,惊喜才能真正转化为扎实可靠的进步。





