FlowAct-R1是什么
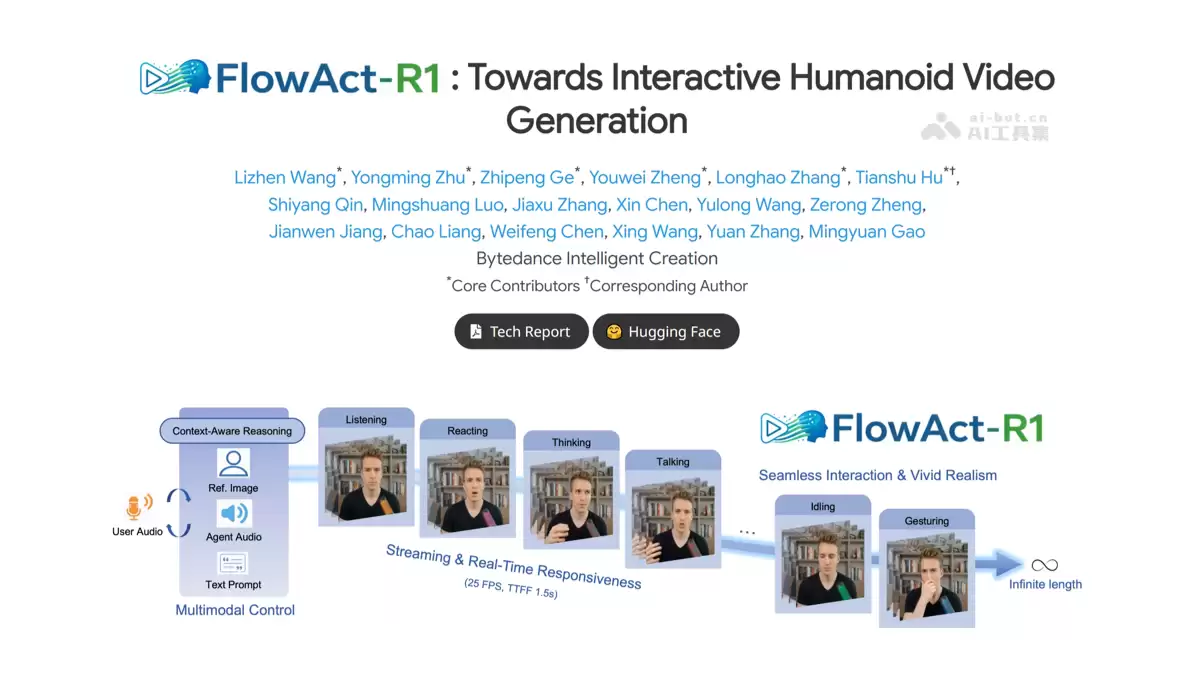
数字人视频生成,一直追求更自然、更实时。现在,字节跳动推出的FlowAct-R1框架,把这个目标又向前推进了一大步。这个框架只需要一张参考图片和一段音频,就能流式生成无限时长的全身动态视频。想象一下,一个数字人角色能够实时响应你的语音,通过独特的分块扩散策略和多模态大模型“大脑”来驱动,实现1.5秒内快速出第一帧画面,并以25fps的帧率稳定输出。无论是微妙的点头、思考时的眼神,还是配合语义的手势,它都能细腻呈现。这意味着它能轻松驾驭从视频会议、虚拟陪伴到直播互动等多种场景,而且不挑角色风格,写实、动漫或艺术画风都能驾驭。
FlowAct-R1的主要功能
那么,这个框架具体能做什么?几个核心功能勾勒出了它的能力边界:
- 实时交互与无限时长生成:告别传统生成式模型的片段限制。只需一张图和你的声音,它就能源源不断地生成流畅的全身视频,长时间运行也不会出现脸部崩坏这类恼人的问题,稳定性值得信赖。
- 低延迟与高帧率:交互感的核心是即时反馈。1.5秒的首帧延迟和25fps的稳定输出,让数字人的反应几乎与语音同步,这让它在视频会议或直播连麦等对实时性要求苛刻的场景中,显得游刃有余。
- 全身动作与表情控制:生动的关键在于细节。框架能通过多模态指令,精细操控面部表情(如倾听、思考)和丰富的肢体动作(如手势),让数字人的交互告别机械感,变得更加真实可信。
- 强大的泛化能力:它不是一个只能驱动特定模板的“特型演员”。从一张简单的参考图出发,无论是真实的人物照片、二次元动漫形象,还是独特的艺术画风角色,它都能成功驱动,这种灵活性大大扩展了其应用范围。
FlowAct-R1的技术原理
功能强大的背后,是一系列精妙的技术设计在支撑。理解这些,就能明白它为何与众不同。
- 流式生成与无限时长:实现“无限时长”的秘诀在于分块扩散强制策略。简单来说,它把连续视频切割成块逐块生成,并利用一个结构化的记忆库来确保块与块之间的画面连贯无缝,从而在理论上支持永无止境的生成。
- 实时性能优化:要达到真正的实时,性能瓶颈必须突破。框架采用了多阶段蒸馏技术,将原本耗时的扩散模型去噪步骤大幅压缩到仅需3步。再结合FP8量化和算子融合等底层优化,显存读写开销被显著降低,最终才炼成了480p分辨率下25fps的实时生成能力。
- 全身控制与行为规划:如何让动作自然合理?框架引入了一个多模态大语言模型充当“中枢大脑”。这个“大脑”会根据语音内容和上下文,主动判断数字人此刻应该做出倾听、赞同还是思考等动作,实现细粒度的行为规划,从而彻底消除预先编程的机械感。
- 高保真视觉效果:快的同时,画质不能妥协。通过优化的模型架构与训练策略,框架在生成过程中始终维持着高保真的视觉效果,确保不同风格的角色在各种场景下都能有高质量的表现。
FlowAct-R1的项目地址
对技术细节感兴趣?想亲自探索一番?可以直接访问以下资源:
- 项目官网:https://grisoon.github.io/FlowAct-R1/
- arXiv技术论文:https://arxiv.org/pdf/2601.10103
FlowAct-R1的应用场景
综合来看,这项技术将在多个领域打开新的可能性:
- AI直播:打造一个永不疲倦、实时互动的虚拟主播,支持24小时不间断直播,并能灵活切换语言和风格,极大地提升观众的参与感和新鲜度。
- 视频会议:你可以用一个更佳状态的数字形象参会,它能提供自然的肢体语言和实时互动,甚至结合多语言翻译,让跨语言沟通的会议也能充满“临场感”。
- 虚拟陪伴:生成一个高度个性化的虚拟伴侣,提供情感支持与互动娱乐,满足人们对于陪伴和社交的深层需求。
- 在线教育:化身虚拟教师,用生动的表情和肢体动作辅助教学,提供个性化的辅导反馈,并能轻松支持多语言教学场景。
- 客户服务:作为虚拟客服,它可以实时、准确地解答用户问题,提供多语言支持,7x24小时在线,有效提升服务效率和客户满意度。




