Step3-VL-10B是什么
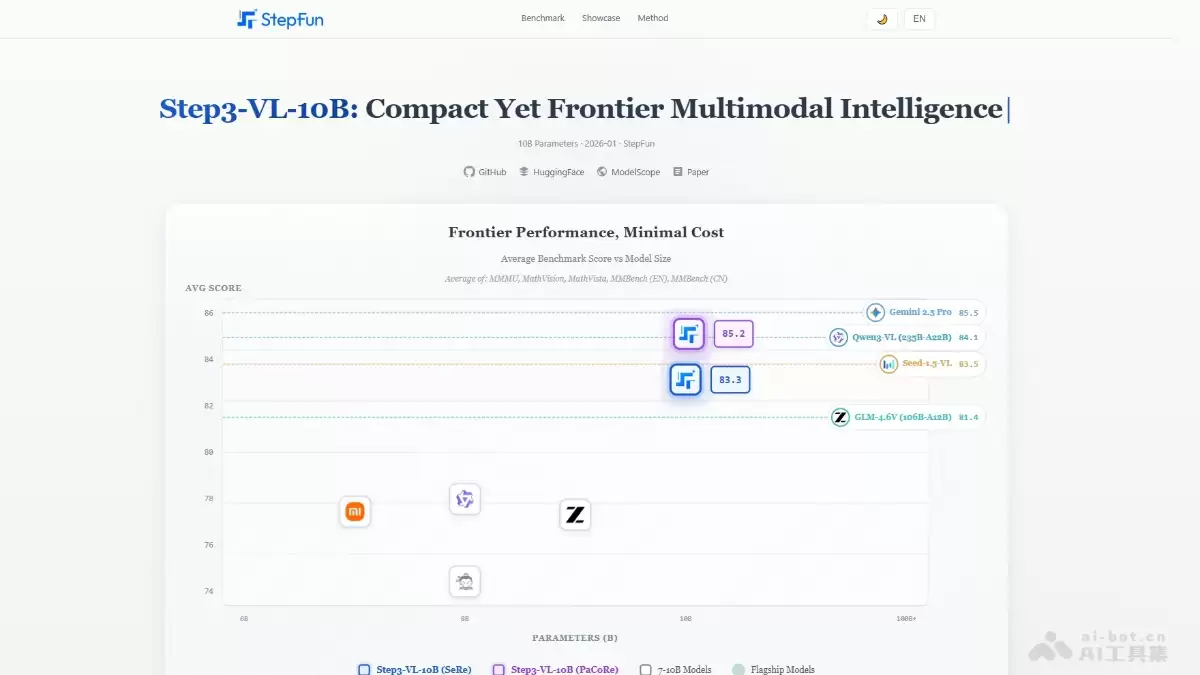
聊聊最近在开源社区里掀起不小波澜的一个模型——Step3-VL-10B。通常来说,参数规模是衡量模型能力的一个重要标尺,但阶跃星辰这次推出的这款模型,有点“打破常规”的意思。它虽然只包含了100亿参数,是个相对轻量级的选手,但在视觉感知、逻辑推理乃至数学竞赛等一系列严苛的基准测试中,其综合表现竟然能对标那些参数量高达2000亿的“庞然大物”。
这背后可不是简单的运气。模型采用了全参数端到端的多模态联合预训练,让视觉和语言从一开始就在底层语义上深度握手。更值得一提的是它那套并行协调推理机制(PaCoRe),让模型在遇到复杂计数、高精度OCR或刁钻的空间推理问题时,能像团队协作一样,并行探讨多种可能性,再汇总证据得出最佳判断。当然,最吸引开发者的,莫过于其彻底的开源策略。这意味着,将强大的多模态推理能力部署到手机、平板等终端设备上,成本门槛被大幅拉低,人机交互的体验变革,或许就此加速。
Step3-VL-10B的主要功能
那么,这个“小身材大能量”的模型,具体能干什么?我们来盘一盘它的几项看家本领。
- 极致视觉感知:千万别小看它的“眼力”。无论是图中密密麻麻需要统计的物体数量,还是文档里模糊扭曲的印刷字体(高精度OCR),亦或是理解物体之间的空间拓扑关系,它都能处理得相当精准。这套视觉基本功,相当扎实。
- 深层逻辑推理:光会“看”还不够,关键得会“想”。模型擅长进行多步骤的、链条式的逻辑推演。所以,无论是解开一道复杂的数学竞赛题,理解编程环境的上下文,还是破解视觉逻辑谜题,它都能展现出超越参数规模的推理深度。
- 端侧交互能力:这可能是迈向实用化最关键的一步。模型能够精准识别并理解图形用户界面(GUI)上的各种元素,这意味着它非常适合作为端侧智能体的“大脑”。在手机、电脑等设备上实现自然、高效的交互,不再是遥远的构想。
- 多模态推理:它的核心优势就在于融合。能够无缝衔接视觉信息与语言指令,完成像视觉问答、复杂文档解析这类需要跨模态理解的任务,真正实现了“眼脑并用”。
- 高效代码生成:在真实的编程环境中,它同样是一把好手。能根据需求生成高质量、可运行的代码片段,应对动态编程任务,为开发者提供切实的助力。
Step3-VL-10B的技术原理
功能如此亮眼,背后的技术支撑必然有独到之处。Step3-VL-10B的成功,可以归结为几步关键的“组合拳”。
- 全参数端到端多模态联合预训练:传统多模态训练往往“分而治之”,先单独训练视觉模块再拼接。它则反其道而行,在高达1.2万亿token的高质量图文数据上,进行视觉编码器和语言解码器的全参数、端到端联合训练。这种方式让视觉特征与语言逻辑在模型最底层就实现了深度对齐,根基更牢。
- 大规模多模态强化学习:预训练打下基础,精细化打磨则靠强化学习。模型经过了超过1400轮的迭代优化,针对视觉识别、数理逻辑、对话生成等具体任务表现进行定向加强,从而将潜力充分释放出来。
- 并行协调推理机制(PaCoRe):这是推理阶段的“秘密武器”。面对复杂问题,模型能动态分配算力,并行生成多个可能的感知假设,再从不同维度收集证据进行协调与聚合。这种机制显著提升了在模糊或复杂场景下的决策准确性。
- 高效的架构设计:在模型结构上,它精选了PE-lang视觉编码器(18亿参数)与成熟的Qwen3-8B解码器进行组合,辅以多裁剪策略和高效的投影层。在控制总参数量的前提下,最大化地平衡了视觉处理与语言生成的能力。
- 多阶段训练策略:整个训练流程设计精密,环环相扣:从海量数据预训练,到特定任务的监督微调(2260亿token),再到持续的大规模强化学习迭代。这套组合策略确保了模型卓越的泛化能力和最终的性能高度。
Step3-VL-10B的项目地址
对于想要深入了解甚至亲手尝试的开发者,所有的资源都已公开。以下是核心的项目入口:
- 项目官网:https://stepfun-ai.github.io/Step3-VL-10B/
- GitHub仓库:https://github.com/stepfun-ai/Step3-VL-10B
- HuggingFace模型库:https://huggingface.co/collections/stepfun-ai/step3-vl-10b
- arXiv技术论文:https://arxiv.org/pdf/2601.09668
Step3-VL-10B的应用场景
拥有这样一套能力组合,其应用前景自然非常广阔。可以预见,它将在多个领域催生新的解决方案。
- 智能教育:化身贴身的辅导助手,不仅能一步步引导学生解开数学难题,还能解析复杂的教育图表和文档,提供个性化的学习路径建议,真正提升学习效率。
- 智能办公:自动处理流转的文档、表格,甚至直接理解并操作软件界面(GUI),将人们从重复、繁琐的办公流程中解放出来,堪称效率提升的利器。
- 智能设备:让手机、电脑、智能家居等终端设备真正“听懂”和“看懂”用户的意图,实现更加自然、高效的多模态交互,大幅升级用户体验。
- 工业自动化:应用于工业视觉检测环节,进行精密的质量控制;或集成到机器人系统中,提升其感知与决策的智能化水平,推动智能制造升级。
- 智能客服:结合视觉与语言信息,不仅能回答文字问题,还能分析用户上传的图片或截图,提供更精准的客服支持和反馈分析,提升服务质量和效率。




