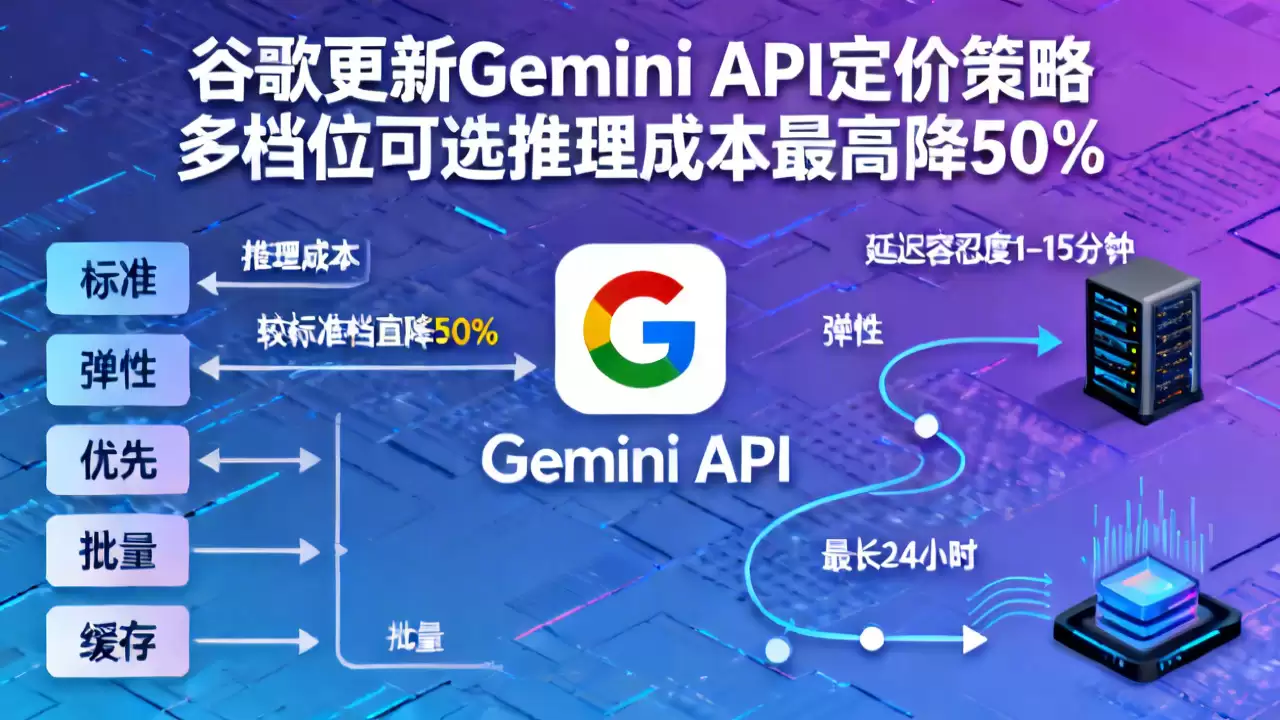
谷歌Gemini API发布全新定价策略:五大档位,成本最高直降50%
2026年4月3日,谷歌正式发布了Gemini API的全新定价策略,这事儿在开发者圈子里迅速传开。此次更新不再采用单一的“一刀切”计费模式,而是根据延迟需求和任务类型,细致地划分出了标准、弹性、优先、批量、缓存五大服务档位。其中最引人注目的是弹性与批量档位,推理成本相较标准档直接腰斩,降幅高达50%。这一下子,从需要毫秒级响应的实时应用,到能容忍1-15分钟甚至最长24小时延迟的离线处理任务,不同开发者多元化的算力需求,似乎都有了更具性价比的答案。
说实话,对于广大AI开发者而言,过去那种统一计费模式带来的成本浪费,一直是个“看得见却绕不开”的痛点。做实时交互类应用,为低延迟支付溢价合情合理;可对于那些处理离线批量数据的场景,明明不争分夺秒,却要承担与实时调用相同的费率,大量的预算就这么白白消耗在了不必要的性能指标上,想想确实让人心疼。
那么,谷歌这次亮出的五大档位,核心逻辑到底是什么?本质上,这是一次对算力资源的精细化拆分与重组。通过将不同优先级、不同响应速度的算力,精准匹配给不同需求的用户,谷歌试图在供需两端实现效率的最优解。其结果,是用户在满足业务需求的前提下显著降低了使用成本,而谷歌自身也提升了整体算力资源的利用率,可谓一举两得。
五大档位详解:如何按需选择?
这五大档位针对的业务场景差异明显,开发者完全可以对照自身业务的时效要求来“对号入座”。
弹性档位和批量档位是本次降价的“主力军”,都享受标准费率五折的优惠。两者的关键区别在于延迟容忍度的上限。弹性档位巧妙地利用了非高峰时段的闲置算力进行调度,其延迟会在1到15分钟内波动,非常适合批量内容生成、非实时的用户行为分析这类“快一点慢一点都行”的场景。而批量档位则更为“佛系”,最长延迟允许达到24小时,它瞄准的是大规模数据标注、多模态数据集预处理这类超大型离线任务。用户可以在完全没有时效压力的情况下,将推理成本直接砍半,何乐而不为?
除了两个折扣档位,其他档位也各有使命。标准档位自然是满足常规实时调用需求的主力,智能客服、实时搜索增强等主流应用场景依然是它的主场。优先档位则面向那些对稳定性和延迟有极致要求的企业级客户,通过算力预留提供确定性保障,金融实时风控、自动驾驶仿真等高优先级任务将是它的用武之地。值得一提的是缓存档位,它创新地改为按缓存词元数量和存储时长计费。这对于那些频繁调用相同系统提示词的对话机器人、需要对长视频进行反复分析的场景来说,简直是“福音”——它能有效避免对固定prompt进行重复计算的冗余成本。
行业趋势:从拼效果到拼服务与成本
当然,谷歌这次的动作并非孤例,而是全球大模型厂商加速商业化落地竞赛的一个缩影。此前,OpenAI就已经针对GPT系列API推出了批量调用折扣,而国内的深度求索公司(DeepSeek)也上线了类似的prompt缓存计费功能。整个行业的发展轨迹正在变得清晰:竞争焦点正从单纯地“拼模型效果”,快速转向“拼服务灵活性”和“拼成本控制能力”的新阶段。
对于开发者来说,精细化计费模式的普及无疑是一个重大利好。中小团队可以根据业务场景的实际情况,选择最匹配的档位,无需再为用不上的高性能支付额外溢价,这进一步降低了AI应用的创新和落地门槛。反过来看,对谷歌这样的厂商而言,分档定价不仅能盘活闲置的算力资源,还能覆盖更广泛的长尾非实时场景,从而不断扩大自身AI生态的覆盖范围与用户基础。
未来展望:更精细、更多元的算力服务
随着大模型应用向千行百业持续渗透,不同行业、不同场景对算力的需求差异只会越来越大。可以预见,未来大模型API的计费模式必将走向更加多元和精细。除了现在已经出现的按延迟分档、按缓存计费,未来按任务复杂度定价、为企业提供专属算力集群定制、根据业务峰值进行弹性扩容等差异化服务,大概率会陆续登上舞台。整个AI算力服务的供给方式,将越来越贴近用户真实、复杂的需求脉络,并最终推动大模型技术落地的整体成本持续下探,让更多想象成为可能。